







一:Perceptron(感知机)
1.问题描述

Define a two-class problem, including 30 positive data and 30 negative data.
Write the code of perceptron using Python.
2.实现过程
(1)定义一个二分类问题:
设置数据集有60个点,30个正样本,30个负样本,训练感知机将正样本和负样本正确分类,用一条线可视化分类结果。
简单起见,将坐标都设置为整数,坐标横坐标在6及其以下的为正样本,在图中用蓝色表示,横坐标在7及其以上的为负样本,在图中用红色表示。
正样本标签设为1,负样本标签设为0.
(2)将数据集的点可视化出来:
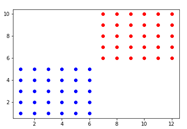
(3)初始化w权重和偏置项b:
W = [1,0], b = 0
(4)根据实验要求定义目标函数以及权重更新规则:
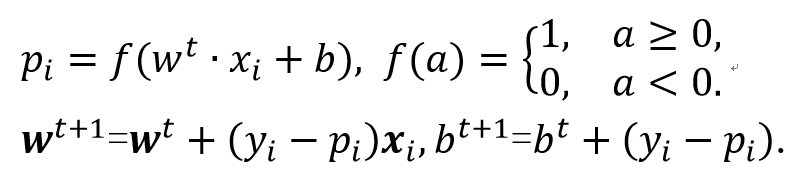
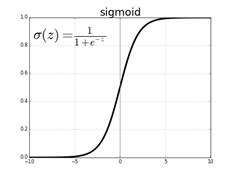
其中,f(a)使用Sigmoid函数激活:
(5)根据目标函数和权重更新规则训练样本,得到训练好的权重和偏置项。
(6)根据训练好的权重和偏置项分类样本,得到最终分类线:

3.实现代码
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1/(1 + np.exp(-x))
p_x = np.array([[1, 1], [1, 2], [1, 3], [1, 4], [1, 5], [2, 1], [2, 2], [2, 3], [2, 4], [2, 5], [3, 1], [3, 2], [3, 3], [3, 4], [3, 5], [4, 1], [4, 2], [4, 3], [4, 4], [4, 5], [5, 1], [5, 2], [5, 3], [5, 4], [5, 5], [6, 1], [6, 2], [6, 3], [6, 4], [6, 5], [7, 6], [7, 7], [7, 8], [7, 9], [7, 10], [8, 6], [8, 7], [8, 8], [8, 9], [8, 10], [9, 6], [9, 7], [9, 8], [9, 9], [9, 10], [10, 6], [10, 7], [10, 8], [10, 9], [10, 10], [11, 6], [11, 7], [11, 8], [11, 9], [11, 10], [12, 6], [12, 7], [12, 8], [12, 9], [12, 10]])
y = np.array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
plt.figure()
for i in range(len(p_x)):
if y[i] == 1:
plt.plot(p_x[i][0], p_x[i][1], 'bo')
else:
plt.plot(p_x[i][0], p_x[i][1], 'ro')
w = np.array([1, 0])
b = 0
a = np.zeros(60)
f = np.zeros(60)
p = np.zeros(60)
for j in range(300):
for i in range(len(p_x)):
a[i] = np.dot(w, p_x[i]) + b
f[i] = sigmoid(a[i])
p[i] = f[i]
w = w + (y[i] - p[i])*p_x[i]
b = b + (y[i] - p[i])
line_x = [0, 12]
line_y = [0, 0]
for i in range(len(line_x)):
line_y[i] = (-w[0] * line_x[i] - b)/w[1]
plt.plot(line_x, line_y)
plt.savefig("picture.png")
二:Linear Regression(线性回归)
1.问题描述

Download a regression dataset from UCI machine learning repository(https://archive.ics.uci.edu/ml/datasets.php)
Write the Python code of linear least squares to solve the linear regression problem.
2.视频教程
https://www.bilibili.com/video/BV1Xt411s7KY?
3.实现代码
https://download.csdn.net/download/qq_39932172/16524059
三:K-Nearest Neighbors for Classification(KNN)
1.问题描述

Download a classification dataset from the UCI machine learning repository(https://archive.ics.uci.edu/ml/datasets.php).
Split the datdaset into a training set and a test set.
Write the Python code of k-nearest neighbors to solve the classification problem.
2.实现过程
https://blog.csdn.net/qq_43923588/article/details/107672879
3.实现结果

4.实现代码
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import numpy as np
# 数据获取
def get_data():
iris = load_iris()
data = iris.data
result = iris.target
return data, result
# 将数据处理为训练集和测试集
def data_deal(data, result):
data_list = []
for i in data:
tem_list = [i[0], i[1]]
data_list.append(tem_list)
res_list = []
for j in result:
res_list.append(j)
train_list = data_list[0: 10] + data_list[20: 80] + data_list[90: 100]
train_result = res_list[0: 10] + res_list[20: 80] + res_list[90: 100]
test_list = data_list[0: 40] + data_list[60: 100]
test_result = res_list[0: 40] + res_list[60: 100]
return data_list, train_list, test_list, train_result, test_result
# 回归方法训练
def train(learning_rate, iter_num, train_data, result):
x_c = 0
y_c = 0
for i in train_data:
x_c = x_c + i[0]
y_c = y_c + i[1]
m = x_c/len(train_data)
n = y_c/len(train_data)
w = 0
b = 0
ok_rate = 0
for i in range(iter_num):
train_r = []
b = n-w*m
count = 0
for j in train_data:
if j[1] > w*j[0]+b:
train_r.append(0)
else:
train_r.append(1)
for ii in range(len(result)):
if result[ii] == train_r[ii]:
count = count+1
train_ok_rate = count/len(train_data)
if ok_rate <= train_ok_rate:
w = w + learning_rate
else:
w = w - learning_rate
learning_rate = learning_rate*0.9
ok_rate = train_ok_rate
return ok_rate, w, b
# 回归方法测试
def test(w, b, test_list, test_result):
test_res = []
count = 0
for j in test_list:
if j[1] > w * j[0] + b:
test_res.append(0)
else:
test_res.append(1)
for i in range(len(test_result)):
if result[i] == test_res[i]:
count = count + 1
oks = count/len(test_result)
return oks
# 绘制函数图像和输入点
def fun_image(w, b, dot):
iris = load_iris()
irisFeature = iris.data
irisTarget = iris.target
ax1 = plt.subplot(1, 2, 1)
ax2 = plt.subplot(1, 2, 2)
plt.sca(ax1)
for i in range(0, 100):
if irisTarget[i] == 0:
type11 = plt.scatter(irisFeature[i, 0], irisFeature[i, 1], c="r")
elif irisTarget[i] == 1:
type22 = plt.scatter(irisFeature[i, 0], irisFeature[i, 1], c="g")
plt.title("show train and test")
plt.xlabel("ewidth")
plt.ylabel("elength")
x = np.linspace(4, 7, 256)
plt.plot(x, w * x + b, color='black')
plt.legend((type11, type22), ('0', '1'))
plt.plot(dot[0], dot[1], color='black', marker='+')
plt.sca(ax2)
for i in range(20, 80):
if irisTarget[i] == 0:
type1 = plt.scatter(irisFeature[i, 0], irisFeature[i, 1], c="r", marker="8")
elif irisTarget[i] == 1:
type2 = plt.scatter(irisFeature[i, 0], irisFeature[i, 1], c="g", marker="8")
for i in range(0, 20):
if irisTarget[i] == 0:
type3 = plt.scatter(irisFeature[i, 0], irisFeature[i, 1], c="blue", marker="v")
elif irisTarget[i] == 1:
plt.scatter(irisFeature[i, 0], irisFeature[i, 1], c="orange", marker="v")
for i in range(80, 100):
if irisTarget[i] == 0:
plt.scatter(irisFeature[i, 0], irisFeature[i, 1], c="blue", marker="v")
elif irisTarget[i] == 1:
type4 = plt.scatter(irisFeature[i, 0], irisFeature[i, 1], c="orange", marker="v")
plt.title("show all")
plt.xlabel("ewidth")
plt.ylabel("elength")
x = np.linspace(4, 7, 256)
plt.plot(x, w*x+b, color='black')
plt.plot(dot[0], dot[1], color='black', marker='+')
plt.legend((type1, type2, type3, type4), ('train-0', 'train-1', 'test-0', 'test-1'))
plt.show()
# 回归方法判断点的类型
def check_point(w, b, dot):
y = w*dot[0] + b
if y > dot[1]:
return "回归判断该点类别为0"
else:
return "回归判断该点类别为1"
# k近邻法计算距离方法
def distance(A, B):
return (abs((B[0]-A[0])**2+(B[1]-A[1])**2))**0.5
# k近邻法训练,测试准确率
def K_train(train_list, train_result, k):
dis_list = []
# 所有点到别的点的距离
for i in train_list:
dis = []
for j in train_list:
dis.append(distance(i, j))
dis_list.append(dis)
# 获取到训练集中每个点的最近5个点的索引
min_dis_list = []
for m in range(len(dis_list)):
temp = []
for n in range(int(k+1)):
temp.append(dis_list[m].index(min(dis_list[m])))
dis_list[m][dis_list[m].index(min(dis_list[m]))] = 100
temp.sort()
x = temp[1:]
min_dis_list.append(x)
# 根据索引判断对应点的类别
dot_type = []
for ii in min_dis_list:
mm = 0
nn = 0
for jj in ii:
if jj <= 50:
mm = mm+1
else:
nn = nn+1
if mm >= nn:
dot_type.append(0)
else:
dot_type.append(1)
# 计算准确率
count = 0
for xx in range(len(dot_type)):
if dot_type[xx] == train_result[xx]:
count = count+1
return count/len(dot_type)
# k近邻法判断点的类型
def K_check_point(dots, check_list, result):
dis = []
for i in check_list:
dis.append(distance(dots, i))
min_dis = []
for j in range(5):
min_dis.append(dis.index(min(dis)))
dis[dis.index(min(dis))] = 100
zero = 0
one = 0
for s in min_dis:
if result[s] == 0:
zero = zero+1
else:
one = one+1
if one > zero:
return "K近邻法判断该点类别为0"
else:
return "K近邻法判断该点类别为1"
if __name__ == '__main__':
data, result = get_data()
data_list, train_list, test_list, train_result, test_result = data_deal(data, result)
learning_rate = 1
iter_num = 1000
ok_rate, w, b = train(learning_rate, iter_num, train_list, train_result)
test_ok_rate = test(w, b, test_list, test_result)
k = 5
K_ok_rate = K_train(train_list, train_result, k)
print("回归方法"
"数学模型:y={}x+{}\n"
"learning_rate:{}\titer_num:{}\n"
"训练模型准确率:{}\n"
"测试模型准确率:{}\n".format(round(w, 3), round(b, 3), learning_rate, iter_num, ok_rate, test_ok_rate))
print("K近邻法\n"
"K值选取为{}\n"
"判断准确率为{}\n".format(k, K_ok_rate))
dots = list(map(float, input("请输入要判断的点:(提示:5.3 1.8)").split()))
fun_image(w, b, dots)
print(check_point(w, b, dots))
print(K_check_point(dots, train_list, train_result))
四:MLP(多层感知机)
1.问题描述
Write the Python code of a 4-layer MLP (including 2 hidden layers) to solve the classification problem.
五:服务器配置
六:CNN 图像分类实战
七:RNN 语言模型实战
分别使用基础RNN、GRU和LSTM实现:
https://github.com/LilWingXYZ/Deep-Learning-Theory-and-Practice/tree/main/03_%E5%AE%9E%E9%AA%8C/06_RNN
八:文本情感分类
1.问题描述
Write the Python code of a RNN or CNN to solve the sentiment classification problem, and predict some examples.
2.实现过程
分别使用双向循环神经网络和TextCNN实现:
https://www.cnblogs.com/54hys/p/12343458.html

















 2521
2521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











