







PSP分割网络:Pyramid Scene Parsing Network
Scene ~= Semantic Segmentation
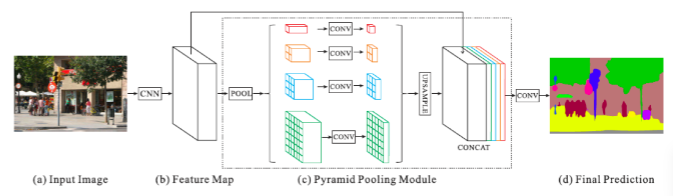
Ⅰ. FCN的缺点:
- 分割结果不够精细
- 没有考虑上下文信息(左顾右盼)
Ⅱ. PSP网络 —— Context Information
1. 缺少上下文信息表现:
- 图中的boat区域和类别"car"的appearance相似
- 模型只有local信息,boat容易被识别成"car"
- confusion categories:building and skyscraper
2. 上下文信息:
- 利用全局信息(global information)
- 全局信息 in CNN ~= feature/pyramid
如下图所示:
- 如果只有local(局部)信息,船很容易被认成是车,
- 但是如果考虑上下文信息(左顾右盼),根据周围信息(利用全局global信息),例如上边是森林,旁边是水,则推断为船。

3. 如何获取上下文信息:
增大感受野(Receptive Field)
- 什么是感受野(RF):
感受野 = 用于产生特征的输入图像中的区域大小,如图所示- Layer2绿色pixel由Layer1的9个pixel计算而来,也就是说layer2中的绿色pixel在layer1当中只能看到这9个pixel,所有Layer2绿色pixel在Layer1的感受野为9)
- 跨层感受野:layer3的黄色pixel,可以看到Layer2的9个pixel,而Layer2的9个pixel能够看到Layer1的所有6×6的pixel,也就是Layer3黄色pixel在Layer1上的感受野就是全局。
只针对局部操作:例如conv,pooling

实际图
例如右边图片车上的pixel(红色点),我们希望分类为car
- 但是它在原图上可以看到信息是有限的,假设为绿框,我们不能分辨出来是什么
- 如果它在原图看到的是黄色框,我们就可以分辨出来,是car
所以我们要做的事情,就是通过网络(或者通过某种设计),把原来的感受野(绿色框),通过网络变大(黄色框),多看点信息,这就是PSP网络设计的原则。

4. PSP怎么增大感受野
Pyramid Pooling Module
- 简而言之:多尺度
- 具体操作:adaptive_average_pool
feature 图:

步骤:
- 将64×64 C维的feature map 分别变成1×1×C、2×2×C、3×3×C、6×6×C的feature map(固定尺寸,1 2 3 6是人为指定的)。主要运用adaptive pooling(x, (1×1))、adaptive pooling(x, (2×2))…
- 对1×1×C、2×2×C、3×3×C、6×6×C的feature map降维成1×1×C/4、2×2×C/4、3×3×C/4、6×6×C/4的feature map。主要运用Conv1×1。
- 对1×1×C/4、2×2×C/4、3×3×C/4、6×6×C/4的feature map做Upsample操作,将feature map变回和原图的feature map一样大小 64×64×C/4
- 把4个64×64×C/4以及原图的concat起来,做一个特征融合操作(fusion)。
其中:
1×1×C的感受野对应原图的全局
2×2×C的每一个像素能看到的感受野对应原图的16个像素
3×3×C的每一个像素能看到的感受野对应原图的7个像素
6×6×C的每一个像素能看到的感受野对应原图的2个像素
操作图:

扩展:Adaptive pool(size k)和1×1卷积的区别
- Adaptive pool(size k):改变的是HW,channel不变
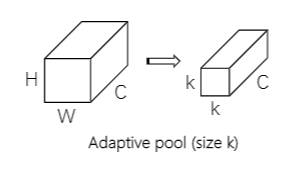
- 1×1卷积:改变的是channel大小,HW不变

扩展:Adaptive pool(size k)操作
在一定区域中做pooling,输出我们需要的维度
像素点对应原图的卷积区域的计算公式:

其中
h
s
t
a
r
t
h_{start}
hstart 和
h
e
n
d
h_{end}
hend用来算要在原图卷哪个区域。i为行,j为列,i,j为输出维度所对应的位置。(并不一定是完整的3×3)
如下图,原图输入为8×8,期望输出为5×3,计算v(0,1)原图卷积的区域:

对于i:
h
s
t
a
r
t
=
f
l
o
o
r
(
0
∗
8
/
5
)
=
0
h_{start}=floor(0*8/5)=0
hstart=floor(0∗8/5)=0
h
e
n
d
=
f
l
o
o
r
(
1
∗
8
/
5
)
=
f
l
o
o
r
(
1.6
)
=
1
h_{end}=floor(1*8/5)=floor(1.6)=1
hend=floor(1∗8/5)=floor(1.6)=1
对于j:
h
s
t
a
r
t
=
f
l
o
o
r
(
1
∗
8
/
3
)
=
f
l
o
o
r
(
2.6
)
=
2
h_{start}=floor(1*8/3)=floor(2.6)=2
hstart=floor(1∗8/3)=floor(2.6)=2
h
e
n
d
=
f
l
o
o
r
(
2
∗
8
/
3
)
=
f
l
o
o
r
(
5.3
)
=
5
h_{end}=floor(2*8/3)=floor(5.3)=5
hend=floor(2∗8/3)=floor(5.3)=5
5. 总结 PSPNet


6. PSPNet代码
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph import to_variable
from paddle.fluid.dygraph import Layer
from paddle.fluid.dygraph import Conv2D
from paddle.fluid.dygraph import BatchNorm
from paddle.fluid.dygraph import Dropout
from resnet_dilated import ResNet50
# pool with different bin_size
# interpolation back to input size
# concat
class PSPModule(Layer):
def __init__(self, num_channels, bin_size_list):
super(PSPModule, self).__init__()
self.bin_size_list = bin_size_list
num_filters = num_channels // len(bin_size_list) # channel除以4:C/4
self.features = []
for i in range(len(bin_size_list)):
self.features.append(
fluid.dygraph.Sequential(
Conv2D(num_channels=num_channels, num_filters= num_filters, filter_size=1), # 1×1×C/4、2×2×C/4、3×3×C/4、6×6×C/4
BatchNorm(num_filters, act='relu')
)
)
def forward(self, inputs):
out = [inputs]
for idx, f in enumerate(self.features):
x = fluid.layers.adaptive_pool2d(inputs, self.bin_size_list[idx]) # 1×1×C、2×2×C、3×3×C、6×6×C
x = f(x) # 1×1×C/4、2×2×C/4、3×3×C/4、6×6×C/4
x = fluid.layers.interpolate(x, inputs.shape[2::], align_corners=True) # 64×64×C/4、64×64×C/4、64×64×C/4、64×64×C/4
out.append(x) # C/4 * 4 + C = 2*C
# out is list
out = fluid.layers.concat(out, axis=1) # NCHW
return out
class PSPNet(Layer):
def __init__(self, num_classes=59, backbone='resnet50'):
super(PSPNet, self).__init__()
res = ResNet50(pretrained=False)
# stem : res.conv, res.pool2d_max
self.layer0 = fluid.dygraph.Sequential(
res.conv,
res.pool2d_max
)
self.layer1 = res.layer1
self.layer2 = res.layer2
self.layer3 = res.layer3
self.layer4 = res.layer4
num_channels = 2048 # resnet50 layer4的输出channel
# psp : 2048 -> 2048*2
self.pspmodule = PSPModule(num_channels, [1, 2, 3, 6])
num_channels = num_channels * 2 # concat后的channel
# cls : 2048*2 -> 512 -> num_classes
self.classifier = fluid.dygraph.Sequential(
Conv2D(num_channels=num_channels, num_filters=512, filter_size=3, padding=1),
BatchNorm(num_channels=512, act='relu'),
Dropout(0.1),
Conv2D(num_channels=512, num_filters=num_classes, filter_size=1)
)
# aux : 1024 -> 256 -> num_classes
# 从中间某一层单独拉出来一个feature map也做一个分类,帮助计算loss
def forward(self, inputs):
x = self.layer0(inputs)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.pspmodule(x)
x = self.classifier(x)
x = fluid.layers.interpolate(x, inputs.shape[2::], align_corners=True) # inputs.shape[2::] 就是2 3
return x
# aux : tmp_x = layer3
def main():
with fluid.dygraph.guard(fluid.CPUPlace()):
x_data = np.random.rand(2, 3, 473, 473).astype(np.float32)
x = to_variable(x_data)
model = PSPNet(num_classes=59)
model.train()
pred, aux = model(x)
print('pred shape:', pred.shape, 'aux shape:',aux.shape)
if __name__ == '__main__':
main()
pred shape: [59, 473, 473] aux shape: [59, 473, 473]















 1402
1402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









