











作者单位信息

南洋理工大学、山东大学、新加波国立大学、新加波制造技术学院
文章目录
Abstract
优先调度规则(PDR)被广泛用于解决现实世界的作业车间调度问题(JSSP)。在本文中,我们提出通过端到端深度强化学习智能体自动学习 PDR。我们利用 JSSP 的析取图表示,并提出了一种基于图神经网络(Graph Neural Network)的方案来嵌入求解过程中遇到的状态。由此产生的策略网络与大小无关,可以有效地在大规模实例上进行泛化。实验表明,该智能体可以从头开始学习具有基本原始特征的高质量 PDR,并且在对抗现有最佳 PDR 时表现出强大的性能。学习到的策略在训练中未经历的更大的实例上也表现良好。
1 Introduction
先是讲JSSP在计算机科学和运筹学中著名的组合优化问题,关于什么是JSSP,可参考文章。
PDR优先调度规则具有高效直观易实现的特点,但是设计PDR非常耗时且需要专家领域知识,
因此本文想自学习到PDR。
深度强化学习可以自学习PDR,
在本文中,我们首先提出了基于 PDR 的调度的马尔可夫决策过程 (MDP) 公式,其中通过利用 JSSP 的析取图表示来捕获状态。这种表示有效地整合了操作依赖和机器状态。然后,我们提出了一种基于图神经网络 (GNN) 的方案,该方案具有有效的计算策略,可将析取图中的节点编码为固定维度的嵌入。基于该方案,我们设计了一个可以处理任意大小的JSSP实例的策略网络,有效地实现了在小型实例上的训练和对大型实例的泛化。我们使用策略梯度算法训练网络以获得高质量的 PDR,无需监督。对生成的实例和标准基准的大量实验表明,我们的策略训练的 PDR 明显优于现有的手动设计的 PDR,并且可以合理地很好地泛化到比训练中使用的那些大得多的实例。
2 Related Work
我比较感兴趣的地方:
In [24], DRL is employed to learn local search heuristics for solving a similar problem, where the states are represented by a Directed Acyclic Graph (DAG) describing the temporal relations among jobs in the corresponding schedule。(Xinyun Chen and Yuandong Tian. Learning to perform local rewriting for combinatorial optimization. In Advances in Neural Information Processing Systems, pages 6278–6289, 2019.)
This limitation is partially alleviated in [25], which also employs an image based representation but with a transfer learning method to reconstruct the trained policies on problems with different sizes.(Shuai Zheng, Chetan Gupta, and Susumu Serita. Manufacturing dispatching using reinforcement
and transfer learning. In European Conference on Machine Learning and Principles and Practice
of Knowledge Discovery in Databases (ECML PKDD), 2019.)
Research on standard JSSP is rather sparse. In [29], an imitation learning method is proposed to
learn dispatching rules for JSSP, where optimal solutions to the training instances are labelled using a
MIP solver.(这还是有标签学习哦,imitation learning待详细了解)(Helga Ingimundardottir and Thomas Philip Runarsson. Discovering dispatching rules from data using imitation learning: A case study for the job-shop problem)
最后写到,本文的方法可以不用手工设置特征,考虑JSSP的图特征。本文基于析取图可以从低级特征中提取出信息知识,且直接做出决策不需要预先定义的PDR。
3 Preliminaries
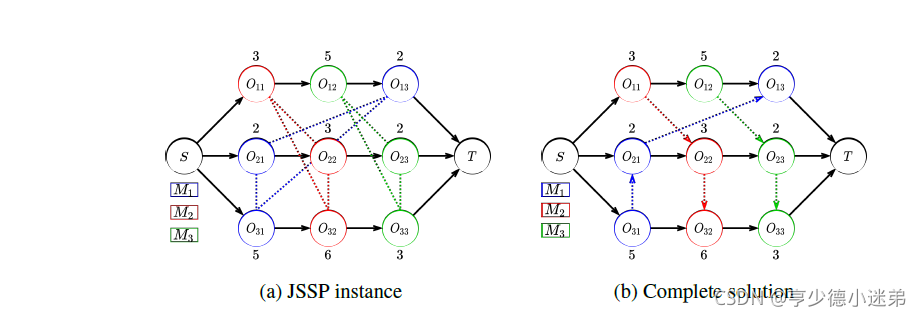
4 Method
4.1 Markov Decision Process Formulation
文中定义了连续决策过程的个数为工序的总个数,也就是要做工序总个数那么多个决策。
(为什么啊,为什么不可以是根据真实的时间顺序,在每个时间点确定多个工序要在哪个机器上加工。这跟后面定义的奖励虽然可以强行使得最大化总的奖励等价于最小化完工时间好像有联系,奖励好像确实能体现出每个状态之间转换的好坏,但是我还是说不出很好的理由。
9.4补充:主要是这个决策过程中的状态并不是一般按照时间点的那种状态来的,因为比如状态i和状态
i+1也许在这两个状态进行的决策的时间点并不存在先后的顺序关系,我感觉更像是一种,就是智能体在图上学会了画图,画连接顶点之间的有向边,同时还懂得擦除不好的边,新增好的边。简单说就是状态之间的时间性不是很强。)
这里文中指的PDR是说你在某个状态下,智能体要决定从可选的工序集合中选择一个工序来加工。并且会尽早的放置在相应的机器上。
解决JSSP可以看作是确定每个析取方向的一个过程。一般的PDR如最短处理时间(SPT)都是人工设计的,本文是想通过DRL来自动地生成PDR。
因此定义了马尔可夫决策过程的三要素:State, Action, Reward。
State
当前状态的已经确定方向了的析取图,最终状态就会是一个全部确定了方向的析取图,也就是一个调度方案。
Action
动作正如先前所说,是从可选的工序中选择一个工序放到相应的机器上进行加工。
因为每个工作在一个时间点最多只有一个工序被加工,因此每个状态可选的动作空间最大是工件的个数,且随着调度过程的进行,动作空间会不断的减小。
State transition
一旦 PDR 确定了接下来要调度的操作 at,我们首先找到最早可行的时间段分配在所需的机器上。然后,我们根据当前的时间关系更新该机器的析取弧的方向,并生成一个新的析取图作为新状态 st+1。
就是下图中所述的那样,会根据最先可加工时间来重新确定析取的方向。
在状态4下,可选的工序包括工序32,工序12和工序23,本次选择了工序32。
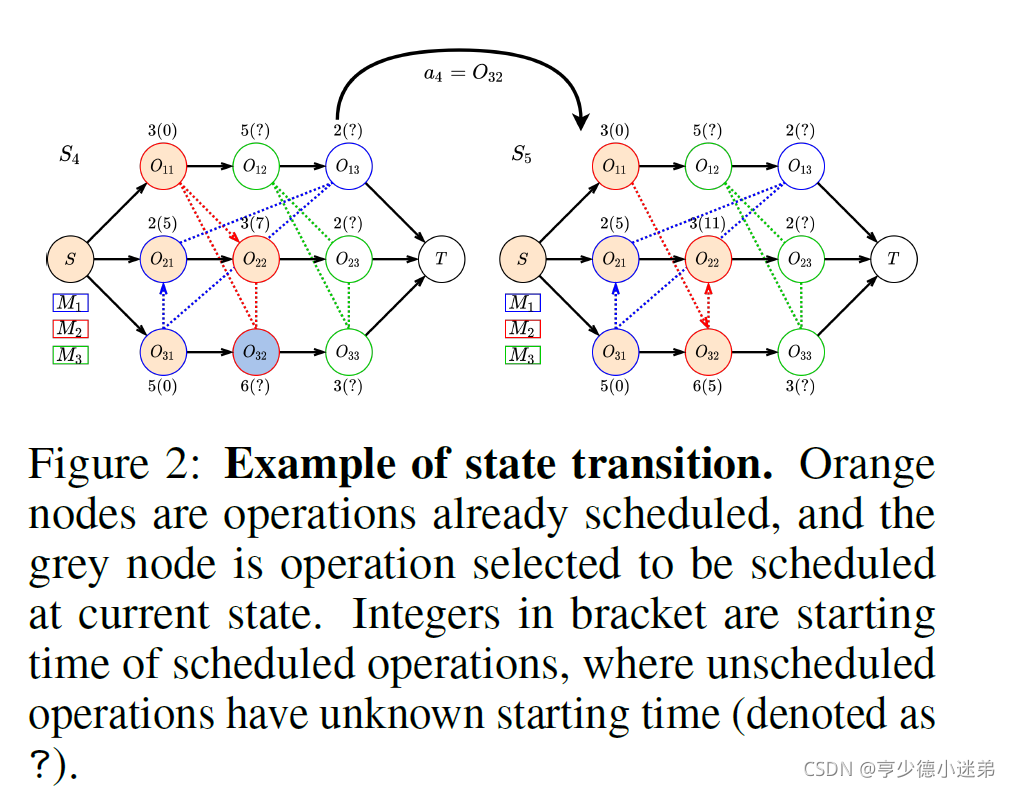
Reward
强化学习的目标是最大化奖励,而在本次的JSSP中是为了最小化加工时间。
定义奖励如下:
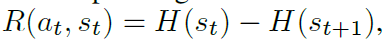
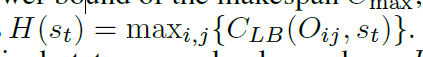
也就是相邻状态的,最大的,预估完成时间下限之差。
每个状态之间的奖励之和最终等于

H(s0)是个常熟,因此最大化奖励等价于最小化加工时间。
但是我这里的疑问是,你在每个状态之间的奖励的含义不明确啊。首先这个奖励看得出来是非正整数,也就是最好是0,否则就是负数。
以图2的状态转移为例子,上面的例子中的状态之间的奖励是:(3+7)- (3+11)= -4
但是如果我选择的是工序12,那么奖励是:(3+7)- (3+7)=0 因为工序12的预估完成时间是8,小于3+7。
那这能说明,我选择工序12的奖励更大效果就更好吗?为什么呢?从这个例子中,我看不出来早点选工序12和晚点选工序12有什么大的区别啊,因为你最终都会像上面提到的状态转移一样,如果工序12的开时间更短的话,你最终还不是要重新改变之前决定的析取方向。
这里我表示很疑惑,不清楚这样定义的奖励怎么看出不同行为选择间好坏的区别啊!
9.4修改:这里文中说的是the lower bound of the makespan Cmax,文中定义了计算每个工序的预估完工时间的方法,就是迭代的计算,只根据上一个工序的约束来算。
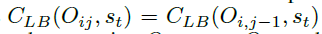
然后根据文中的例子,我计算了图2这个例子。
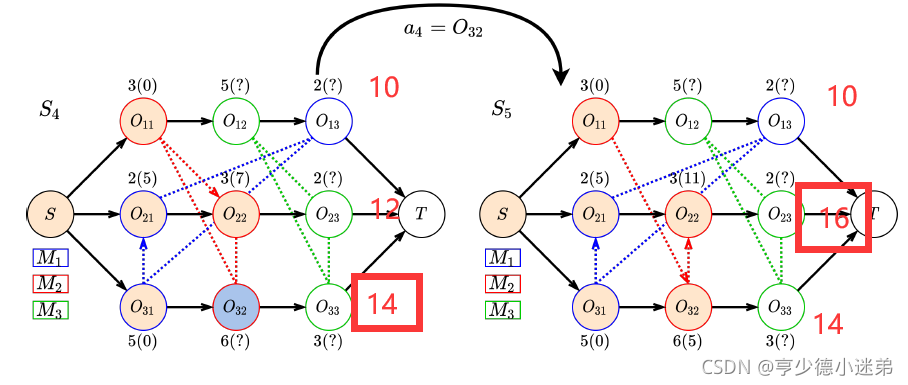
那我的问题来了,为啥不考虑下,比如都需要在同一台机器上进行处理的工序,为什么不考虑这些工序之间的时间约束来计算预估完成时间呢?那样不是更精确吗?哦哦好像这是不可能的,因为这样做的话,需要考虑的情况太多了,要穷尽每个选择了,这样的计算耗时是完全不能承受的。
还有问题就是如图二上示例,智能体首先是决定了选择加工工序O32,但是本身的顺序应该先是O11到O22,但是根据前文提到“However, solely deciding which operation to dispatch is not sufficient, as we also need to choose a suitable start time for it.In order to build tight schedules, it is sensible to place the operation as early as possible on the corresponding machine [29].” 因为O32的开始时间更短,因此就更改了其中的顺序。但是这对于智能体而言是外部的一种人为经验的修正,但是智能体真正学到的是未改变顺序的那种理解,而不是人为经验的修正的理解。这样的智能体真的能学到东西吗?
另外如果说是智能体只是学习到安排哪一个节点(工序)的话,但是如果某种情况是没有人为修正的情况,那是不是说智能体也是学到了相应的两个节点的顺序了呢?也就是说如果上面图2,工序O32的开始时间是大于O22的话,那就是不是说其实智能体也是学到了从O22到O32的顺序呢?
但是我还是不太能理解,为什么这样计算的预估完工时间的下限就能指引智能体找到一条能够减少实际完工时间的方向呢?
这个目前还不能理解。
Policy
对于状态 st,随机策略 输出 At 中动作的分布。如果采用传统的 PDR 作为策略,则分布为 one-hot,且具有最高优先级的动作的概率为 1。
4.2 Parameterizing the Policy
析取图全面包含了JSSP的数值和结构信息,如工序在每台机器上的处理时间、优先约束和处理顺序。可以提取嵌入在析取图中的所有状态信息(我觉得是神经网络足够强大的情况),那么有效的调度是可行的,然后拿来训练图神经网络。本文还说训练的图神经网络具有大小无关的泛化性。(为啥,你每提取的析取图的结构不是有大小的吗,大小不就是工序的个数吗,意思是不管你什么大小的结构拿进来都可以embedding成同样的大小,因此不同大小的图训练得到的参数也可以互相用,反正至少在实现逻辑上是是不冲突的。)
Graph embedding
图嵌入我感觉就是对图的一种特征提取。(一种将图数据(通常为高维稠密的矩阵)映射为低微稠密向量的过程,能够很好地解决图数据难以高效输入机器学习算法的问题。)
本文采用的是图同构网络Graph Isomorphism Network (GIN)。
但是GIN一开始是用于无向图的,需要推广GIN应用到析取图上。本文说自然而然的想法是用两条方向相反的有向边代替一条无向边,然后说传统的GIN中的相邻节点定义为所有指向其本身的相邻节点。
这里我有两个疑问:1。为什么说这样做了,特别是根据后文提到的,本文输入的还是个有向图啊,怎么能够用处理无向图的GIN来处理呢?2。如果可以处理的话,为什么是定义的相邻节点是指向其本身的节点,而不是被其指向的节点为其相邻节点呢? 感觉这两个问题需要我看完GIN这篇文章才能弄懂。
然后本文给出了一个具体的例子:
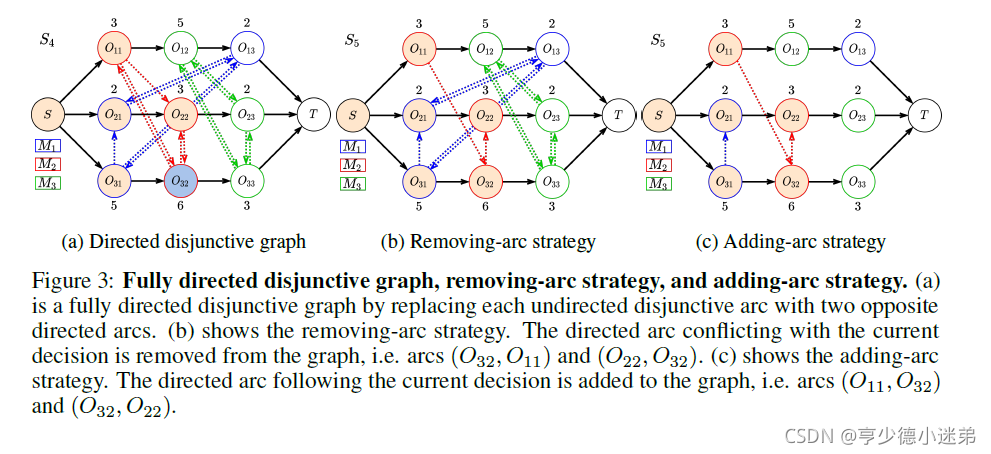
这里本文为了解决图稠密的问题,特别是在前期的时候,如果包括那些非连接弧的话,前期的图非常稠密,这样不利于被GIN处理。因此,本文采用了Adding-arc 策略,也就是用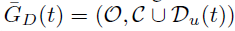
来近似替代
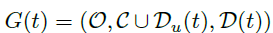
也就是说,每个状态输入的都是确定了方向的析取图,未确定方向的弧长(非连接弧)就忽略了。
最后为图中的每个节点定义了一个二维向量,
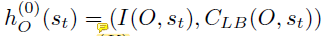
包括这个节点(工序)是否被处理了和这个工序的预估完成时间下限。
然后就是另一个p维度的向量用来表示整个析取图的结构
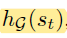
我的理解:前者是对加工时间、预估完工时间的下限和是否被处理的一种表示。后者是对整个图的结构表示,也就是约束关系和处理顺序。
Action selection
利用上面提到的两个向量来进行行为选择,细节详见论文。
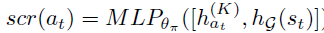
4.3 Learning Algorithm
采用Proximal Policy Optimization (PPO),也就是用actor-critic。actor和critic的结构是一样的,然后来训练网络。算法细节见补充材料。

我暂时还没认真看,待看。
作者还总结了一下本算法的三大优势:1.前面说到过的,可以处理任意大小的析取图,具有泛化性。2.可以通过删除或新增节点的方式来解决动态的JSSP问题(如新工件加入,机器损坏)。3.可用于flow shop和open shop问题,这两者也都有其相应的析取图表示。(Scott J Mason and Kasin Oey. Scheduling complex job shops using disjunctive graphs: a cycle elimination procedure. International Journal of Production Research, 41(5):981–994, 2003. Andrea Rossi and Michele Lanzetta. Nonpermutation flow line scheduling by ant colony optimization. AI EDAM, 27(4):349–357, 2013.)
5 Experiment
厉害哈哈哈。
主要是通过Taillard’s method生成的实例来训练和测试,然后对公共数据集Taillard’s instances和DMU instances来进行测试。
对于生成的数据集,最优解是利用Google OR-Tools来得到,放一个结果表。
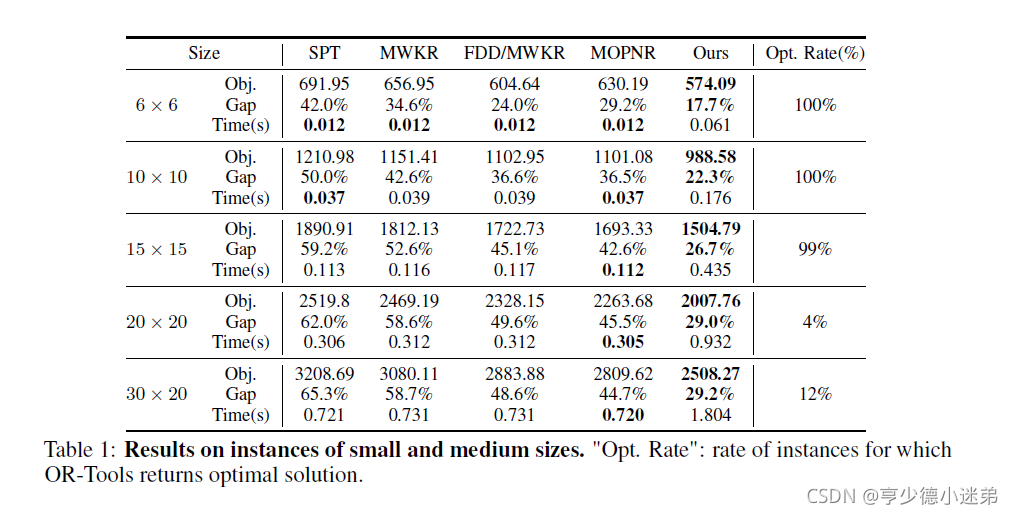
每个size随机生成100实例,Obj指的是平均完成时间。Gap指的是和Google OR-Tools得到的解的差距。
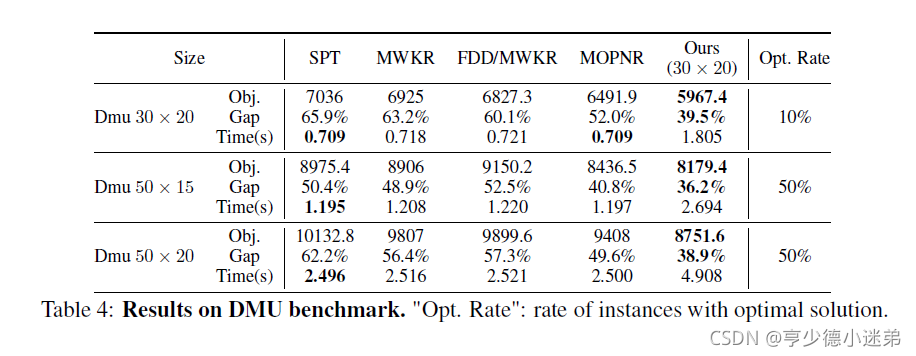
对于公共数据集,对比的是目前已知最好的解。给个表:
6 Conclusions and Future Work
在本文中,我们提出了一种基于端到端 DRL 的方法来自动学习用于解决 JSSP 的高质量 PDR。基于 JSSP 的析取图表示,我们提出了基于 PDR 的调度过程的 MDP 公式。然后我们设计了一个基于 GNN 的大小无关的策略网络,使得包含在 JSSP 图结构中的模式可以被有效地提取和重用以解决不同大小的实例。在生成的和公共的基准实例上进行的大量实验很好地证实了我们的方法相对于传统的手动设计的 PDR 的优越性。未来,我们计划进一步提高我们方法的性能,并将其扩展到支持其他类型的车间调度问题和具有不确定性的复杂环境。
Broader Impact
一些工作 [49, 50] 讨论了通过集成现代人工智能技术来设计智能生产系统。我们的工作解决了现实世界生产系统中普遍存在的一个众所周知的问题,即作业车间调度,在这个范围内。这项工作中的自动化端到端学习系统试图将人工从为特定作业车间调度问题设计有效调度规则的繁琐工作中解放出来。然而,另一方面,这项工作可能有一些局限性。首先,尽管性能有所提高,但由于深度神经网络的不可解释性,它牺牲了可解释性,而传统的基于调度规则的调度系统对人类来说是直观的。由于潜在的风险和不确定性,此问题可能会使某些应用程序不可信。其次,高度自动化和端到端的系统可能会隐藏一些关键但容易被忽视的细节,并在底层扭曲人类的理解。
还是可解释性的问题哈哈哈。
总结
方法很新,思考问题的角度很新颖独特,值得借鉴学习。但是前文提到的问题还没解决,后续解决了再来总结下。

















 2061
2061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









