







摘要
近年来,检索增强文本生成越来越受到计算语言学界的关注。与传统的生成模型相比,检索增强文本生成具有显著的优势,特别是在许多自然语言处理任务中取得了最先进的性能。本文旨在对检索增强型文本生成技术进行研究。首先重点介绍了检索增强生成的一般范式,然后根据不同的任务回顾了一些值得注意的方法,包括对话响应生成、机器翻译和其他生成任务。最后,在总结现有研究方法的基础上,指出了未来研究的发展方向
1 介绍
检索增强文本生成作为一种新的文本生成范式,融合了新兴的深度学习技术和传统的检索技术,在许多NLP任务中取得了最先进的(SOTA)性能,并引起了计算语言学界的关注(Weston等人,2018;Dinan et al., 2018;Cai et al., 2021)。与基于生成的模型相比,这种新范式具有显著的优势:
1)知识不需要隐式存储在模型参数中,而是以即插即用的方式显式获取,具有很大的可扩展性;
2)该范式不是从零开始生成文本,而是从一些检索到的人类书面参考中生成文本,这可能会减轻文本生成的难度。
本文旨在回顾检索增强文本生成任务的许多代表性方法,包括对话响应生成(Weston等人,2018)、机器翻译(Gu等人,2018)和其他方法(Hashimoto等人,2018)。
我们首先提出了检索增强生成的一般范式,以及该范式下的三个关键组成部分:检索源、检索度量和生成模型;
然后,我们介绍了一些值得注意的检索增强生成方法,这些方法是针对不同的任务进行组织的。具体而言,在对话响应生成任务中,范例/模板检索作为中间步骤已被证明有利于信息响应生成(Weston等人,2018;Wu et al., 2019;Cai et al., 2019a,b)。此外,人们对基于知识的生成越来越感兴趣,探索不同形式的知识,如知识库和外部文档(Dinan et al., 2018;Zhou et al., 2018;Lian et al., 2019;Li et al., 2019;秦等人,2019;Wu et al., 2021;Zhang等人,2021)。在机器翻译任务上,我们总结了早期关于如何使用检索到的句子(称为翻译记忆库)来改进统计机器翻译(SMT) (Koehn等人,2003)模型(Simard和Isabelle, 2009;Koehn and Senellart, 2010),我们特别强调了几种将翻译记忆库集成到NMT模型的流行方法(Gu et al., 2018;Zhang et al., 2018;Xu et al., 2020;He et al., 2021)。我们还回顾了检索增强生成在其他生成任务中的应用,如抽象摘要(Peng等人,2019)、代码生成(Hashimoto等人,2018)、释义(Kazemnejad等人,2020;Su et al., 2021b)和知识密集型生产(Lewis et al., 2020b)。最后,指出了检索增强生成的发展方向,以推动未来的研究。
Joint retrieval and generation training for grounded text generation 2021
A controllable model of grounded response generation. 2021
Generalization through Memorization: Nearest Neighbor Language Models 2020
Paraphrase Generation by Learning How to Edit from Samples. 2020
Keep the Primary, Rewrite the Secondary: A Two-Stage Approach for Paraphrase Generation 2021
Text generation with exemplar-based adaptive decoding. 2019
2 Retrieval-Augmented范式
在本节中,我们首先给出检索增强文本生成的一般公式。然后,我们讨论了检索增强生成范式的三个主要组成部分,检索源、检索度量和生成模型;
2.1 组成
大多数文本生成任务都可以表述为从输入序列x到输出序列的映射:y = f (x)。例如,x和y可以是对话历史和对应的对话响应生成,可以是源语言文本和机器翻译的目标语言翻译,等等。
最近,一些研究者建议通过一些信息检索技术赋予模型访问外部存储器的能力,使其能够在生成过程中获取更多的信息(Gu et al., 2018;Weston et al., 2018;Cai et al., 2019b)。检索增强代可进一步表示为:
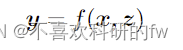
Retrieval-guided Dialogue Response Generation via a Matching-to-Generation Framework 2019
中z = {< xr, yr >}是从原始训练集或外部数据集检索到的相关实例集合。
该范例的主要思想是,如果xr(或yr)与输入x相似(或相关),则可能有利于响应生成。
值得注意的是,当使用无监督检索源时,xr =∅。
一般来说,检索记忆可以从三种来源中检索:训练语料库、与训练语料库格式相同的外部数据集和大规模无监督语料库(§2.2)。
评估文本之间相关性的指标也各不相同,在§2.3中我们将它们分为三类:稀疏向量检索、密集向量检索和基于训练的检索。
最后,如何将检索存储器集成到生成模型中也很重要,我们还在§2.4中介绍了一些流行的集成方法。
2.2 检索资源
训练语料库
以前的研究大多是从外部记忆的训练语料库中搜索外部记忆(Song et al., 2016;Gu et al., 2018;Weston et al., 2018)。在推理时间内,检索到的相关分数高的样本可以作为额外的参考,减少模型生成的不确定性。这些工作的主要动机是将知识不仅存储在模型参数中,而且以显式和可访问的形式存储,使模型能够在推理期间重新访问它。
外部数据
也有研究者提出从外部数据集中检索相关样本(Su et al., 2021c;肖等人,2021)。在这些研究中,检索池与训练语料库不同,它可以进一步提供训练语料库中不包含的额外信息。这对领域适应和知识更新等应用尤为有利。例如,Khandelwal等人(2020a);Zheng等(2021a)利用域内数据集作为外部存储器,实现了机器翻译的快速域自适应
无监督数据
前两个来源的一个限制是数据集必须是由对齐的输入输出对组成的监督数据集。对于机器翻译,Cai等人(2021)提出了一种跨语言检索器,可以直接从无监督语料库(即目标语言的单语语料库)中检索目标句子。其主要思想是在密集向量空间中对齐源端句子和相应的目标端翻译,即当xr不存在时对齐x和yr。结果,检索器直接将源端输入和目标端翻译之间的点连接起来,使目标语言中的单语数据能够单独用作记忆。
Improving language models by retrieving from trillions of tokens 2021
2.3 检索方法
稀疏矩阵检索
给定一个输入序列x和一个检索语料库,检索模型旨在从语料库中检索一组相关示例z ={< xr, yr >}。当使用有监督语料库时,通过测量x和xr之间的相似性来检索{< xr, yr >}。对于相似性度量,稀疏向量检索方法如TF-IDF和BM25 (Robertson and Zaragoza, 2009)被广泛使用。它们通过倒排索引有效地匹配关键字。
Dense-vector检索
然而,这些方法更喜欢具有相似表面的示例,并且可能无法检索仅在语义上相关的示例。为了缓解上述问题,一些研究(Cao and Xiong, 2018)尝试检索密集向量空间而不是词汇重叠。最近的工作(Lee等人,2019)使用了预训练的语言模型,该模型通过基于bert的编码器将文本编码为低维密集向量。通过向量间的内积计算检索分数
特定于任务的检索
基于相似性的检索是基于一个简单的启发式。也就是说,xr与x越相似,xr越有可能帮助这一代人。然而,最相似的通用文本相似度并不一定是最适合下游模型的。理想情况下,检索指标将以任务相关的方式从数据中学习:我们希望仅在它确实可以提高最终生成的质量时才考虑内存。为此,Cai et al.(2021)提出将记忆检索器及其下游生成模型统一为一个可学习的整体。这种记忆检索是针对特定任务目标进行端到端优化的。
2.4 整合
有几种方法可以将检索到的外部存储器集成到生成中。
一种直接的方法是数据增强,它通过将{< xr, yr >}的跨度与原始输入x连接来构建一些增强的输入。通过对增强的输入进行训练,生成模型隐式地学习如何集成检索到的信息。
尽管简单,但这种方法在许多任务中都能有效地工作(Song et al., 2016;Weston et al., 2018;Bulte和Tezcan, 2019)。
另一种整合方法是基于注意机制(Bahdanau et al., 2014)。这种方式的主要思想是采用额外的编码器(在各种架构中)对检索到的目标句子进行编码,并通过注意将它们整合(Cao and Xiong, 2018;Gu et al., 2018;Bapna and Firat, 2019)。因为注意机制正在变得(Bahdanau et al., 2014;Vaswani et al., 2017)是许多NLP模型中的关键模块,通过注意力整合检索到的记忆成为一种非常自然和有效的方式
骨架提取
在前两种方法中,下游生成模型学习如何隐式地从检索到的示例中过滤掉不相关甚至有害的信息。也有一些作品试图明确地从检索到的记忆中提取有用的信息,即骨架提取(Cai et al., 2019a;Wu et al., 2019;Cai et al., 2019b)。例如,一个骨架应该是整个话语的一部分,而不相关的内容被掩盖,生成模型在生成过程中只集成了这个骨架。
3对话
4 机器翻译
5 其他任务
除了对话系统和机器翻译之外,检索增强生成技术在许多其他任务中也显示出有益的作用。在下文中,我们将重点介绍应用检索增强生成方法的几个关键任务
摘要
文本摘要是另一个受益于检索增强文本生成的研究领域。Peng等人(2019)提出了一种自适应解码框架,该框架首先检索给定源文档的示例文档。然后,基于检索到的模板,通过自适应生成过程导出源文档的摘要。与Peng et al.(2019)不同,Cao et al.(2018)和Hossain et al.(2020)在发电管道中引入了一个中间的重新排序阶段。具体来说,在生成文档摘要之前,首先根据检索文档相对于源文档的相似度评分对它们进行重新排序。然后,通过重写所选模板生成文档摘要。
改写生成
为了解决释义生成缺乏质量和多样性的问题,Kazemnejad等人(2020)提出了一个生成框架,该框架首先检索与输入句子相似的句子。然后,基于检索到的句子,神经编辑器产生最终的释义句子。Chen等人(2019)研究了释义的另一个方面,即如何控制生成文本中显示的语言语法。为了实现这一目标,Chen等人(2019)建议首先提取一个句子样例作为语法模板。然后,神经模型根据检索到的范例生成具有所需语言语法的释义。
Paraphrase Generation by Learning How to Edit from Samples. 2020
A Hybrid Retrieval-Generation Neural Conversation Model 2019
数据到文本生成
近年来,检索增强生成已适应于数据到文本的生成任务。为了弥合结构化数据和自然语言文本之间的差距,Su等人(2021a)提出了一种新的检索增强框架。具体来说,给定源数据,首先从大型未标记语料库中检索一组候选文本。然后,使用神经选择器度量源数据和候选文本之间的相似性,并从候选文本中提取一组更细粒度的原型。最后,生成模型将原型作为输入,生成描述给定结构化数据的文本。
Few-Shot Table-to-Text Generation with Prototype Memory 2021
虽然检索增强生成已经在NLP社区得到了广泛的探索,但我们建议未来的研究可以将这种方法扩展到涉及多种模式数据的任务中。例如,随着图像-文本检索的最新进展(Jia et al., 2021;Radford et al., 2021),图像和文本之间的结构差距在很大程度上被弥合。一些早期研究(Zhang et al., 2020)表明,从图像中检索信息可以提高神经机器翻译模型的性能。当然,这种方法可以扩展到其他多模态任务,例如图像字幕(Karpathy和Li, 2015)。类似的想法也可以应用于图像以外的任务,例如语音到文本的转录(Gales和Young, 2007)。
6 未来方向
检索增强文本生成的性能对检索质量(即查询与检索样例之间的相似度)非常敏感。目前,检索增强文本生成模型在检索的示例与查询非常相似时表现良好。然而,当检索样本的相似度较低时,它们甚至比没有检索的生成模型更差。因此,开发新的方法来解决类似问题是很重要的















 7170
7170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









