









作者及发刊详情
T. J. Ham et al., “ELSA: Hardware-Software Co-design for Efficient, Lightweight Self-Attention Mechanism in Neural Networks,” 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 2021, pp. 692-705, doi: 10.1109/ISCA52012.2021.00060. keywords: {Runtime;Computational modeling;Graphics processing units;Artificial neural networks;Hardware;Energy efficiency;Natural language processing;attention;hardware accelerator;neural network},
与
A
3
A^3
A3加速器的一作同一人,详细参考:
【论文解析】A3: Accelerating Attention Mechanisms in Neural Networks with Approximation
摘要
正文
主要工作贡献
1)提出了一种新的近似自注意力机制,利用近似的、硬件友好的相似度计算,大大减少了推理过程中自注意力操作的计算量
2)提出了ELSA硬件加速器,探索了自注意力操作的近似和并行计算空间,提升了性能和能效。
3)采用多个具有代表性的基于自注意力的神经网络模型来评估ELSA,证明其可以实现比传统硬件更大的性能和能效提高
实验评估
选用模型: BERT(large)、RoBERTa(large)、ALBERT(large)、SASRec (3-layers model)、BERT4Rec (3-layers, 2-head model)
测试集:
Stanford Question Answering Dataset(SQuAD) 1.1 & 2.0
RACE dataset
IMDB review sentiment analysis dataset
MovieLens 1M dataset
PPA表现
对比平台:
Intel Xeon Gold CPU 6-core
NVIDIA V100 GPU,16GB memory
ELSA-Base:无近似机制
Ideal accelerator:和ELSA-Base有相同的硬件资源,但在1GHz下能维持100%的FP峰值吞吐
ELSA-conservative, moderate, aggressive:有近似机制
性能
实现了一个定制化的模拟器。
12个ELSA的峰值吞吐: 1.088 TOPS/accelerator × 12 ≈ 13 TOPS
Nvidia V100 GPU的峰值吞吐(
F
P
3
2
3
FP32^3
FP323): 14 TFLOPS
ELSA-Base的延迟是理想加速器的1.03倍。
延迟和带宽数据对比如下图所示:

面积、功耗
通过Chisel编写,完成功能验证,并次啊用DC综合、布局布线,使其运行在1GHz。
V100:815mm2@12nm,250W TDP
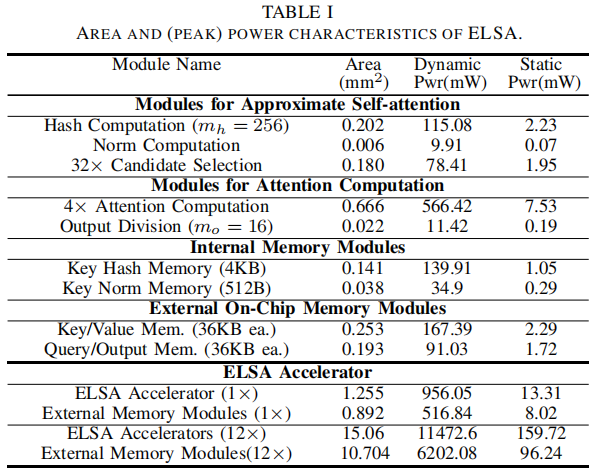
如图是能效比:
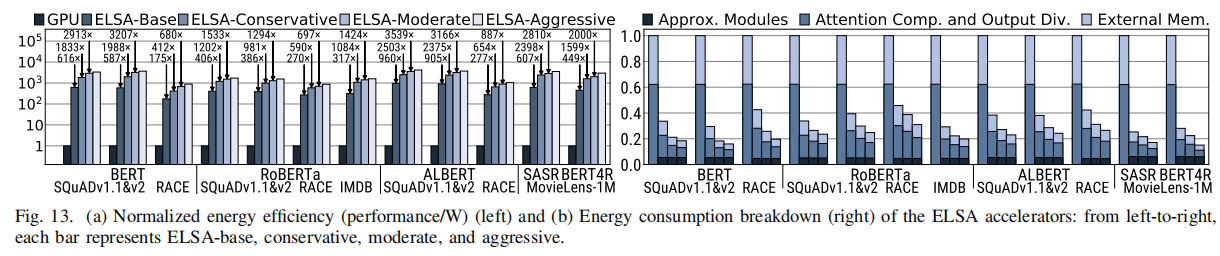 能效图和加速图结合,ELSA的能效加速比相比GPU有两个数量级的提升。(分别是442x、1265x、1726x、2093x)
能效图和加速图结合,ELSA的能效加速比相比GPU有两个数量级的提升。(分别是442x、1265x、1726x、2093x)
相比A3
在相同的数据集输入下,ELSA比A3有更小的精度损失。
相比Google TPUv2
运行ALBERT,测试SQuADv1.1/2, and RACE三个数据集,
ELSA-Base在上获得8.3x、 6.4x、 2.4x的峰值FLOPS提升,
ELSA-moderate获得27.8x、20.9x、8.0x的峰值FLOPS提升,
TPU相比GPU获得5.5x、6.7x、5.4x的峰值FLOPS提升
设计思想
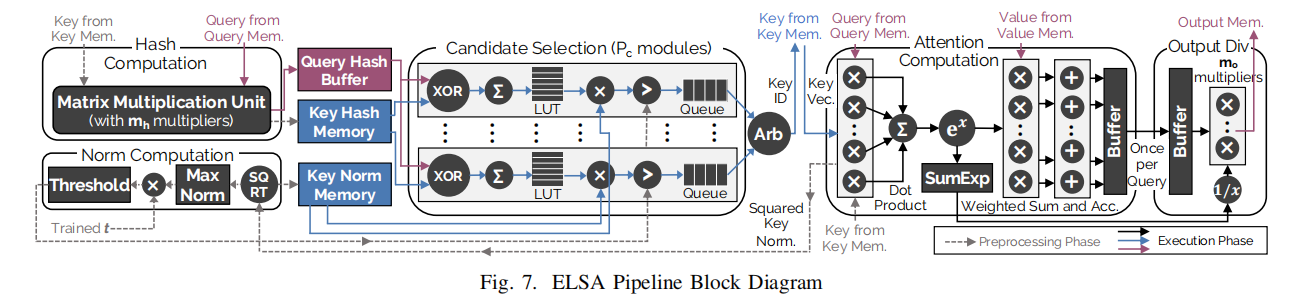
self-attention的近似
采用哈希和Hamming距离预测Q和K分量的余弦距离,依次判断出极小Attention Score的位置
硬件设计
参考文献
评
无需重新训练,采用模型无关的方法来加速推理



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











