










自动文档布局分析是认知计算和从文档图像中提取信息的过程中的关键步骤,如特定领域知识数据库创建、图形和图像理解、从表中提取结构化数据等。尽管在过去几年中在这一领域取得了进展,但挑战仍然存在,范围从准确检测内容框到将其分类为语义上有意义的类。
1. 动机(Motivation)
- 卷积神经网络(CNN)已被广泛应用于许多不同领域,用于各种目的。然而,在低内存和快速处理至关重要的文档存储和检索应用中,它们固有的非常高的计算负担通常限制了使用它们的成本效益。
- 使用投影识别图像块减少文档分析计算负担的方法,没有受益于使用一维卷积架构的 CNN 的鲁棒性。 这种场景为基于 CNN 的文档分析创新方法创造了许多机会,这些方法可以在不降低预期准确度的情况下降低计算成本和数据使用量。
2. 亮点(Highlights)
文章提出了新的一维CNN方法,用于快速自动检测结构化图像文档的布局。文章还实现了一个通用的二维CNN程序来比较性能,结果表明,快速一维体系结构使用一维投影以更少的数据使用和处理时间提供非常相似的结果。
3. 方法(Methodology)
文章为文档图像布局分析所提出的方法实现了一个pipeline,从文档图像分割成内容块到最终分类,如图1所示。以下小节详细描述了每个步骤。
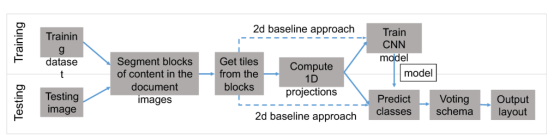
图1. 文章提出的文档图像布局分析方法的框图
3.1 分割文档图像中的内容块
步骤如下:
- 将原始图像转换成灰度图像(参见图2a)。
- 将步骤1中获得的结果,由[1]中描述的游程长度算法进行处理,以检测包含信息的可能性高的区域。该算法应用于水平和垂直方向,并使用运算符and组合生成的二值图像,如图2b所示。
- 对步骤2生成的二值图像执行两次3×3膨胀操作,以创建内容块,如图2c所示。
- 迭代检测二值图像中最大的连通分量,并将其表示为一个内容块。检测过程直到在图像中找不到更多连接的组件为止。最终结果的示例如图2d所示。

图2. 用于将页面分成内容块的pipeline。a)输入灰度页面。b)由游程长度算法产生的二值图像。c)由mask 3×3两次膨胀产生的二值图像。d)生成的内容块。
拓展:游程平滑算法[1]
- 游程平滑算法RLSA是借鉴于游程编码的一种版面分析前期处理方法。经过其处理后的版面图像被分成一个个子区域(将水平/垂直像素合并为线和区域),对这些区域的有效分类和合并时版面分割任务的关键。
- 具体思路:任意两个连续前景像素之间的背景像素的数目小于预定的阈值,则把图像背景转换为前景(涂抹前景像素)。
- 根据上述原理,版面分割的游程平滑算法的实现过程为:
- 在水平方向对原始图像进行平滑,当同一水平线上相邻的前景像素之间的背景像素小于给定的阈值,则将背景像素转换为前景像素,得到水平平滑图像,如图3中的Horizontal RLSA所示。垂直方向同理,得到Vertical RLSA。
- 将水平平滑图像(Horizontal RLSA)和垂直平滑图像(Vertical RLSA)做与运算。得到zone blocks。

图3. RLSA算法
3.2 对文档图像中的内容块进行分类
一旦文档图像被分割为内容块,文章使用CNN模型将其分为三个不同的类别:文本、表格和图像。文章实际实现了两种不同的CNN体系结构:一种常用于不同计算机视觉问题的二维方法,用作基线(baseline);文章提出的快速一维体系结构使用一维投影以更少的数据使用和处理时间提供非常相似的结果,如结果部分所示。
文章中使用的CNN体系结构受VGG体系结构的启发,由负责计算卷积特征的多个卷积层组成,然后是多个完全连接的层,这些层对特征进行分类,并为每个感兴趣的类别生成概率。
3.2.1 使用基于二维CNN的baseline分类
对于二维基线,文章实现了一种体系结构,该体系结构接收二维图像块作为输入,并使用三个二维卷积层序列(带有50个过滤器和ReLu激活)对其进行处理;然后使用50个节点的完全连接层和3个节点的完全连接层以及softmax激活(三类分类)评估卷积特征。在该模型中,每个二维卷积层后面都有MaxPooling层,它有2个像素内核和一个0.1dropout用于正则化。两个完全连接的层之间也存在0.3dropout,以便更好的模型泛化。所有实验中使用的卷积内核大小为3x3像素,图4中描述了该架构的模式。

图 4. CNN 模型架构:二维基线和提出的一维方法
3.2.2 文章提出的方法:基于CNN的快速一维分类
在文章的方法中,提出了一种一维CNN架构,该架构使用图像块垂直和水平投影来对内容块进行分类。
如图5所示,文本、表格和图像块对于此类投影具有非常不同且高度区分的特征:
- 由于文本行的原因,文本块在垂直投影中通常具有方形信号状形状,而在水平投影中具有大致恒定的信号状形状;
- 表格块在垂直投影中也有一个方形信号形状,但在水平投影中也有一个大致的方形信号形状,这是由于列组织的原因;
- 图形在水平和垂直投影中都没有任何特殊图案。
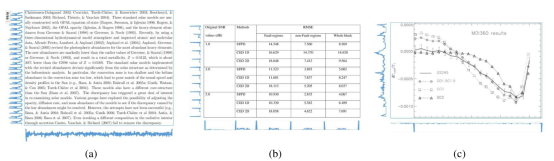
图5. 文本、表格和图像内容块及其相应的垂直和水平投影(蓝色)的示例:(a)文本;(b)表格;©表格。
每个投影由一个独立的卷积轨迹进行处理,该轨迹由三个1D卷积层序列组成,每个1D卷积层具有50个滤波器,并且ReLu激活。每个轨迹的输出被连接并提交到一个完全连接的层,其中50个节点连接到一个3节点完全连接的层,并通过softmax激活三类分类。在该模型中,每个一维卷积层之后是一个MaxPooling层,其核大小为2个像素,和一个0.1dropout用于正则化。与二维模型类似,为了更好地泛化,在两个完全连接的层之间有0.3的dropout。在所有实验中使用的卷积核大小为3x1像素,架构如图4所示。
需要注意的是,文章在基线和一维体系结构中使用了相同数量的层、过滤器和内核大小,因此可以评估降低分析维度的影响,而不是模型中的参数差异。
4. 实验设计(Experimental Design)
4.1 Data
为了运行实验,文章从 ArXiv 论文中构建了一个数据库,过滤了最后 300 份在摘要中包含“地震”一词的文档。 地震关键字的使用与本文范围之外的原因有关,作者相信结果对于不同领域的论文会相似,并且不会损失概括性。
如第3.1节所述,作者将文档分为内容块。并根据其内容手动将其分类为文本、表格或图形。该过程衍生出一个由99个表块、2995个图像块和4533个文本块组成的带注释的数据库。
4.2训练和测试程序
为了处理这个非常不平衡的数据库并强调CNN模型,作者决定对数据库进行子采样和平衡,以训练CNN模型,创建一个由每个类90个随机选择的块组成的数据库。文章使用每100像素100像素的滑动窗口采样进行数据扩充,步长为30。这一过程衍生出一个训练数据库,每个类大约有6092块100x100像素块,总共执行18278个样本。该数据集进一步分为80%用于训练(其中20%用于验证),20%用于测试模型分类精度。在第5节中展示了这些结果。
一旦模型经过训练,文章就会根据整个不平衡的数据库对它们进行评估。 在这个测试中,文章评估的不是 100x100 像素图块,而是完整的内容分类块,为此使用了一个简单的投票模式。 对于每个内容块,作者使用上面相同的滑动窗口模式提取了几个图块,并针对训练过的模型对它们进行了评估。 给定内容块的最终分类是通过使用块中的所有图块计算最高平均类别概率来获得的,这模仿了概率加权投票模式。 然后,作者将带注释的参考与实验的结果进行比较,并将结果编译到混淆矩阵(误差矩阵)中,如第 5节所示。
拓展:混淆矩阵

5. 结果和讨论
为了公平地比较文章提出的方法和实施的二维基线,作者使用了完全相同的训练参数:30 个训练时期(足以在文章所提的实验中训练收敛)、50 个样本的小批量并仅保存最佳训练模型。在这里作者报告文章的第一个结果:训练过程在二维基线方法中花费了 823.82 秒,但在提出的一维方法中只花费了 126.92 秒,快了 6.5 倍。 两种模型的训练均使用 NVidia Tesla K80 GPU 进行。
对于经过训练的模型,作者首先评估了它们在 100x100 tiles(图块)分类中的表现。 回顾第 4.2 节,作者从总共 18278 个样本中分离出 20% 的图块进行测试,对应于 3656 个样本或每类大约 1218 个样本。 评价结果以混淆矩阵的形式如表1所示。 值得注意的是,两种模型都具有良好且相似的性能:二维基线的总体准确率达到了 96.8%,而文章所提出的方法达到了 96.6%。 将维度从二维patches(块)减少到一维投影并没有影响实验中的整体精度。
表1. 混淆矩阵显示了二维基线和一维方法的tiles性能
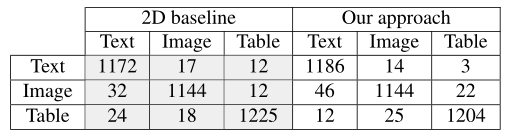
2D 准确度 = (1172 + 1144 + 1225) / (1172 + 17 + 12 + 32 + 1144 + 12 + 24 +18 + 1225) = 96.8%
Our 准确度 = (1186 + 1144 + 1204) / (1186 + 14 + 3 + 46 + 1144 + 22 + 12 + 25 + 1204) = 96.6%
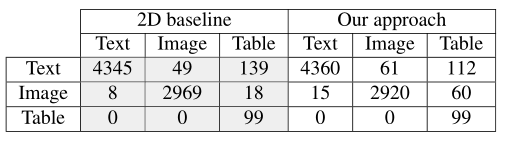
文章还评估了这两个模型对完整内容分类块的执行情况。 在这个实验中,文章使用了整个不平衡数据集,包括 99 个表格块、2995 个图像块和 4533 个文本块。 如第 4.2 节所述,作者计算了该blocks(区块:完整块)中所有tiles(块)的每个类别的概率,并选择了对应于最高平均概率的类别,类似于概率加权投票模式。 文章所提出方法的结果显示在表 2 中,再次使用混淆矩阵。 可以注意到两个模型都表现良好:二维基线的总体准确率达到了 97.19%,而文章所提出的方法达到了 96.75%。 在实验中,将维度从 2D 块减少到 1D 投影似乎对整体精度没有非常显着的影响。
表2. 混淆矩阵显示了二维基线和一维方法的完整块(blocks)性能
为了突出使用所提出的一维方法的优势,文章还评估了评估新文档图像的处理时间。 为此,还计算了对给定页面的内容块进行分类所花费的处理时间,并将结果显示在表 3 中,其中文章的方法比文章测试的基线二维方法快 7.8 倍,几乎没有损失准确性。
表3. 使用二维基线和一维方法对每页内容块进行分类的处理时间

最后,为了完整性,文章还使用提出的方法在图 5 布局中显示了整页分类的结果。 可以看到灰色的文本块,黄色的图像和蓝色的表格,结果与目测一致。

图5. 使用文章的方法获得的结果与视觉检查一致:五页中的块被正确分割并分类为文本、图像和表格。
5.2 文章提出的方法和最新技术
文章还将结果与最先进的结果进行了比较。 这里值得一提的是,尽管使用公开文件来评估文章的方法,并实施了一个基线进行公平比较,但所有方法中使用的数据并不相同,因此应谨慎看待。使用相同数据集的文档图像分析方法的比较并不简单,因为有些是付费的(UW-III),有些在他们的主页上不可用(ICDAR-2009),或者没有文章内置数据库(MediaTeam)的相同类型的文档(学术论文)。 尽管如此,由于对文本和图像块进行分类的挑战具有许多前提,我们看到了在这种情况下比较作品的价值,并将它们编译在表 4 中,结果与此处介绍的最先进方法相当。 还值得一提的是,表格块的结果不包括在内,因为其他比较方法不处理此类。
表 4. 与其他方法的比较:我们的方法在文献中通常处理的类中取得了良好的结果。
5.3 详细说明文章实验中的错误
在对文章的结果进行评估的过程中,作者在错误中发现了一些有趣的模式。如图6所示,错误通常与公式的存在有关,公式被标注为文本,但始终被归类为图像;内容分割块问题;或手动注释中的错误(尤其是注释为文本的表格)。
- 与公式相关的错误(见图 6a)理论上可以通过向文章的模型添加一个新的公式类来修复,但这将涉及重新注释数据,作者在这项工作中还没有这样做。
- 关于块分割的问题,作者注意到有时文章中用来分割块的算法会将不同的块合并在一起,如图6b所示,这会导致块分类错误。
- 一个有趣的现象与有关手动数据库注释的错误有关,如图 6c 所示。 在这种情况下,模型实际上对块进行了正确分类,并且可以用于优化数据库,这是一个积极的方面。

图 6. 在文章的方法中发现的最常见的错误: (a) 注释为文本并分类为图像的公式; (b) 注释为文本并分类为图像的块分割问题; (c) 人工标注错误:图标注为文本分类为图像,表格标注为文本分类为表格。
6. 结论
本文提出了一种基于 CNN 的快速文档图像布局分析方法。 在我们的方法中,我们首先对文档图像中的内容块进行分割,然后将它们分成几个图块并计算它们的水平和垂直投影,这些投影由一维 CNN 模型共同使用,将它们分类为文本、表格和图片。 然后,图块分类结果结合了一个简单的投票模式,该模式定义了文档图像中每个内容块的最终类别。
为了评估我们的模型,我们使用来自 ArXiv 网站的公开可用文档构建了一个数据库,我们在摘要中过滤了最后 300 份文档。 我们按照第 3.1 节中的描述对文档页面进行分割,并手动将各个内容块分类为文本、表格或图形。 这个过程导出了一个由 99 个表格块、2995 个图像块和 4533 个文本块组成的带注释的数据库,通过我们的实验使用。
我们的模型是根据我们使用与我们的方法非常相似的架构实现的基于二维 CNN 的基线方法进行评估的,这使我们能够评估降低模型性能维度的影响。 我们的结果表明,我们的方法实现了在二维基线中观察到的相同精度,但相应的数据使用量要低得多(从 100x100=10M 像素到 2x100=200 像素,少 50 倍)和处理时间(大约快 7.8 倍) 文档页面评估)。 这些结果可能对移动应用程序或基于云的服务有用。
进一步的研究将包括为内容分类块包括其他语义类并处理不同类型的文档,例如历史文档。
References
[1]K. Y . Wong, R. G. Casey, and F. M. Wahl. Document analysis system.IBM journal of research and development,26(6):647–656, 1982.















 1321
1321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









