






实时对话数字人VideoChat是由阿里达摩院开源的一个实时数字人对话。经实测,效果还不错,每次对话数字人生成视频的时间大致在6-8秒钟,今天将环境搭建步骤及遇到的问题整理下。
本地环境配置:
系统:Ubuntu22.04
显卡:RTX 4090 D(24G)
cuda:12.4(比github推荐的版本高,但是我也复现成功了)
torch:2.3.0
来看下demo显存需求:
级联方案(ASR-LLM-TTS-THG):约8G,首包约3s(单张A100)。
端到端语音方案(MLLM-THG):约20G,首包约7s(单张A100)。
github上面有两种搭建方式,一种级联方案,一种端到端方案。刚开始我搭建的端到端方案,但是一直没跑起来,后来转战级联方案,终于成功了,看下最终效果。
一、安装环境
git clone https://github.com/Henry-23/VideoChatgit checkout cascade_only
当然,如果clone不了的话,也可直接下载代码放进系统里面。但是,问题来了,GitHub上面怎么少文件呢?我比对了下,少了weights文件,然后将weights文件从modelscope下载下来放进GitHub上面下载的代码下面。
趁着下载模型期间,我直接直接clone了下modelscope的地址,很快下载完了,然后我看了下clone下来的文件,发现有weight文件,然后就直接使用了这个代码。
到后面运行代码的时候,一直出现加载模型失败。invalid load key ,’v’
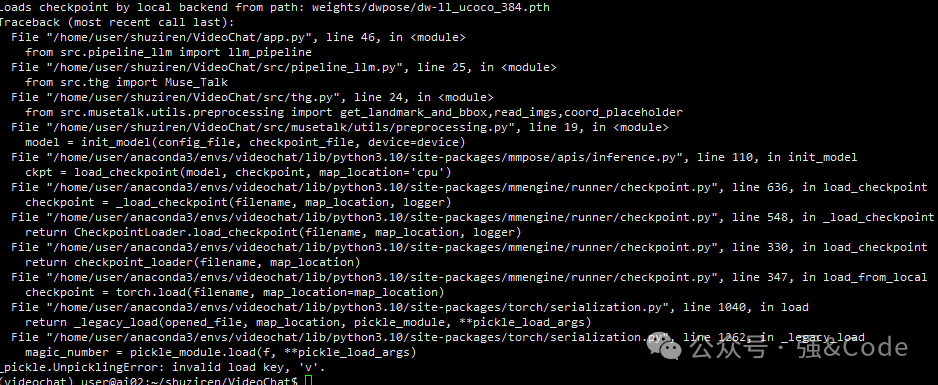
这种情况是因为没有通过lfs下载大文件,这种方式下载下来的只是个大模型的壳子。
所以,推荐大家直接按照github上面的步骤进行,防止走了我的坑
$ git lfs install$ git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git$ conda create -n metahuman python=3.10$ conda activate metahuman$ cd video_chat$ pip install -r requirements.txt
执行第一步的时候,首先需要安装lfs。接着后面按照步骤执行即可。若没有安装anaconda后台回复”conda“可拿到Ubuntu的anaconda安装文件。
sudo apt-get updatesudo apt-get instll git-lfs
二、出现错误修复
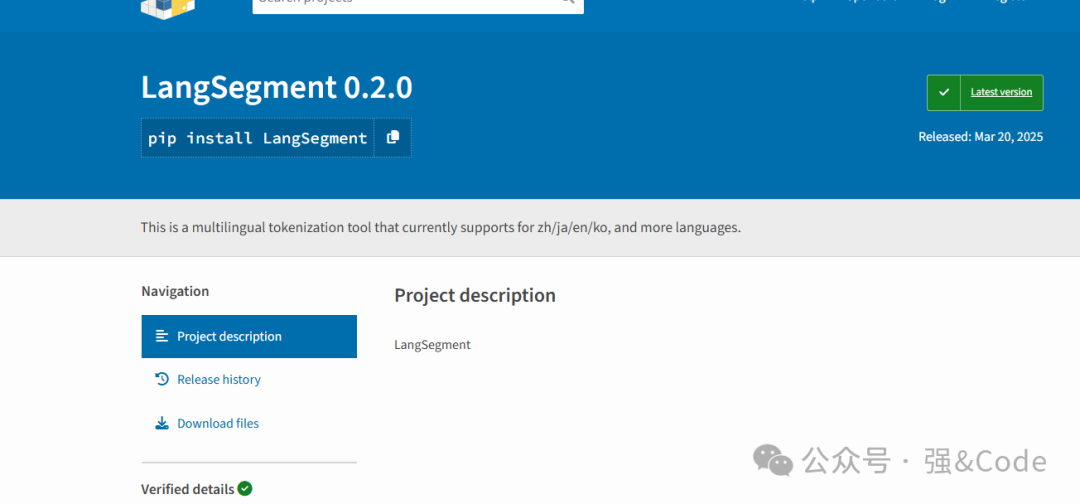
1、安装环境包的时候出现LangSegment==0.3.5 安装失败。如图

想着这种问题比较简单,直接
pip install LangSegment==0.3.5就行了,发现,根本没有这个版本,最新版本是0.2.0。然后去https://pypi.org/上查了一下,发现确实最新版本是0.2.0,如图
最后还是终于网上找到了这个版本,有需要的话后台回复”LangSegment“获取whl文件。
2、ntlk 错误,缺少下载文件如图:
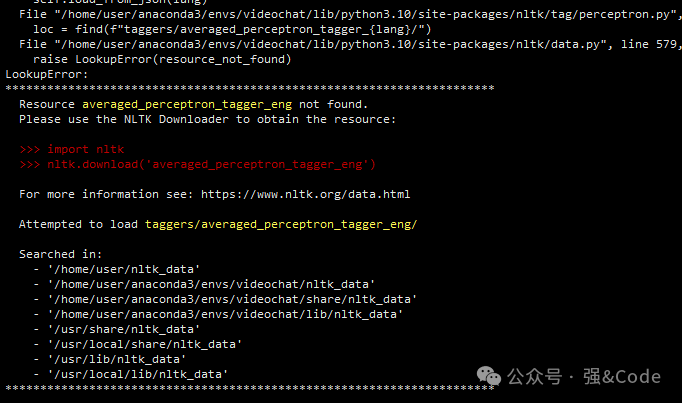
这个提示很友好,将步骤也告诉你了,按照红字部分的步骤安装下载即可。
import nltknltk.download('averaged_perceptron_tagger_eng')
3、got an unexpected keyword argument ‘proxies’,错误如图:
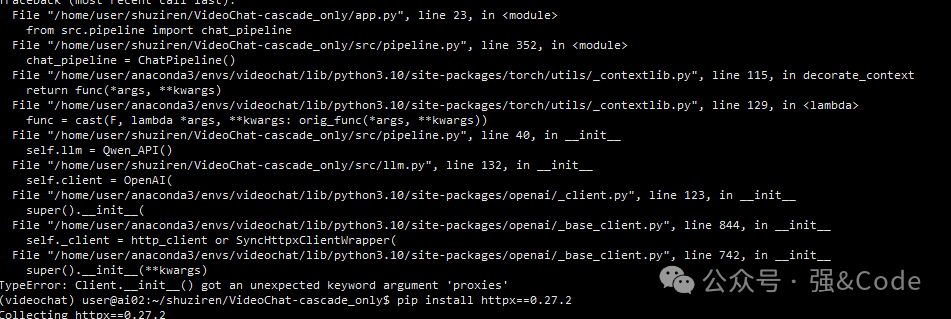
httpx 版本不匹配 pip install httpx==0.27.2即可
4、gradio启动 argument of type ‘bool’ is not iterable,错误如图:
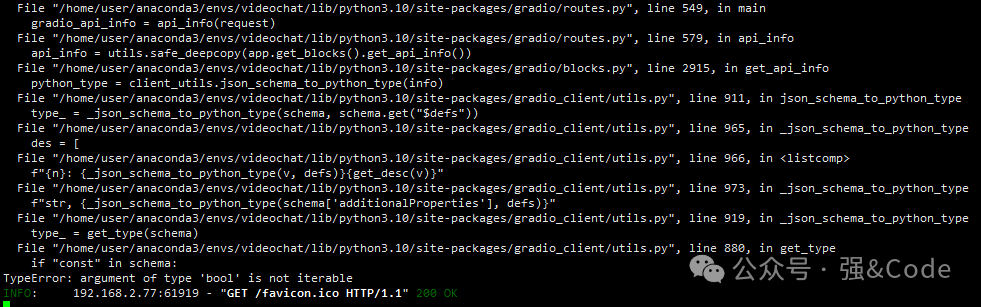
pip install pydantic==2.10.6安装pydantic即可
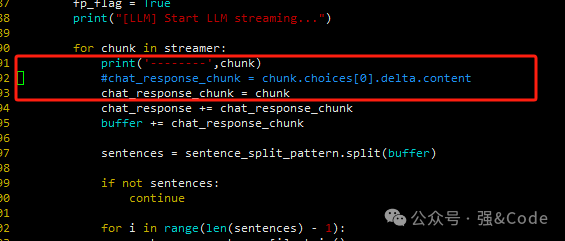
5、src下面llm.py文件报错,‘str’ object has no attribute 'choices',如图:

将代码部分修改如下即可。
三、接着 执行 app.py,终于成功了。好景不长,新问题又出现了
6、代码没报错,但是一直没生成语音、数字人视频。接着又是一通查找问题原因。是我的大模型生成回复的api接口调用不成功,试着将QWEN_API改成QWEN试试。src/pipline.py中代码修改如图:
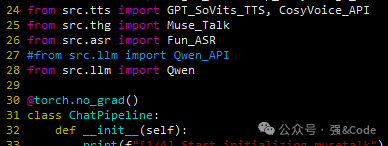
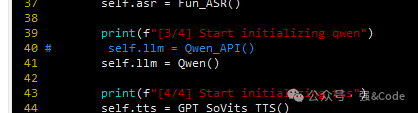
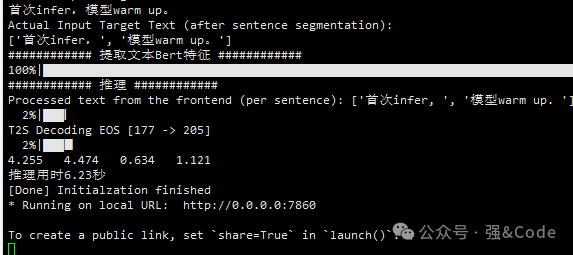
喜大普奔,终于生成成功了。如图:
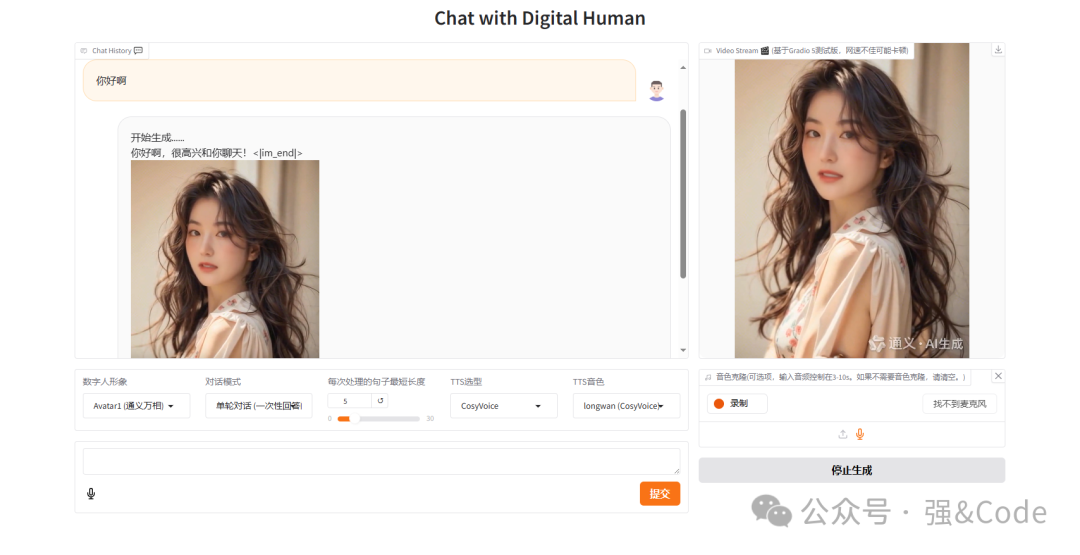
四、自定义自己的数字人形象。
官网说可以自定义自己的数字人形象,咱们接着来试试。
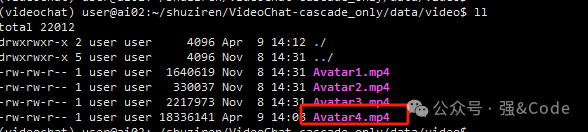
1、data/video 文件夹下上传自己的数字人形象,如图:
2、修改src/thg.py中的Muse_Talk类的avatar_list,如图:

名称要与上传的数字人视频名称一致。
3、在/app.py中Gradio的avatar_name中加入数字人形象。如图:

切记,这里只填自定义的数字人视频名称即可,若按照demo中的加上(”通义千问“)会一直卡在生成中。
4、重启项目即可使用自己的数字人形象。
四、语音克隆
这个倒没有遇到问题,上传自己准备克隆的语音,然后发送信息即可自动克隆语音。
总体感觉口型、数字人生成视频的时间都还是不错的。
这就是demo复现的整个过程,如果大家在复现的时候有遇到什么问题的话,欢迎大家一起来讨论。


















 1657
1657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











