









主题
- Optical and other advanced chiplet interconnect technologies
- Interconnect standards of coherent and non-coherent data sharing protocols (e.g. CXL)
- Disaggregated computing architectures powered by high speed interconnect
- Chiplet architectures for in-memory computing and other emerging technologies
- Software optimization and scheduling with fast inter-chiplet network
- Power evaluation and performance modeling of chiplet architectures
芯片架构议题
Challenges in AI and ML for Chiplets to address
Speaker:Dharmesh Jani (Infrastructure Partnerships/Ecosystems Lead @ Meta)
通常的人类行为场景
- 认知,认识世界并构建认知模型,需要大量的训练
- 挖掘,在各种类型的数据中寻找目标,需要推理
- 综合创造,创造出新的事物
当前AI应用领域及相关算法应用
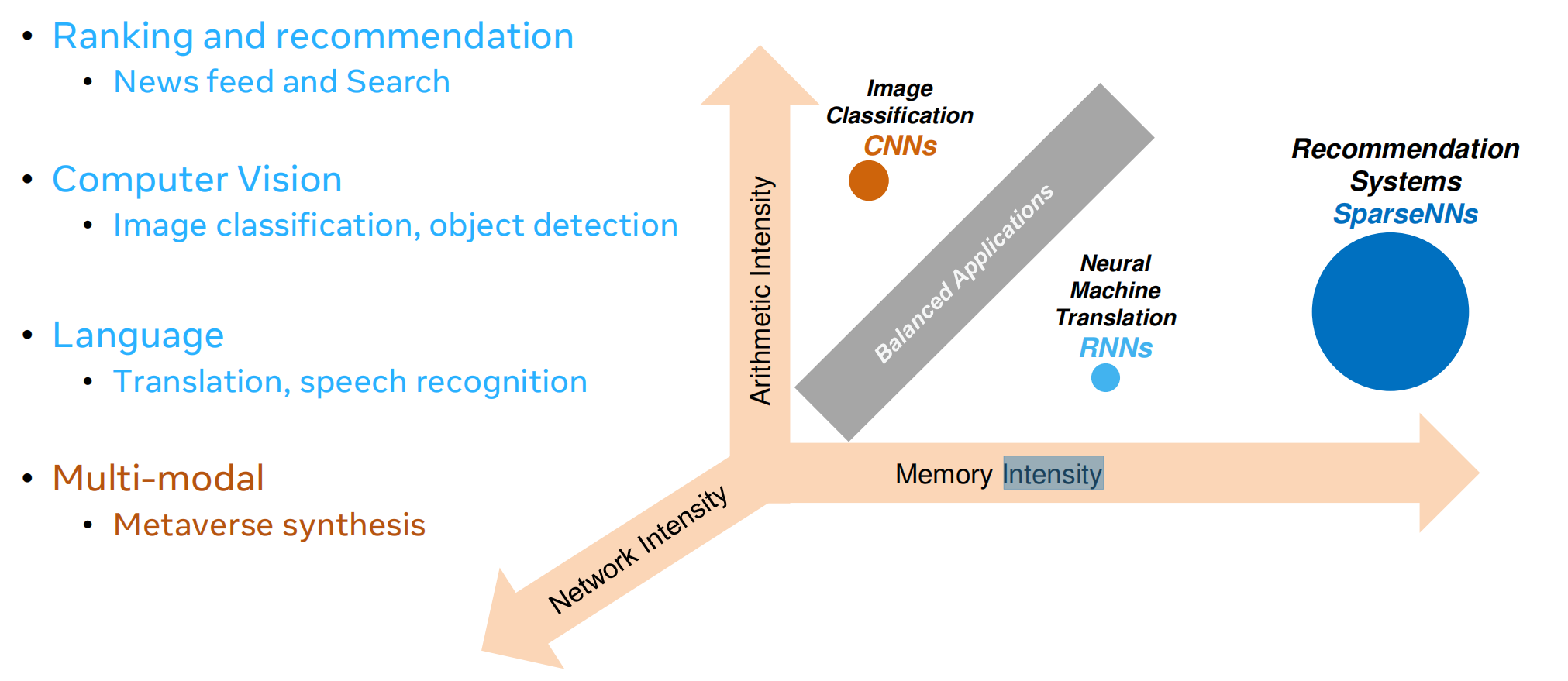
当前DSA处理器存在算力瓶颈
内存和互联网络拖累了计算。
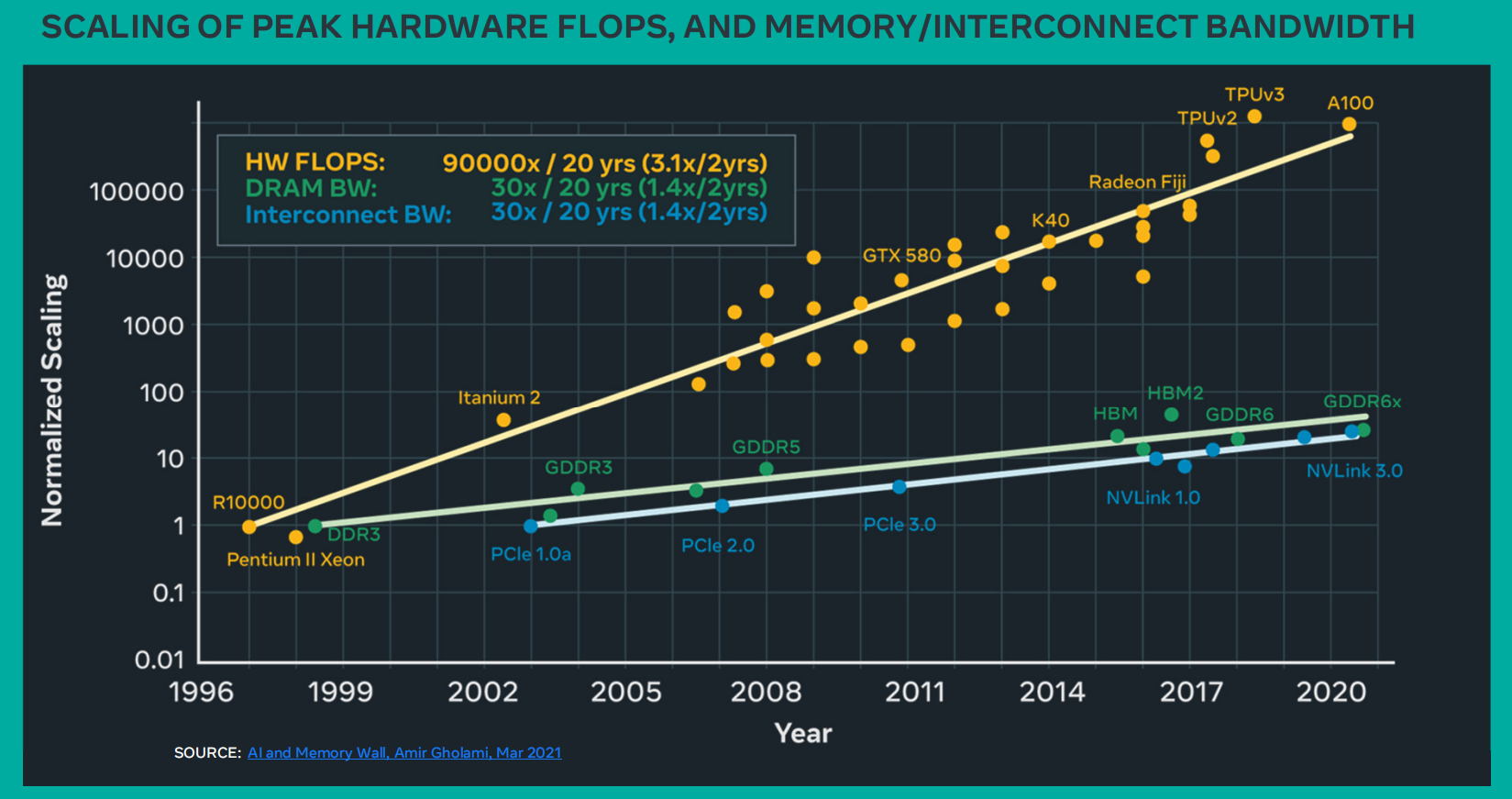
- 评
Chiplet技术需要去解决的人工智能和机器学习的挑战。该报告针对人类行为包括认知、挖掘、创造三个场景指出了DSA的运行需求,并指出了其挑战主要在加速器和内存间的缺口、软硬件的协同设计、互联网络中如何选通局部带宽以优化总体带宽
Enable Polymorphic AI Architecture via Composable Chiplet Technologies
Speaker: Weifeng Zhang (Chief Architect & VP of Software Lightelligence)
- 评
通过可模组的chiplet技术构建多模态的AI架构。
A Scalable Methodology for Designing Efficient Interconnection Network of Chiplets
Speaker: Yinxiao Feng, Dong Xiang, Kaisheng Ma. (@ Tsinghua University)
当前多chiplet架构可扩展性特征
平面拓扑、长直径、有限的可扩展性
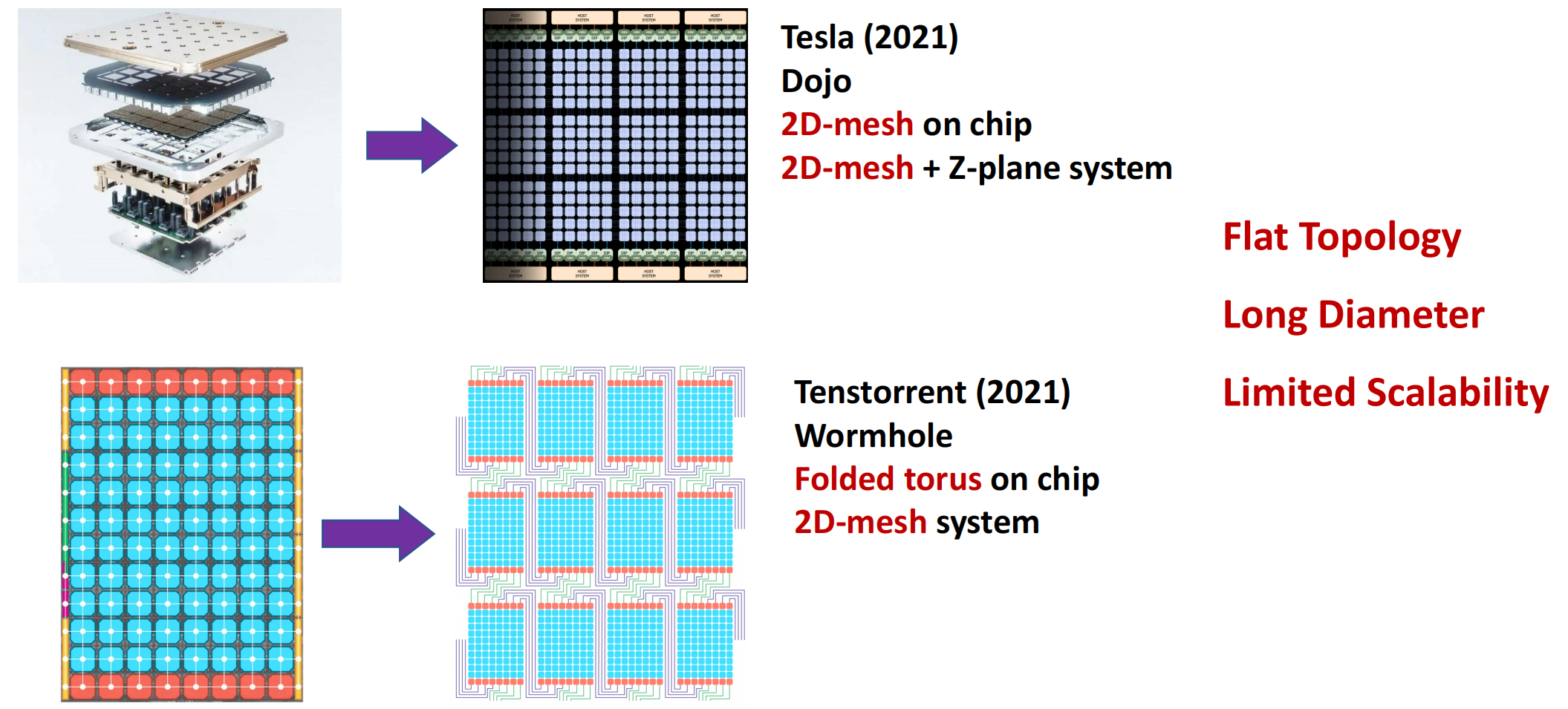
拓扑架构的问题
种种问题导致互联网络的性能较差,不能充分发挥chiplet架构的性能。
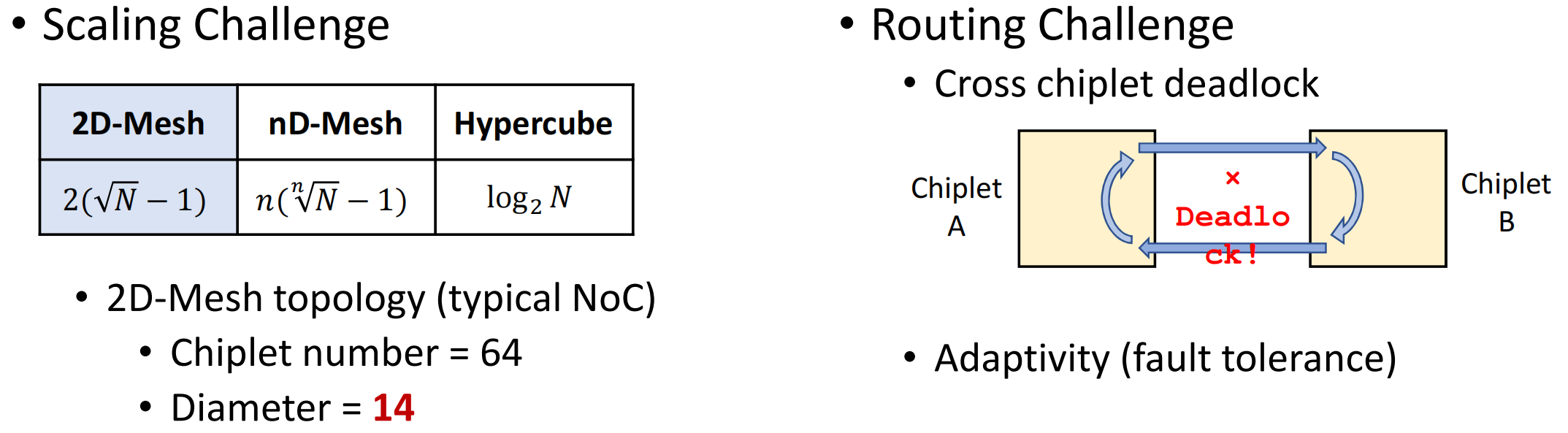
- 规模挑战:chiplet数量越多,直径越大
- 布线挑战:跨chiplet死锁,较差的容忍度
理想的拓扑架构
- 能使用相同的chiplet构建不同的规模的系统级架构
- chiplet基于2D mesh架构
- 可扩展
- 通过自适应路由算法解决死锁问题
- 有效的
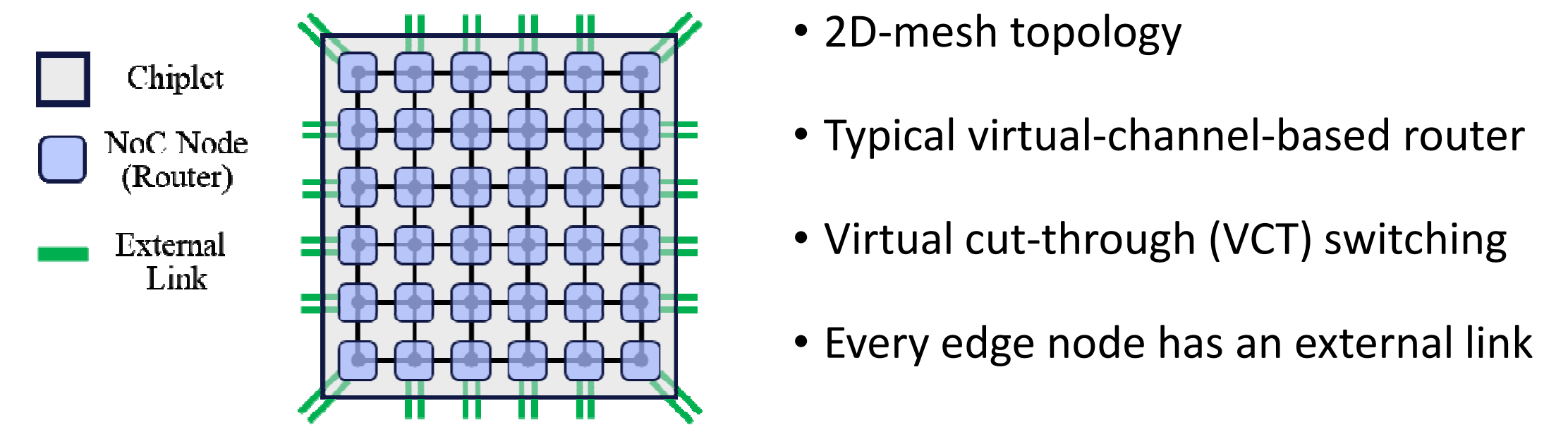
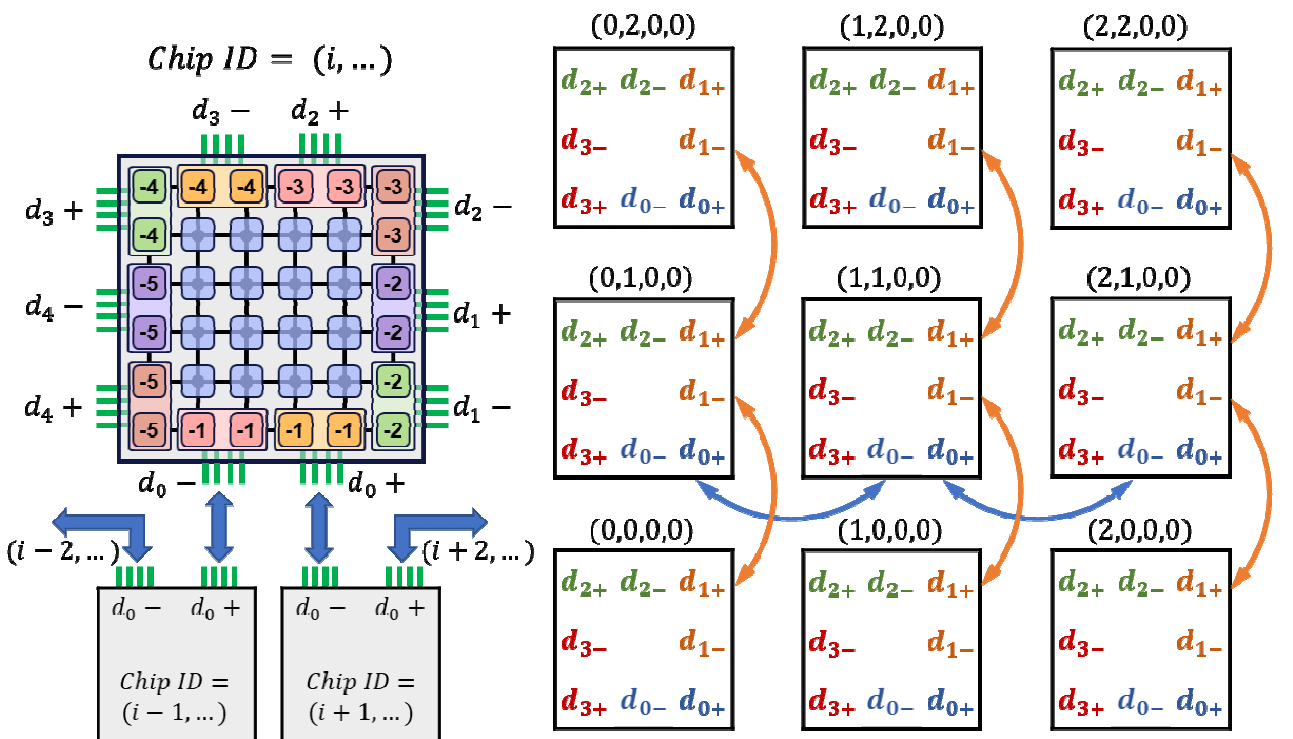
清华大学团队基于传统的2D mesh NoC架构提出了修改最小的解决方案:
- 虚拟通道路由器
- 虚拟直通
- 每个边缘节点都有一个外部连接链路
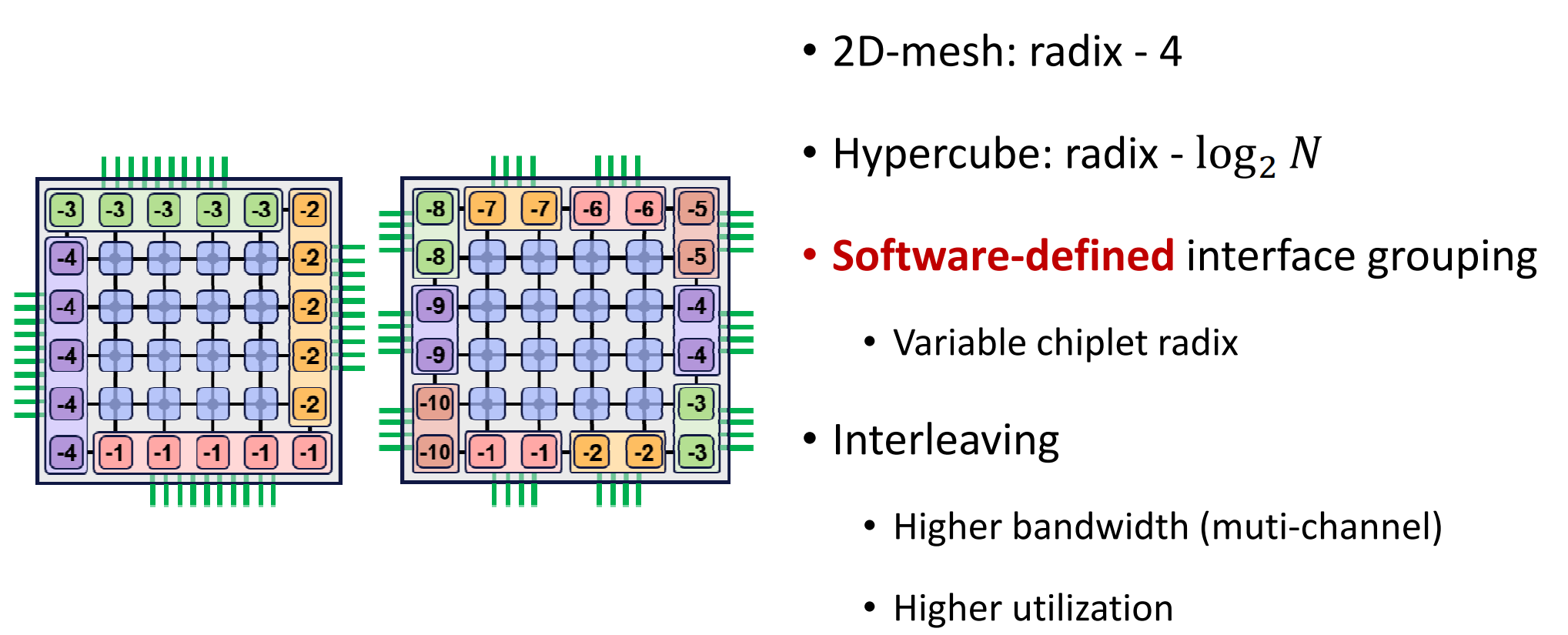
评估方法
- 补充: radix:阶,指网络中一个点的与其他点的连接数量
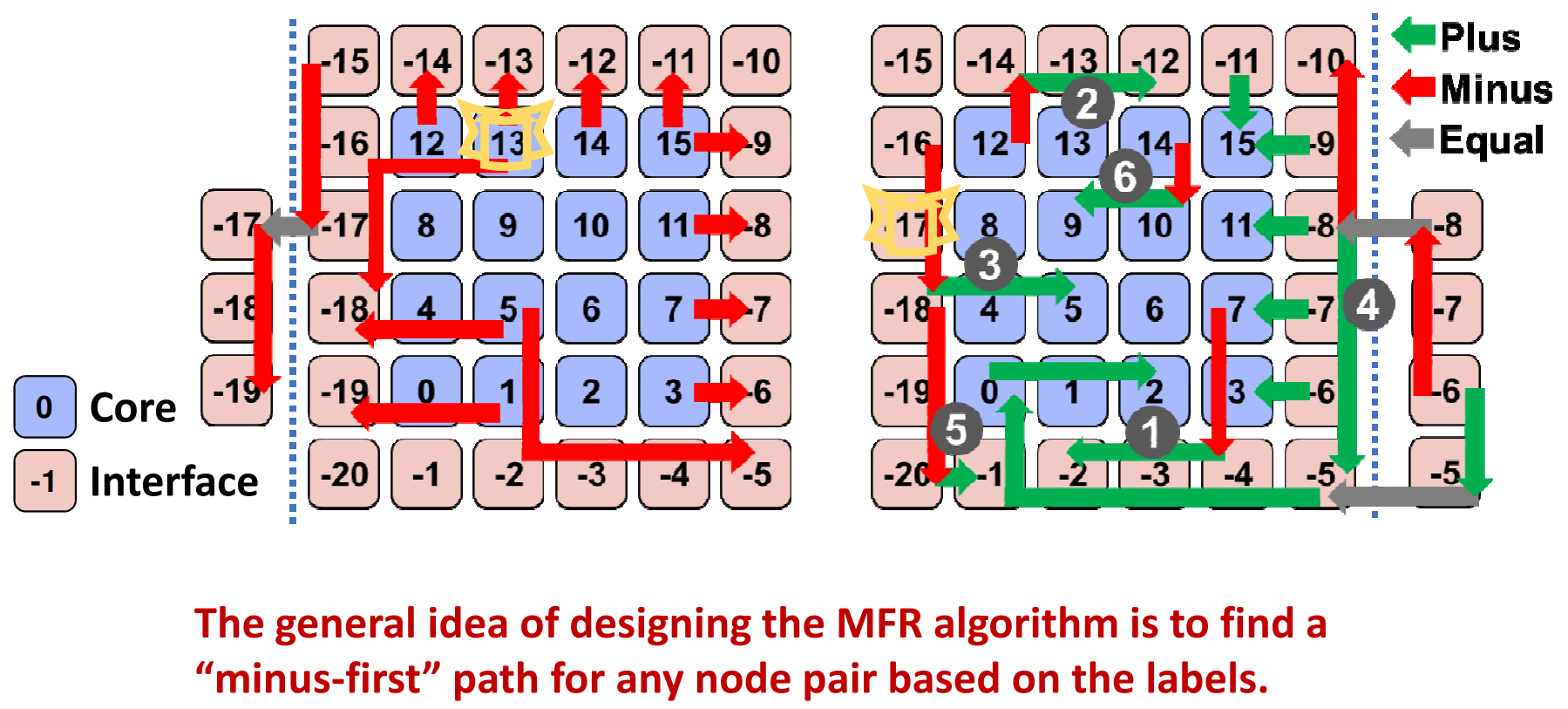
- MFR
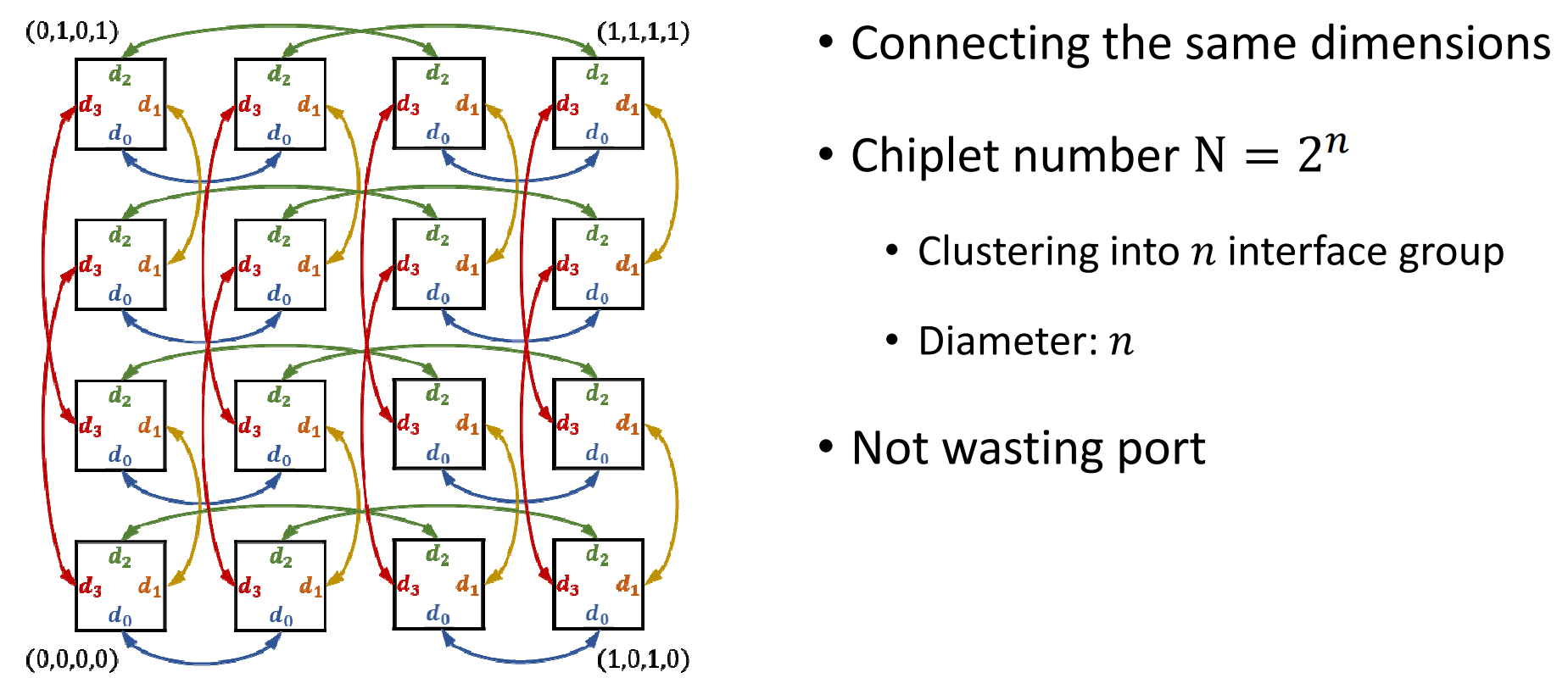
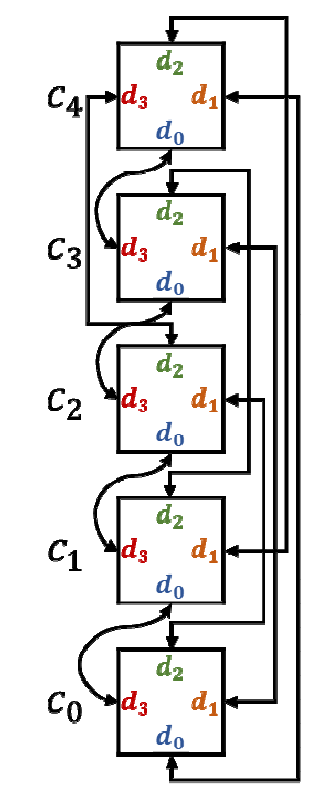
几种互联拓扑架构
- 超立方体
- nD-mesh
- 蝴蝶网络
延迟达Cycle精度的C++仿真器

- 评
一种可扩展的用于设计高效chiplet互联网络的方法学。本报告定义了一个软件可定义的接口汇集方法,描述了将2D mesh NoC架构的chiplet转变成高阶network的方法,并基于MFR(Minus-first Routing)设计了一种解除死锁的自适应算法,在chiplet特定的能达到延迟的cycle精度的C++仿真器上评估了性能,结果表示了改方法学的高性能和灵活性
Building Heterogeneous Chiplets with AMBA Interconnects
Speaker: Jeff Defilippi ( Senior Director Product Management @ ARM)
当前chiplet生态处于各家为战阶段
NVIDIA Grace Hopper Superchip通过CHI将CPU和GPU die 进行连接

- 900 GB/s NVIDIA-CTC interconnect
- 使用共享页表的虚拟内存系统
- 系统内存能效比服务器接GPU提升了30倍
片上一致性协议总线CHI

新的CHI协议将支持Multi-chip
新的CHI协议正在开发,扩充的新的特征将使CHI从on-chip扩展到multi-chip,具有如下特征:
- 计算节点、加速器节点、内存节点的统一的一致性互联接口
- 将如下特征延伸到chiplet边界
- 分布式的虚拟内存管理、中断、定时器
- 监测和资源管理
- 信任安全、内存保护、加密计算

如图所示为IP的层次架构,协议层使用CHI协议,链路层和物理层使用UCIe或其他IP。

- 评
使用AMBA总线构建异步chiplet架构。该报告揭示了chiplet技术应用的迫切需求,介绍了ARM的CHI总线特征,并基于原先on-chip特征的基础上扩展应用于multi-chip的属性,基于CHI的chiplet互联将推动chiplet行业向半定制平台发展
芯片封装议题
Next-generation Co-Packaged Optics for Future Disaggregated AI Systems
Speaker: Sajjad Moazeni, Assistant Professor (University of Washington, Seattle)
CPO的目标
基于AMD和Nvidia的应用情况,CPO可以实现功耗、成本、密度、线距的最优平衡。
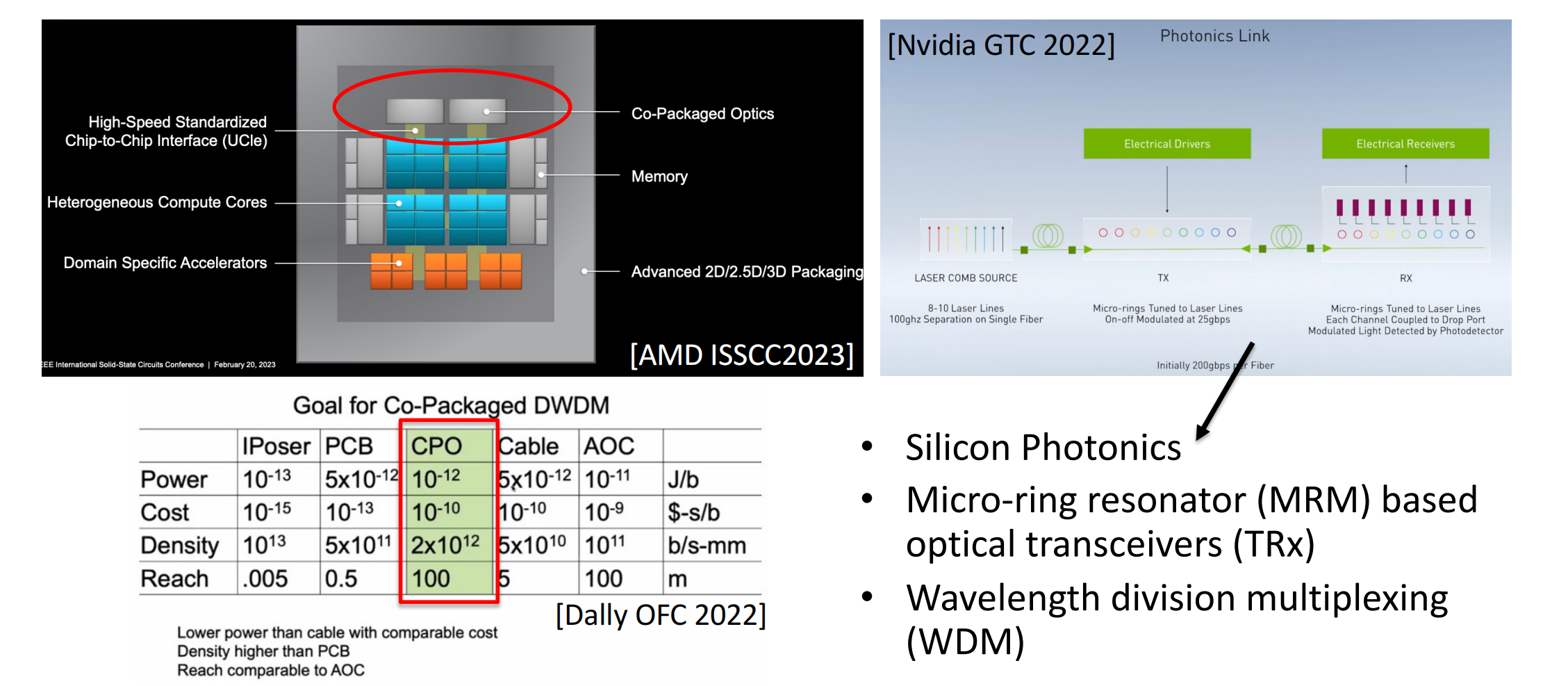
使用微环调制器(micro-ring modulator, MRM)进行光通信
详细介绍了技术细节
下一代CPO结束解决方案
- 在先进封装中使用direct bonding替代micro-bumps
- PIC和EIC联合设计
- 架构的更新
和内存控制器连接的CPO
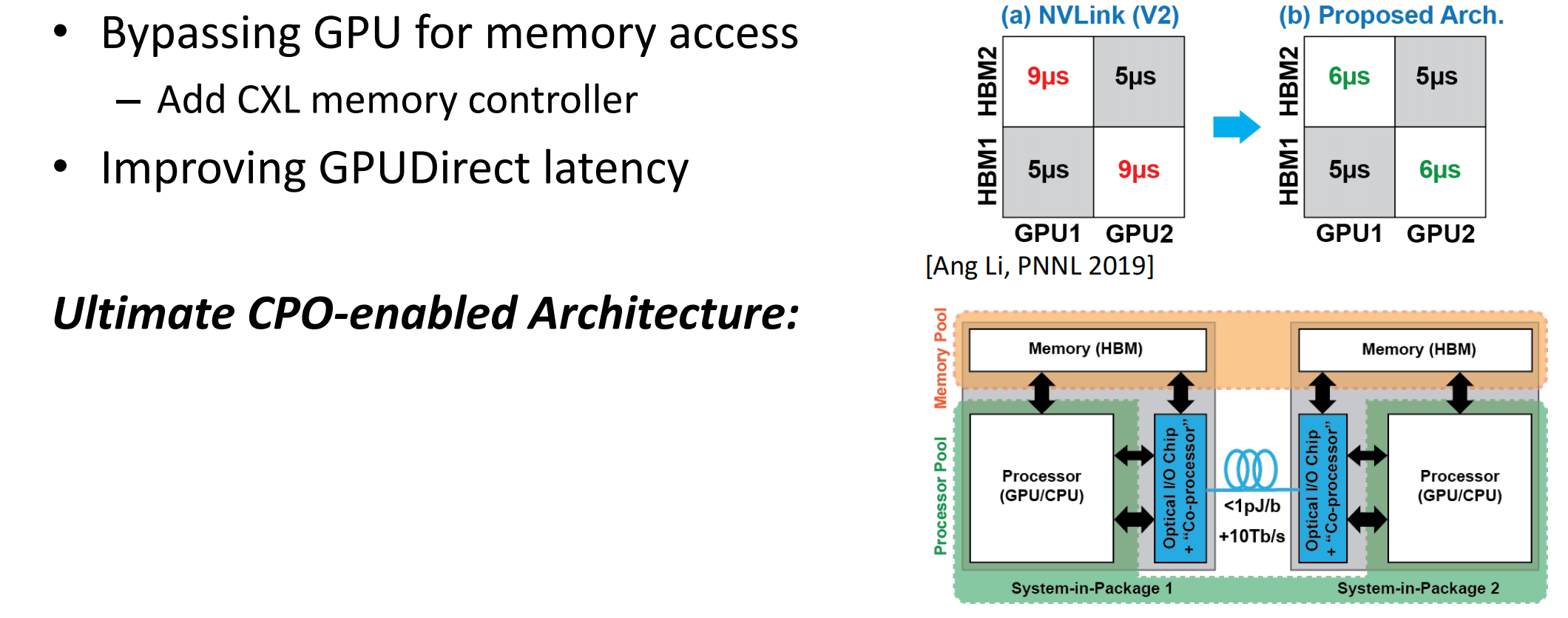
相关研究
H. Li et al., “A 3-D-Integrated Silicon Photonic Microring-Based 112-Gb/s PAM-4 Transmitter With Nonlinear Equalization and Thermal Control,” in IEEE Journal of Solid-State Circuits, vol. 56, no. 1, pp. 19-29, Jan. 2021, doi: 10.1109/JSSC.2020.3022851. 论文解析
- 评
针对未来分离AI系统的下一代合封装光学。该报告介绍了Intel在CPO方面的工作,并详细介绍了MRM的技术细节,并提出了随着PIC和EIC的CPO集成的实现,很多新的芯片架构将被解锁,例如将PIC和HBM互联等。
Optical Network-on-Chip for Large Scale Chiplet Architectures
Speaker: Huaiyu Meng (Co-founder and CTO @ LIGHTELLIGENCE)
通过PIC将EIC进行信道互联
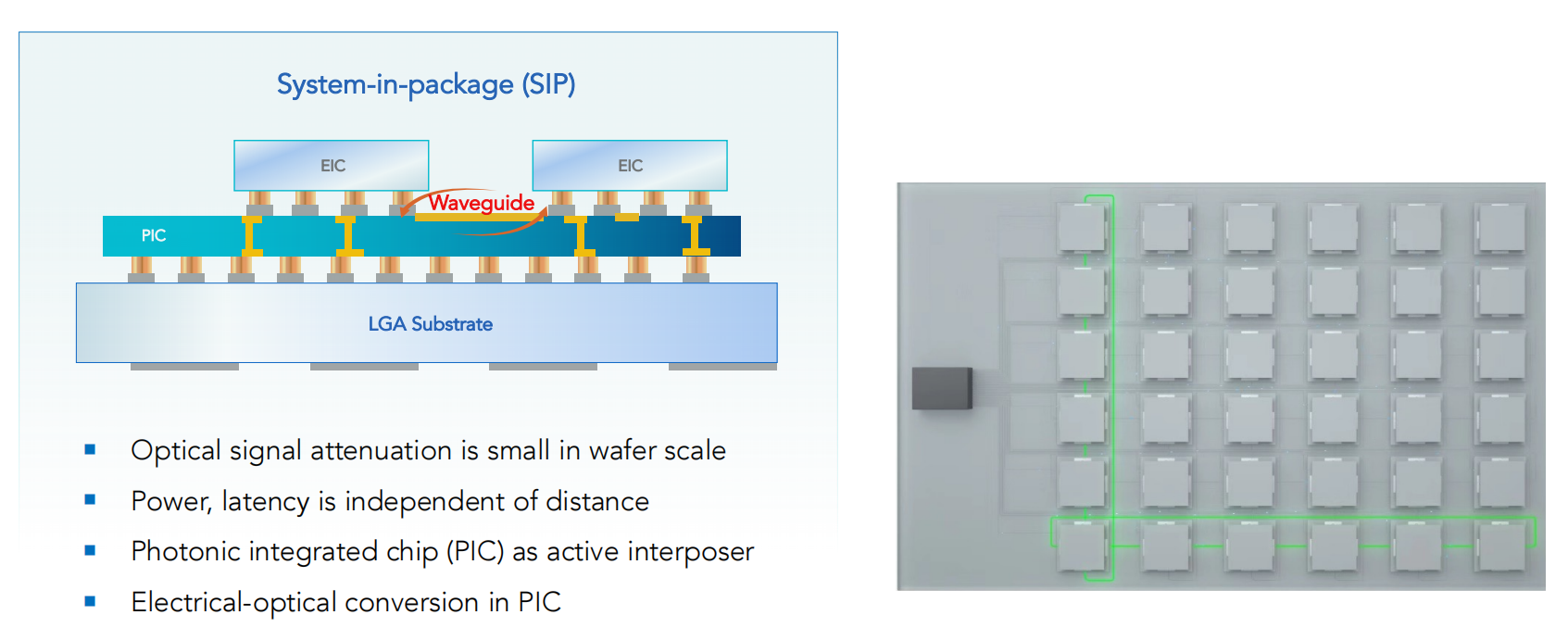
- chiplet间互联不在局限于相邻chiplet
- 在wafer级的信号衰减更小
- 功耗和延迟将和die间距无关
oNOC的优势
- 由于延迟减小,不同的拓扑架构变得可能
- 由于灵活的网络拓扑,工作负载在硬件上的映射更加有效
- 距离与MCM计算系统性能提升成近线性关系

采用oNOC的第一代计算系统级封装

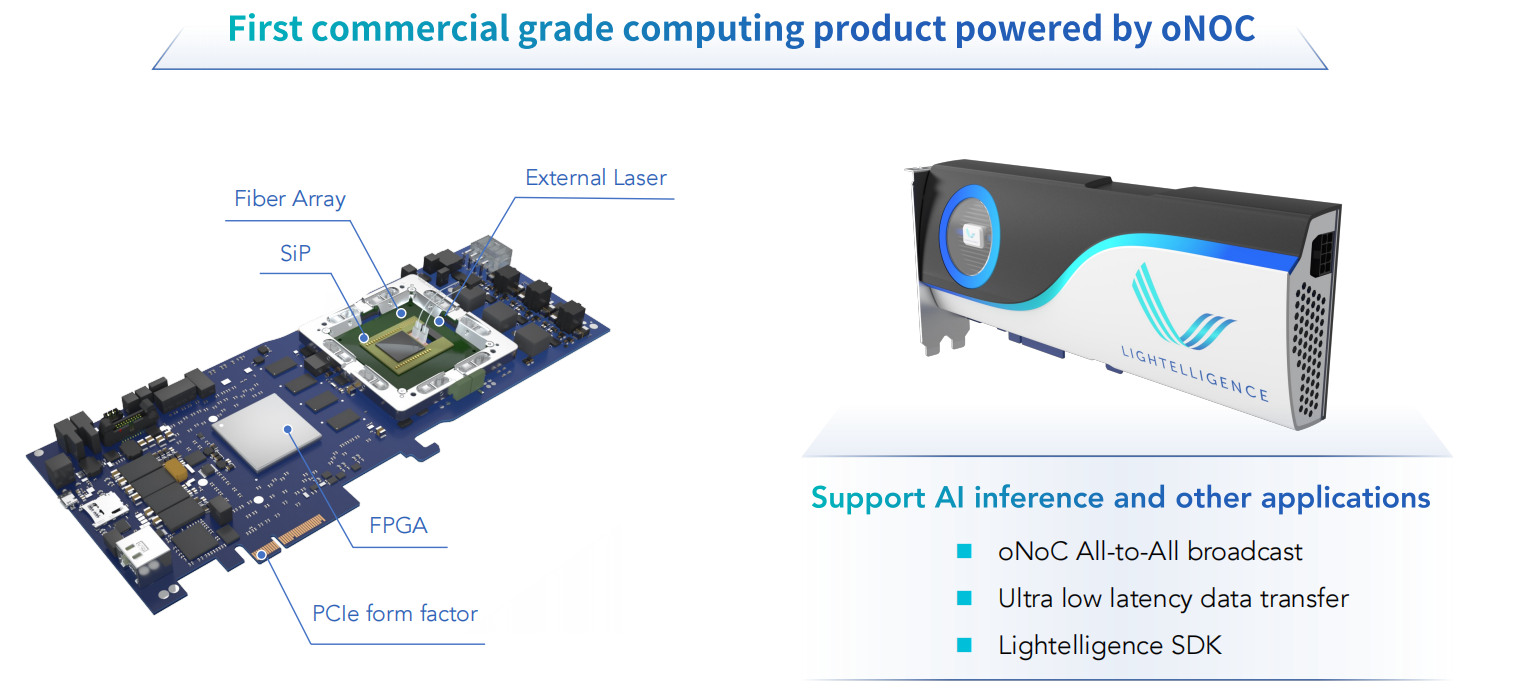
oNOC大规模应用的挑战
- chiplet生态不够成熟
- chiplet间标准接口
- 硅基光芯片的成本较高
- 评
应用于大规模Chiplet架构的光互联片上网络。该报告揭示了当前基于电子通信的chiplet互联的局限性,考虑多各种优异的互联架构,可使用oNOC技术在2D的基板空间上进行3D互联(鄙人理解非物理上的3D互联,而是延迟等效意义上的互联),如此,优秀的架构将会带来工作负载上的性能提升。介绍了第一代oNOC产品,并提出了oNOC技术大规模应用的担忧。
技术生态
Building an Open Chiplet Economy
Speaker: Cliff Grossner (Ph.D. VP Market Intelligence & Innovation), Bapi Vinnakota (Ph.D., Open Compute Project)
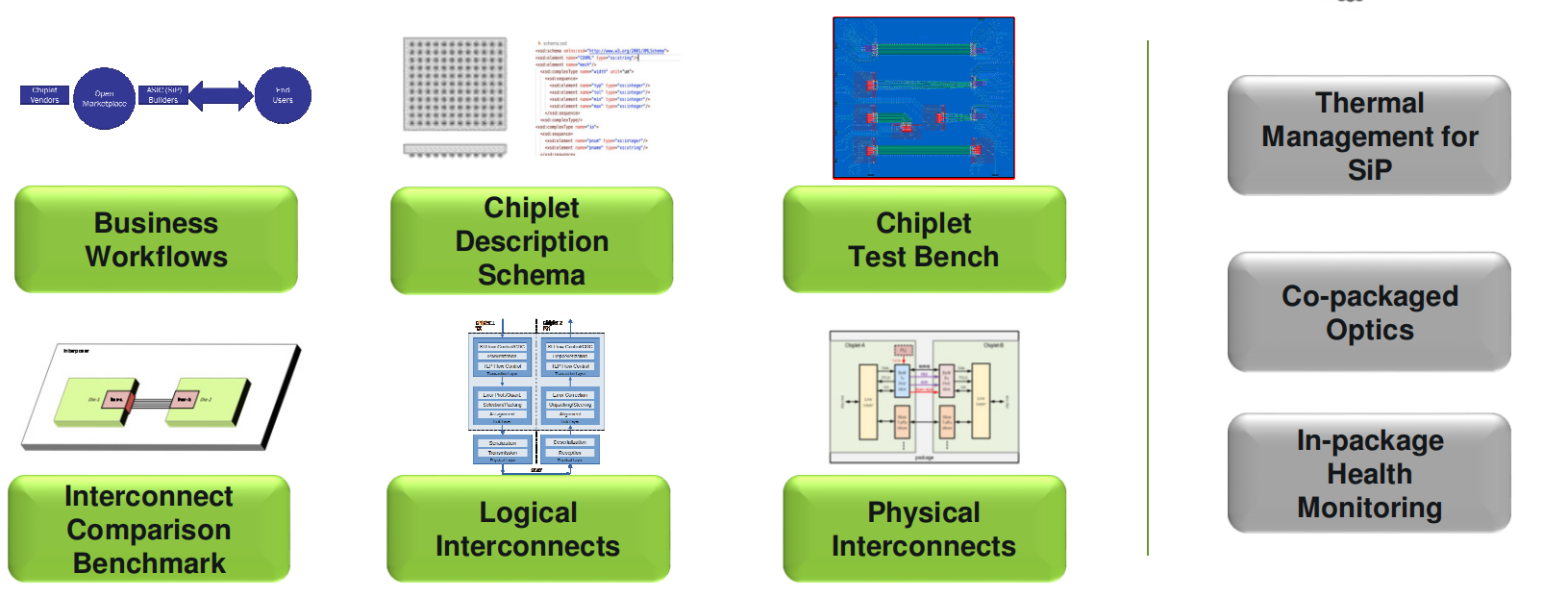
新的chiplet开放经济生态
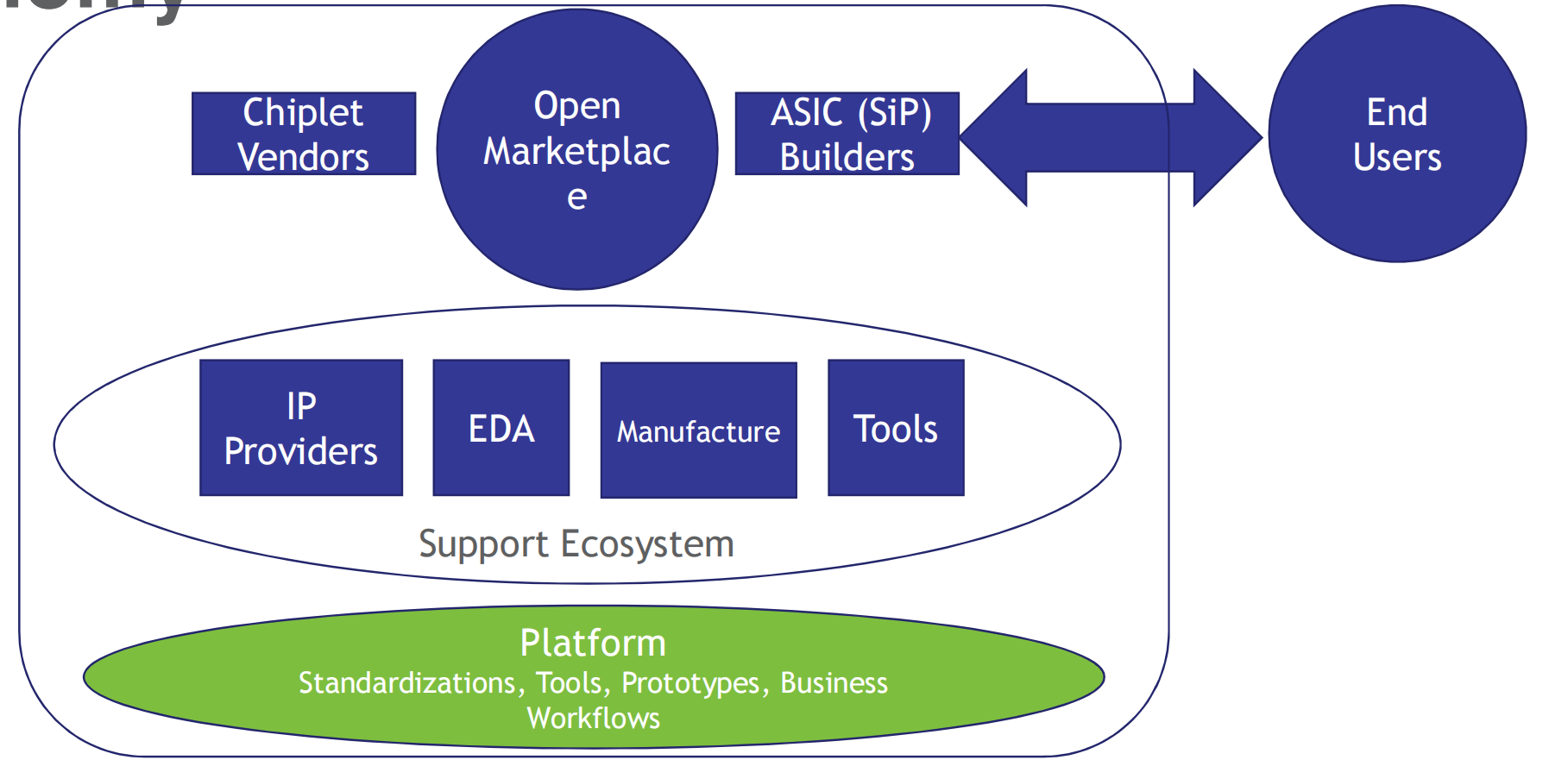
需要考虑的要素
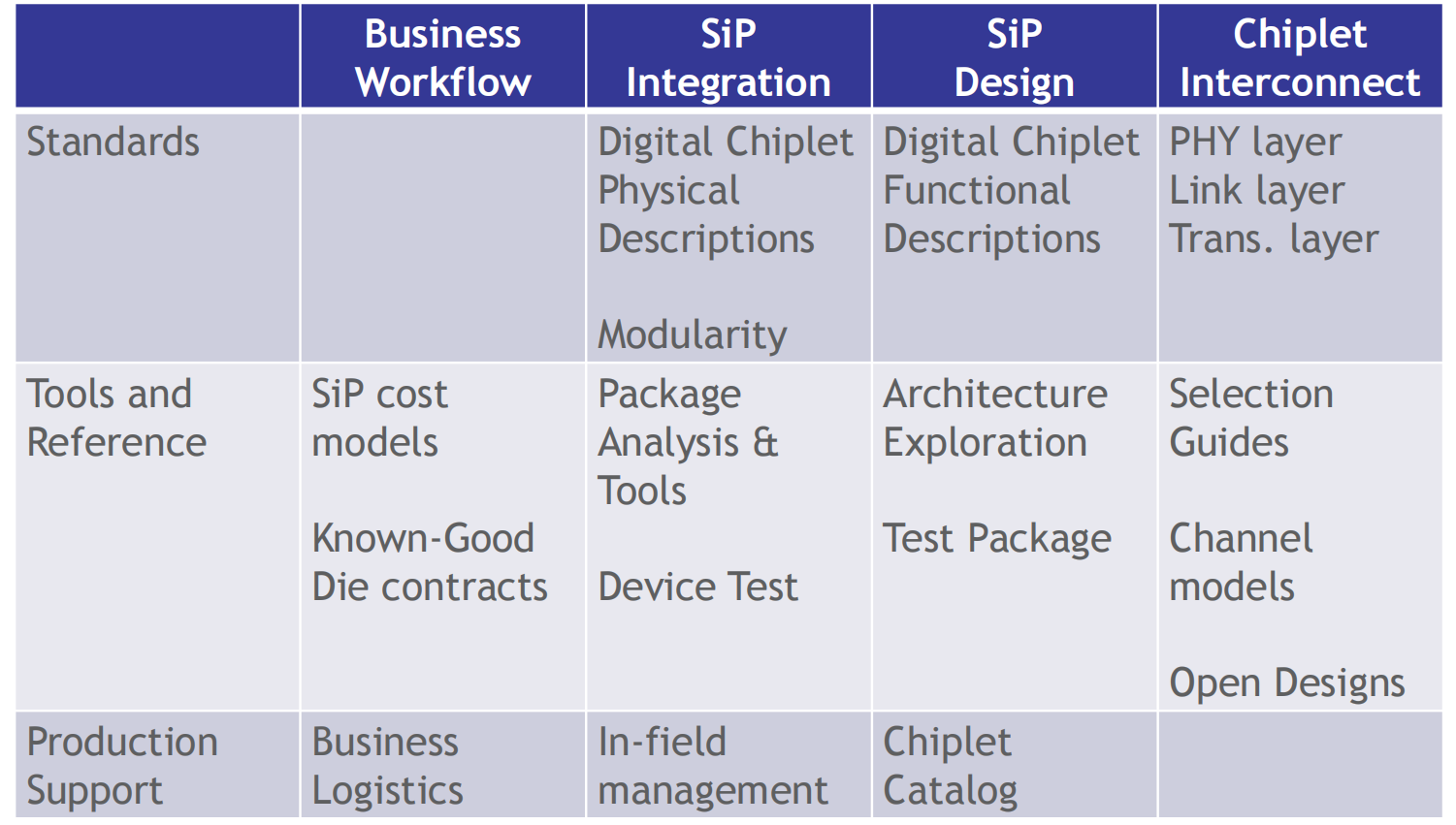
OCP致力于构建开放chiplet生态的投资
BoW的相关案例和应用

标准化的商业工作流和商业关系

chiplet设计描述使SiP设计和构建更加自动化
chiplet经济需要:
- 标准化的设计模型,来确保EDA工作流程
- 标准化的SiP设计和集成工作流
- 对2.5D、3D封装的多chiplet的SiP集成方法
- 电气化的可读性描述应包括如下属性:

实现高可操作性和第三方验证的标准化的chiplet testbench

标准的互联比较基准使能知情权
关键准则:
- 每个单元的成本
- 运行成本
- 设计影响
- 产品集成
- 封装成本
标准化逻辑互联使物理层连接可替换
主要优势:
- 简化,专注于die的拆分,缓解了CDR、CRC/retry设计的复杂度
- 低延迟,更加激进的技术,使用FEC缓解CRC的串行时序负荷
- 可规模化,支持不同的lane数据传输速率和划分
- 可便携化,接口可以兼容不同的实现方法和工艺节点
- 可扩展性,创造一个模块框架,允许增加新的特征、允许定制化、使能互联的可操作性
BoW技术是一个将AXI协议迁移到chiplet互联的自然而然的选择
- 为最大化实用性优化了标准
- 设计者可以选择满足用户案例的操作点
- 简化所需特征的实现方法
- 每个逻辑单元(16 lane)都可以用于所有类型封装
- 对通道损耗和串扰,错误率的一致性没有直接要求
- 在chiplet层指定信号序,而不是明确的bump maps
- 规模化应用的关键属性
- 成本和能效 (0.25 -0.5pJ/bit)
- 在较宽范围 (65nm – 5nm)节点内的高性能 (2-16Gb/s/line)
- 使用场景 (25mm reach, <1e-15 BER)
- 正在构建中的BoW-384 (24Gb/s/line) 和 BoW-512 (32Gb/s/line)
- 评
构建开放的chiplet经济。该报告是OCP组织关于chiplet生态的报告,在功耗、性能、成本、商务等不同需求下,chiplets将存在于生活的各领域中,同时为chiplet经济生态提出了包括技术和生态的关键着力点。
UCIe :An open standard for innovations at package level
chiplet互联的技术要点
包括SoC应用层的设计、数据链路层和事务层的设计、物理层的设计等
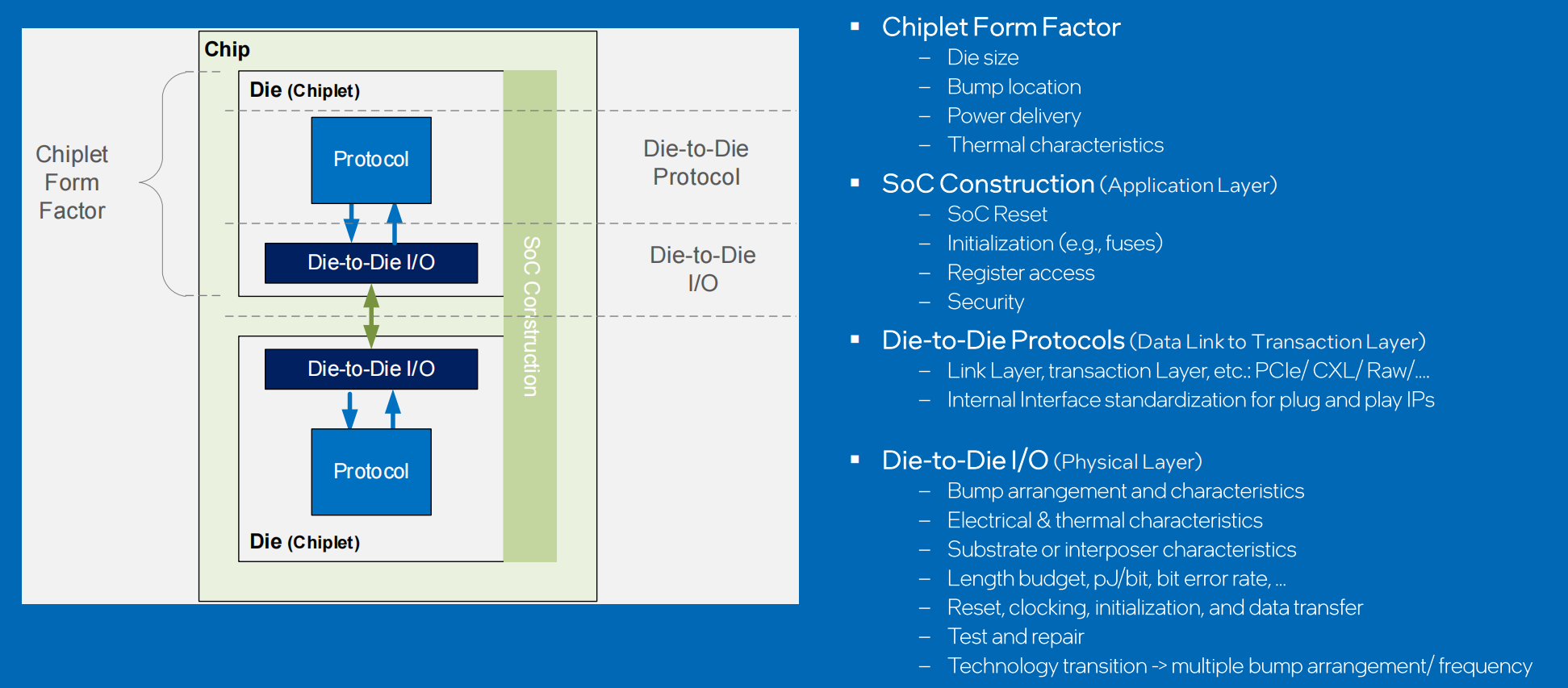
- 评
UCIe,一个在封装层级创新的开放的标准,介绍了当代推动chiplet技术发展的因素,描述了chiplet技术要解决的问题,以及UCIe优秀的技术属性。
Chiplet Ecosystem: Challenges and obstacles to overcome to reach chiplet nirvana
Speaker: Nathan Kalyanasundharam & John Wuu ( @ AMD )
AMD需要DSA来满足计算需求
- 不同类型的计算
- 来自不通供应商的不同chiplet
- 集成多种类型的计算、存储、IO的系统级封装
- 减少开发成本和上市时间
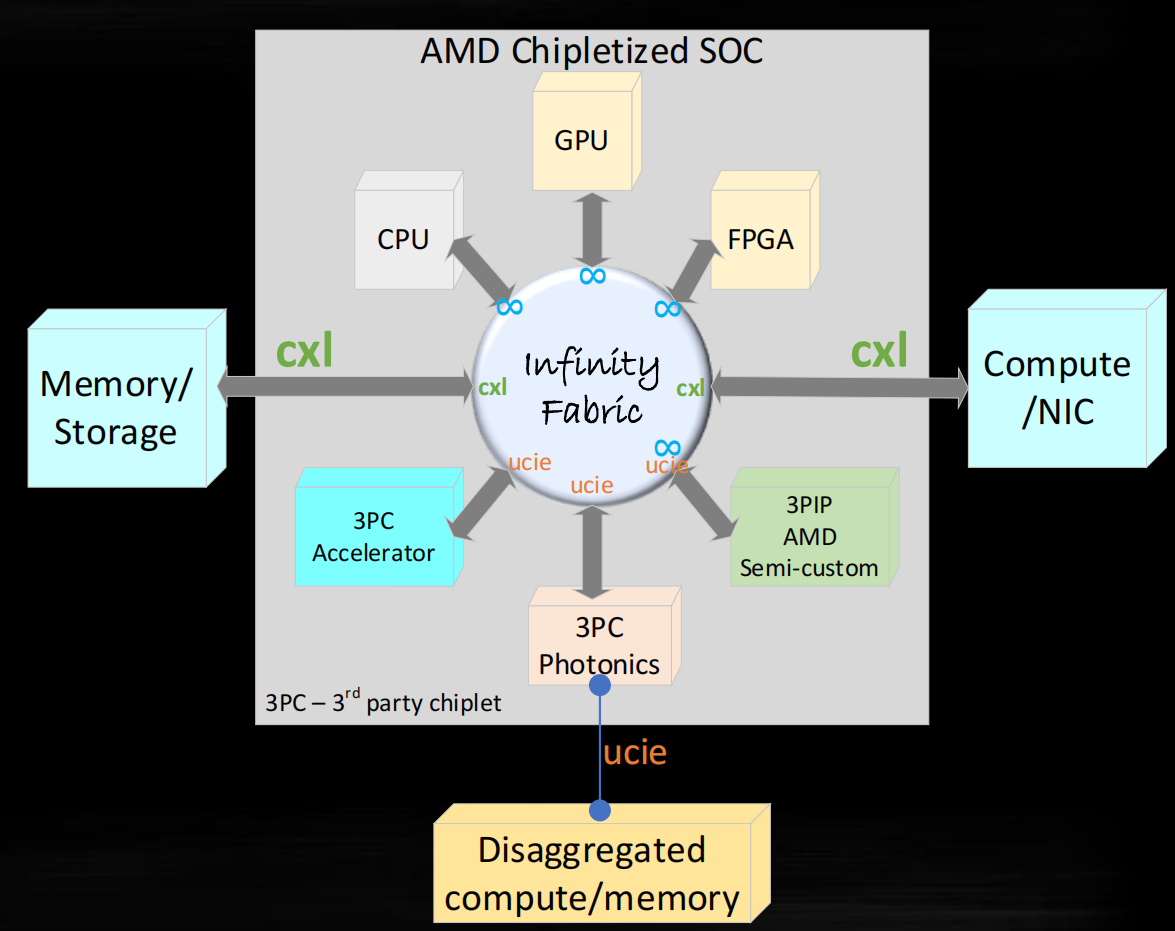
chiplet生态挑战
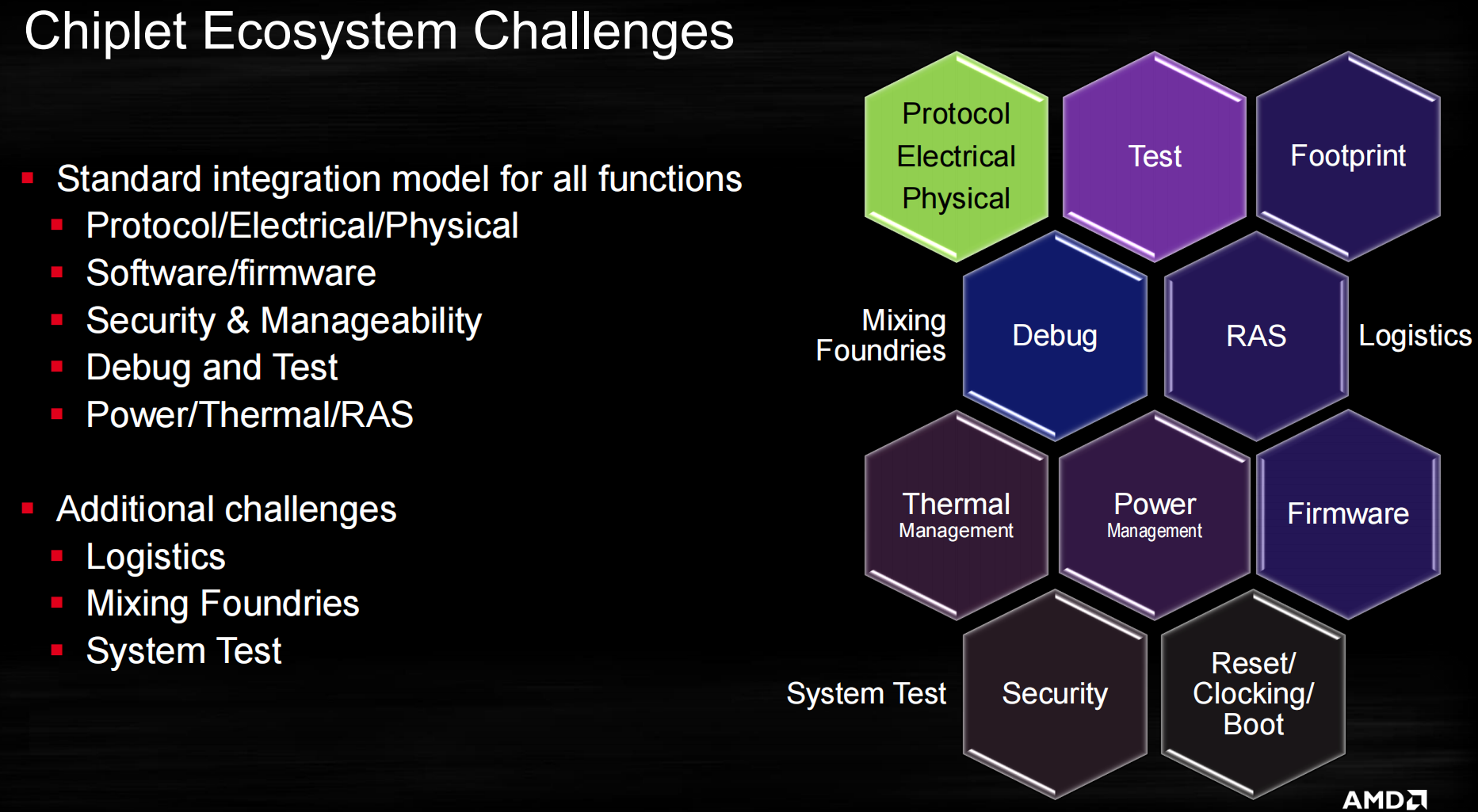
AMD的chiplet生态解决方案栈
- D2D control
(AMD在D2D接口协议层之外增加了并列的控制栈,该控制层的作用是什么?作不同协议栈的选通吗?如果作为protocol的选通,那D2D接口本身就有低延迟、高带宽的需求,如果通过control进行选通岂不是增加了延迟,那么存在的意义又是什么?) - DMU
硬件+固件(存在的作用是什么?难道是上层固件的内容,包括安全启动、复位、修复、功耗管理、热管理等?)

chiplet和CPO的应用——可扩展CXL switch
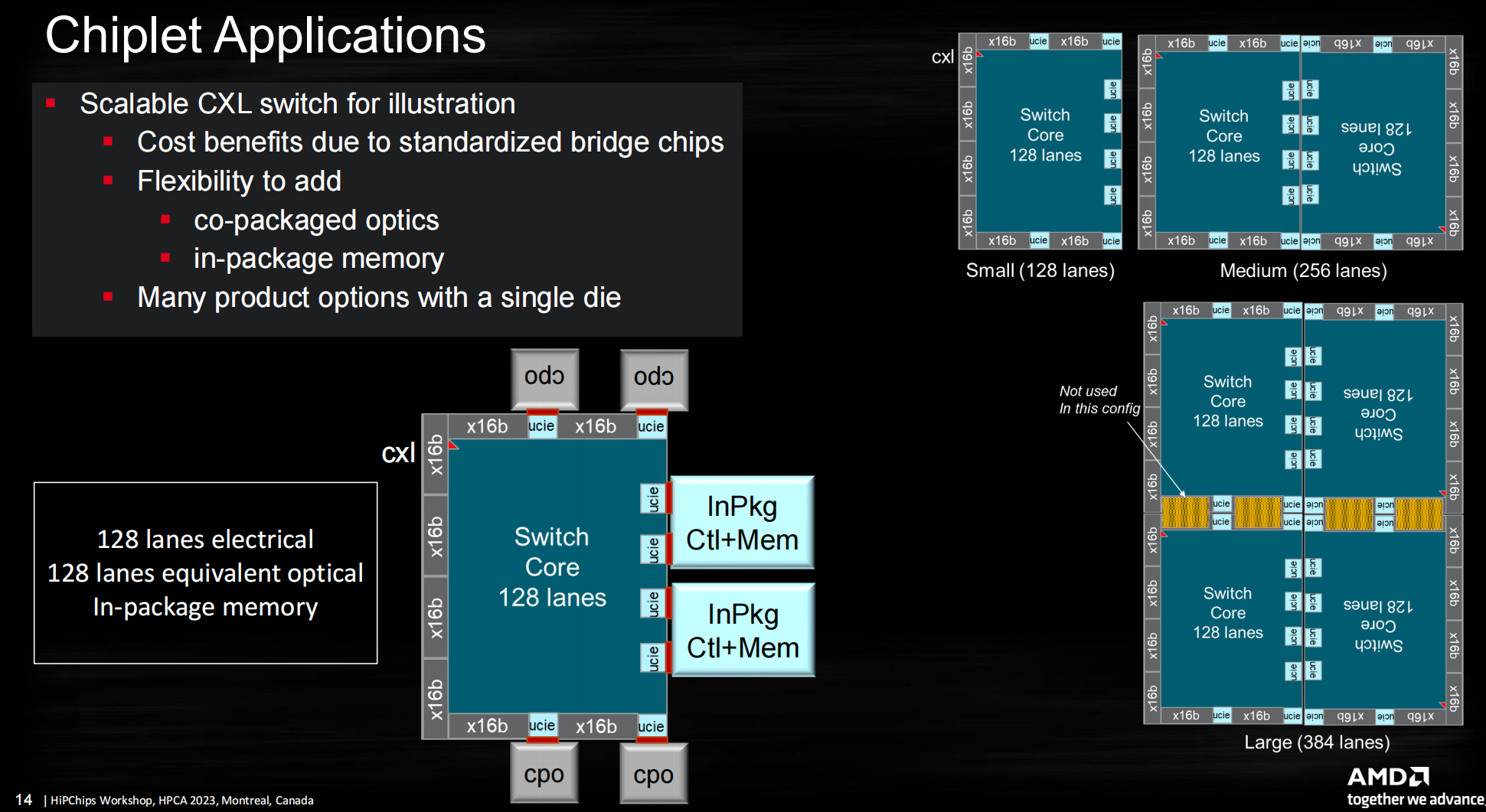
- 评
chiplet生态,为实现chiplet的涅槃而需要克服的挑战和障碍。AMD介绍chiplet生态构建的挑战,并且提出了自身的chiplet软硬件栈的解决方案,并宣称持续看好chiplet。


















 6487
6487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











