







文章目录
一、实验要求
在计算机上验证和测试多层神经网络针对不同数据集的训练效果,同时查阅相关资料。
二、实验目的
1、掌握sklearn开发环境
2、掌握sklearn.neural_network 下的神经网络分类器 MLPClassifier;
3、掌握sklearn.linear_model 下的感知机分类器Perceptron;
- 从sklearn导入感知机(单层神经网络)分类器与(多层)神经网络分类器
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron #感知机
from sklearn.neural_network import MLPClassifier #多层神经网络
from warnings import simplefilter
simplefilter(action='ignore', category=FutureWarning)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
- 自定义分界线绘制函数
#X只有2个特征,画边界线
def plot_decision_boundary(model, X, y):
x0_min, x0_max = X[:,0].min()-1, X[:,0].max()+1
x1_min, x1_max = X[:,1].min()-1, X[:,1].max()+1
x0, x1 = np.meshgrid(np.linspace(x0_min, x0_max, 100), np.linspace(x1_min, x1_max, 100))
Z = model.predict(np.c_[x0.ravel(), x1.ravel()])
Z = Z.reshape(x0.shape)
plt.contourf(x0, x1, Z, cmap=plt.cm.Spectral)
plt.ylabel('x1')
plt.xlabel('x0')
plt.scatter(X[:, 0], X[:, 1], c=np.squeeze(y))
三、实验内容
1.针对四种数据集,对比多层神经网络的分类效果
请针对如下四种数据集,对比2层隐藏层下不同神经元个数(2,2),(5,5),(10,10)以及4层神经网络(2,2,2,2),(5,5,5,5),(10,10,10,10),对比分类效果,以及每个模型的迭代次数和训练时间,然后给出分析结论。
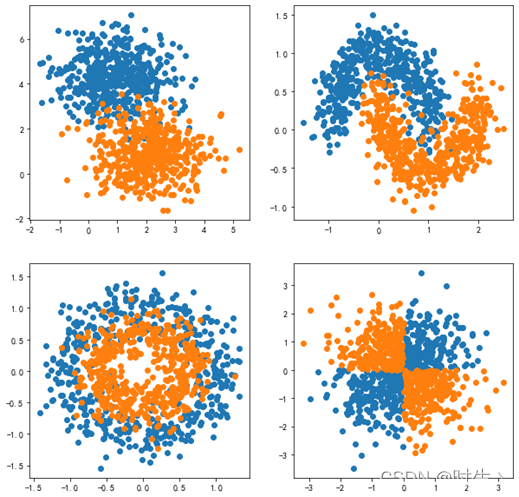
#1.基本数据集
np.random.seed(0)
X1,y1 = datasets.make_blobs(n_samples=1000, n_features=2, centers=2, cluster_std=1)
#2.太极数据集
X2,y2 = datasets.make_moons(n_samples=1000,noise=0.2,random_state=666)
#3.圆环数据集
X3,y3 = datasets.make_circles(n_samples=1000,factor=0.6,noise=0.2)
#4.异或数据集
np.random.seed(15)
X4 = np.random.randn(1000, 2)
y4 = np.logical_xor(X4[:, 0] > 0, X4[:, 1] > -0.0)
plt.figure(figsize=(10,10))
plt.subplot(2,2,1)
plt.scatter(X1[y1==0,0],X1[y1==0,1])
plt.scatter(X1[y1==1,0],X1[y1==1,1])
plt.subplot(2,2,2)
plt.scatter(X2[y2==0,0],X2[y2==0,1])
plt.scatter(X2[y2==1,0],X2[y2==1,1])
plt.subplot(2,2,3)
plt.scatter(X3[y3==0,0],X3[y3==0,1])
plt.scatter(X3[y3==1,0],X3[y3==1,1])
plt.subplot(2,2,4)
plt.scatter(X4[y4==0,0],X4[y4==0,1])
plt.scatter(X4[y4==1,0],X4[y4==1,1])
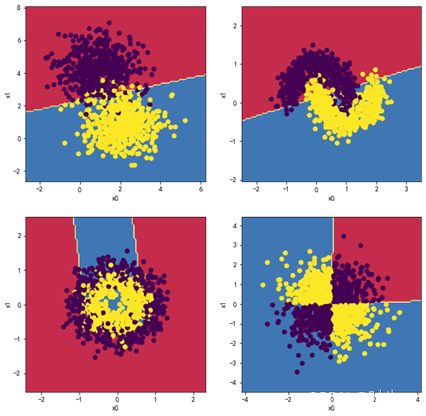
1.1观察两层,每层两个神经元效果:
MLP_clf1 = MLPClassifier(hidden_layer_sizes = (2,2),max_iter = 2000)
#输出用时
%time MLP_clf1.fit(X1,y1)
#输出最大迭代次数
print(MLP_clf1.n_iter_)
MLP_clf2 = MLPClassifier(hidden_layer_sizes = (2,2),max_iter = 2000)
#输出用时
%time MLP_clf2.fit(X2,y2)
#输出最大迭代次数
print(MLP_clf2.n_iter_)
MLP_clf3 = MLPClassifier(hidden_layer_sizes = (2,2),max_iter = 2000)
#输出用时
%time MLP_clf3.fit(X3,y3)
#输出最大迭代次数
print(MLP_clf3.n_iter_)
MLP_clf4 = MLPClassifier(hidden_layer_sizes = (2,2),max_iter = 2000)
#输出用时
%time MLP_clf4.fit(X4,y4)
#输出最大迭代次数
print(MLP_clf4.n_iter_)
plt.figure(figsize=(10,10))
plt.subplot(2,2,1)
plot_decision_boundary(MLP_clf1,X1, y1)
plt.subplot(2,2,2)
plot_decision_boundary(MLP_clf2,X2, y2)
plt.subplot(2,2,3)
plot_decision_boundary(MLP_clf3,X3, y3)
plt.subplot(2,2,4)
plot_decision_boundary(MLP_clf4,X4, y4)

1.2观察两层,每层五个神经元效果:
MLP_clf1 = MLPClassifier(hidden_layer_sizes = (5,5),max_iter = 2000)
#输出用时
%time MLP_clf1.fit(X1,y1)
#输出最大迭代次数
print(MLP_clf1.n_iter_)
MLP_clf2 = MLPClassifier(hidden_layer_sizes = (5,5),max_iter = 2000)
#输出用时
%time MLP_clf2.fit(X2,y2)
#输出最大迭代次数
print(MLP_clf2.n_iter_)
MLP_clf3 = MLPClassifier(hidden_layer_sizes = (5,5),max_iter = 2000)
#输出用时
%time MLP_clf3.fit(X3,y3)
#输出最大迭代次数
print(MLP_clf3.n_iter_)
MLP_clf4 = MLPClassifier(hidden_layer_sizes = (5,5),max_iter = 2000)
#输出用时
%time MLP_clf4.fit(X4,y4)
#输出最大迭代次数
print(MLP_clf4.n_iter_)
plt.figure(figsize=(10,10))
plt.subplot(2,2,1)
plot_decision_boundary(MLP_clf1,X1, y1)
plt.subplot(2,2,2)
plot_decision_boundary(MLP_clf2,X2, y2)
plt.subplot(2,2,3)
plot_decision_boundary(MLP_clf3,X3, y3)
plt.subplot(2,2,4)
plot_decision_boundary(MLP_clf4,X4, y4)

1.3观察两层,每层十个神经元效果:
MLP_clf1 = MLPClassifier(hidden_layer_sizes = (10,10),max_iter = 2000)
#输出用时
%time MLP_clf1.fit(X1,y1)
#输出最大迭代次数
print(MLP_clf1.n_iter_)
MLP_clf2 = MLPClassifier(hidden_layer_sizes = (10,10),max_iter = 2000)
#输出用时
%time MLP_clf2.fit(X2,y2)
#输出最大迭代次数
print(MLP_clf2.n_iter_)
MLP_clf3 = MLPClassifier(hidden_layer_sizes = (10,10),max_iter = 2000)
#输出用时
%time MLP_clf3.fit(X3,y3)
#输出最大迭代次数
print(MLP_clf3.n_iter_)
MLP_clf4 = MLPClassifier(hidden_layer_sizes = (10,10),max_iter = 2000)
#输出用时
%time MLP_clf4.fit(X4,y4)
#输出最大迭代次数
print(MLP_clf4.n_iter_)
plt.figure(figsize=(10,10))
plt.subplot(2,2,1)
plot_decision_boundary(MLP_clf1,X1, y1)
plt.subplot(2,2,2)
plot_decision_boundary(MLP_clf2,X2, y2)
plt.subplot(2,2,3)
plot_decision_boundary(MLP_clf3,X3, y3)
plt.subplot(2,2,4)
plot_decision_boundary(MLP_clf4,X4, y4)

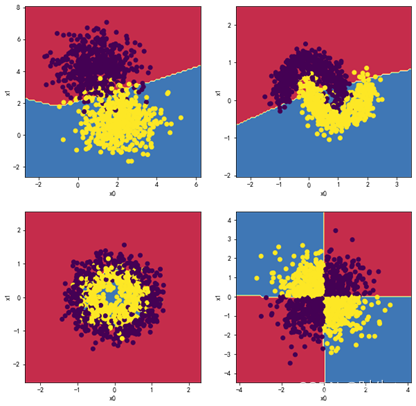
1.4观察四层,每层两个神经元效果:
MLP_clf1 = MLPClassifier(hidden_layer_sizes = (2,2,2,2),max_iter = 2000)
#输出用时
%time MLP_clf1.fit(X1,y1)
#输出最大迭代次数
print(MLP_clf1.n_iter_)
MLP_clf2 = MLPClassifier(hidden_layer_sizes = (2,2,2,2),max_iter = 2000)
#输出用时
%time MLP_clf2.fit(X2,y2)
#输出最大迭代次数
print(MLP_clf2.n_iter_)
MLP_clf3 = MLPClassifier(hidden_layer_sizes = (2,2,2,2),max_iter = 2000)
#输出用时
%time MLP_clf3.fit(X3,y3)
#输出最大迭代次数
print(MLP_clf3.n_iter_)
MLP_clf4 = MLPClassifier(hidden_layer_sizes = (2,2,2,2),max_iter = 2000)
#输出用时
%time MLP_clf4.fit(X4,y4)
#输出最大迭代次数
print(MLP_clf4.n_iter_)
plt.figure(figsize=(10,10))
plt.subplot(2,2,1)
plot_decision_boundary(MLP_clf1,X1, y1)
plt.subplot(2,2,2)
plot_decision_boundary(MLP_clf2,X2, y2)
plt.subplot(2,2,3)
plot_decision_boundary(MLP_clf3,X3, y3)
plt.subplot(2,2,4)
plot_decision_boundary(MLP_clf4,X4, y4)

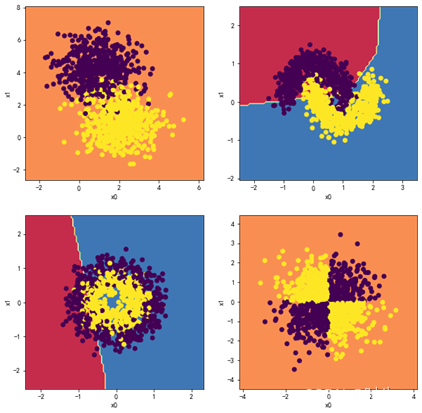
分析:
出现了不收敛的错误分类现象,原因见实验总结。
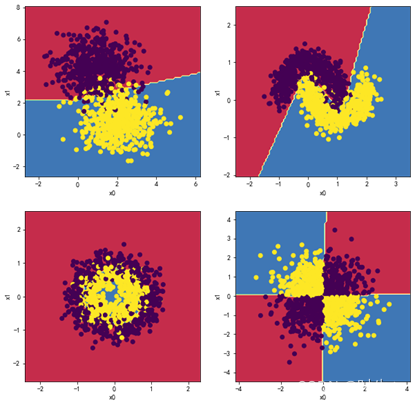
1.5观察四层,每层五个神经元效果:
MLP_clf1 = MLPClassifier(hidden_layer_sizes = (5,5,5,5),max_iter = 2000)
#输出用时
%time MLP_clf1.fit(X1,y1)
#输出最大迭代次数
print(MLP_clf1.n_iter_)
MLP_clf2 = MLPClassifier(hidden_layer_sizes = (5,5,5,5),max_iter = 2000)
#输出用时
%time MLP_clf2.fit(X2,y2)
#输出最大迭代次数
print(MLP_clf2.n_iter_)
MLP_clf3 = MLPClassifier(hidden_layer_sizes = (5,5,5,5),max_iter = 2000)
#输出用时
%time MLP_clf3.fit(X3,y3)
#输出最大迭代次数
print(MLP_clf3.n_iter_)
MLP_clf4 = MLPClassifier(hidden_layer_sizes = (5,5,5,5),max_iter = 2000)
#输出用时
%time MLP_clf4.fit(X4,y4)
#输出最大迭代次数
print(MLP_clf4.n_iter_)
plt.figure(figsize=(10,10))
plt.subplot(2,2,1)
plot_decision_boundary(MLP_clf1,X1, y1)
plt.subplot(2,2,2)
plot_decision_boundary(MLP_clf2,X2, y2)
plt.subplot(2,2,3)
plot_decision_boundary(MLP_clf3,X3, y3)
plt.subplot(2,2,4)
plot_decision_boundary(MLP_clf4,X4, y4)

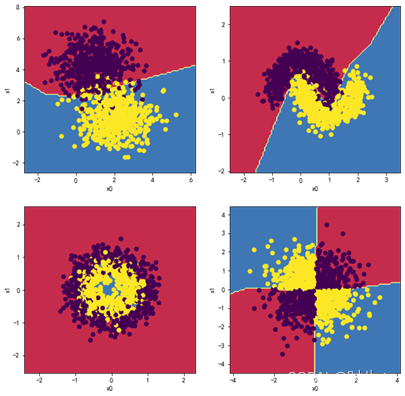
1.6观察四层,每层十个神经元效果:
MLP_clf1 = MLPClassifier(hidden_layer_sizes = (10,10,10,10),max_iter = 2000)
#输出用时
%time MLP_clf1.fit(X1,y1)
#输出最大迭代次数
print(MLP_clf1.n_iter_)
MLP_clf2 = MLPClassifier(hidden_layer_sizes = (10,10,10,10),max_iter = 2000)
#输出用时
%time MLP_clf2.fit(X2,y2)
#输出最大迭代次数
print(MLP_clf2.n_iter_)
MLP_clf3 = MLPClassifier(hidden_layer_sizes = (10,10,10,10),max_iter = 2000)
#输出用时
%time MLP_clf3.fit(X3,y3)
#输出最大迭代次数
print(MLP_clf3.n_iter_)
MLP_clf4 = MLPClassifier(hidden_layer_sizes = (10,10,10,10),max_iter = 2000)
#输出用时
%time MLP_clf4.fit(X4,y4)
#输出最大迭代次数
print(MLP_clf4.n_iter_)
plt.figure(figsize=(10,10))
plt.subplot(2,2,1)
plot_decision_boundary(MLP_clf1,X1, y1)
plt.subplot(2,2,2)
plot_decision_boundary(MLP_clf2,X2, y2)
plt.subplot(2,2,3)
plot_decision_boundary(MLP_clf3,X3, y3)
plt.subplot(2,2,4)
plot_decision_boundary(MLP_clf4,X4, y4)

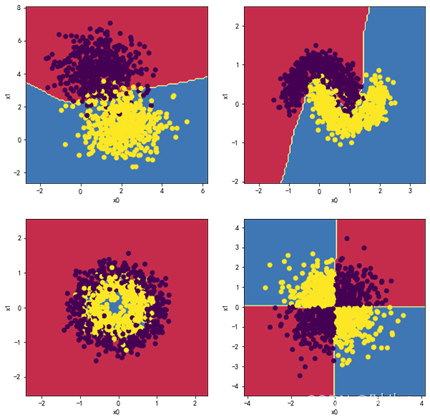
结论:
经过对比发现,当增加每个隐藏层的神经元数量和增加神经网络隐藏层数时,都对分类的精细度起到了提升作用;但要注意,当神经元数或隐藏层数过大时,对划分的精细度提升效果不大,反而会带来过拟合风险。
2.针对太极数据集,但是噪声程度不一样
针对不同噪声下的太极数据集,对比2层隐藏层下不同神经元个数(2,2),(5,5),(10,10)以及4层神经元(2,2,2,2),(5,5,5,5),(10,10,10,10),对比分类效果,以及每个模型的迭代次数和训练时间,然后给出分析结论。
#2.太极数据集
X5,y5 = datasets.make_moons(n_samples=1000,noise=0.1,random_state=666)
X6,y6 = datasets.make_moons(n_samples=1000,noise=0.3,random_state=666)
plt.figure(figsize=(10,4))
plt.subplot(1,2,1)
plt.scatter(X5[y5==0,0],X5[y5==0,1])
plt.scatter(X5[y5==1,0],X5[y5==1,1])
plt.subplot(1,2,2)
plt.scatter(X6[y6==0,0],X6[y6==0,1])
plt.scatter(X6[y6==1,0],X6[y6==1,1])
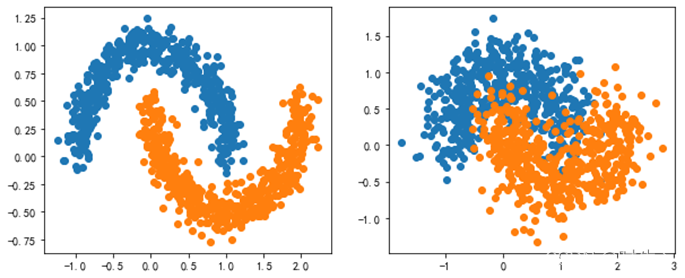
2.1观察两层,每层两个神经元效果:
MLP_clf5 = MLPClassifier(hidden_layer_sizes = (2,2),max_iter = 2000)
#输出用时
%time MLP_clf5.fit(X5,y5)
#输出最大迭代次数
print(MLP_clf5.n_iter_)
MLP_clf6 = MLPClassifier(hidden_layer_sizes = (2,2),max_iter = 2000)
#输出用时
%time MLP_clf6.fit(X6,y6)
#输出最大迭代次数
print(MLP_clf6.n_iter_)
plt.figure(figsize=(10,4))
plt.subplot(1,2,1)
plot_decision_boundary(MLP_clf5,X5, y5)
plt.subplot(1,2,2)
plot_decision_boundary(MLP_clf6,X6, y6)
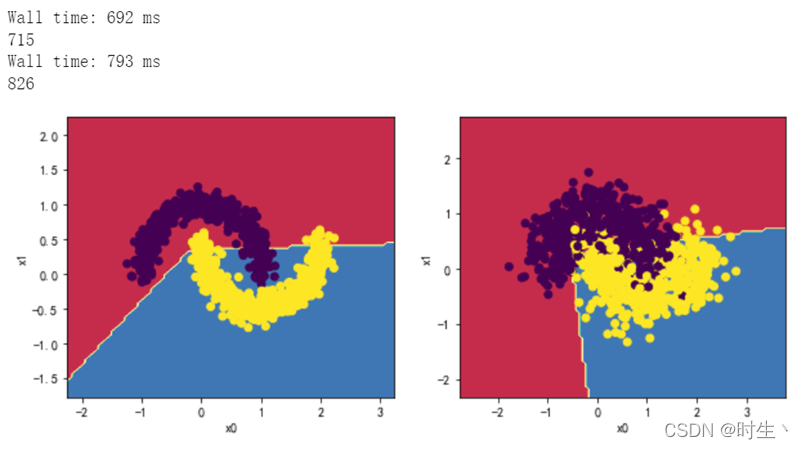
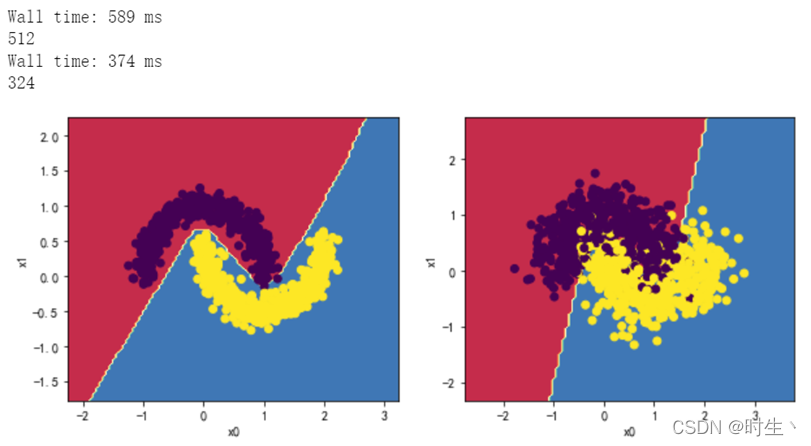
2.2观察两层,每层五个神经元效果:
MLP_clf5 = MLPClassifier(hidden_layer_sizes = (5,5),max_iter = 2000)
#输出用时
%time MLP_clf5.fit(X5,y5)
#输出最大迭代次数
print(MLP_clf5.n_iter_)
MLP_clf6 = MLPClassifier(hidden_layer_sizes = (5,5),max_iter = 2000)
#输出用时
%time MLP_clf6.fit(X6,y6)
#输出最大迭代次数
print(MLP_clf6.n_iter_)
plt.figure(figsize=(10,4))
plt.subplot(1,2,1)
plot_decision_boundary(MLP_clf5,X5, y5)
plt.subplot(1,2,2)
plot_decision_boundary(MLP_clf6,X6, y6)
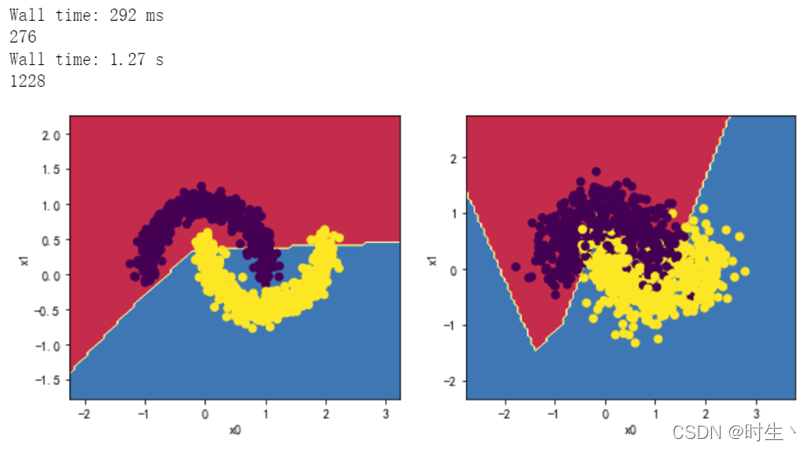
2.3观察两层,每层十个神经元效果:
MLP_clf5 = MLPClassifier(hidden_layer_sizes = (10,10),max_iter = 2000)
#输出用时
%time MLP_clf5.fit(X5,y5)
#输出最大迭代次数
print(MLP_clf5.n_iter_)
MLP_clf6 = MLPClassifier(hidden_layer_sizes = (10,10),max_iter = 2000)
#输出用时
%time MLP_clf6.fit(X6,y6)
#输出最大迭代次数
print(MLP_clf6.n_iter_)
plt.figure(figsize=(10,4))
plt.subplot(1,2,1)
plot_decision_boundary(MLP_clf5,X5, y5)
plt.subplot(1,2,2)
plot_decision_boundary(MLP_clf6,X6, y6)
2.4观察四层,每层两个神经元效果:
MLP_clf5 = MLPClassifier(hidden_layer_sizes = (2,2,2,2),max_iter = 2000)
#输出用时
%time MLP_clf5.fit(X5,y5)
#输出最大迭代次数
print(MLP_clf5.n_iter_)
MLP_clf6 = MLPClassifier(hidden_layer_sizes = (2,2,2,2),max_iter = 2000)
#输出用时
%time MLP_clf6.fit(X6,y6)
#输出最大迭代次数
print(MLP_clf6.n_iter_)
plt.figure(figsize=(10,4))
plt.subplot(1,2,1)
plot_decision_boundary(MLP_clf5,X5, y5)
plt.subplot(1,2,2)
plot_decision_boundary(MLP_clf6,X6, y6)
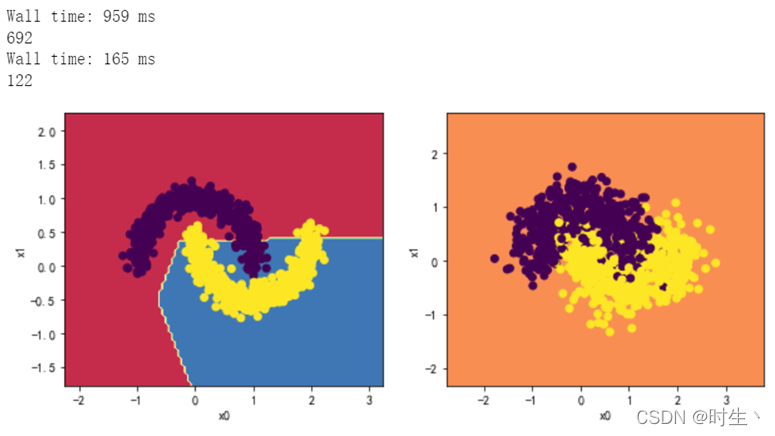
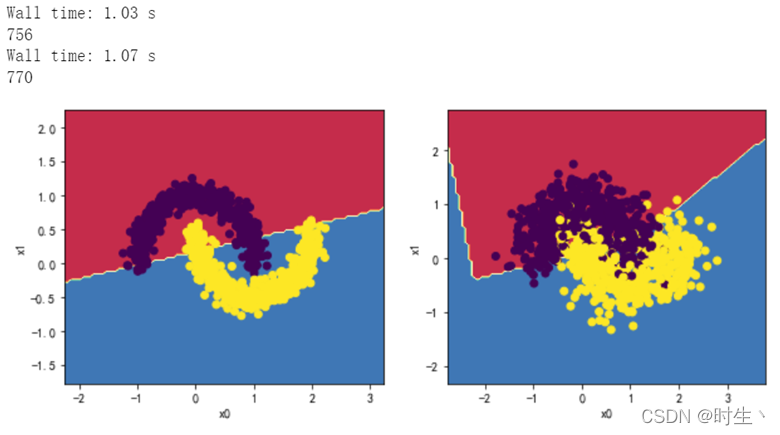
分析:
出现了不收敛的错误分类现象,重复实验可以发现不是每次都会出现该现象,原因见实验总结。
2.5观察四层,每层五个神经元效果:
MLP_clf5 = MLPClassifier(hidden_layer_sizes = (2,2,2,2),max_iter = 2000)
#输出用时
%time MLP_clf5.fit(X5,y5)
#输出最大迭代次数
print(MLP_clf5.n_iter_)
MLP_clf6 = MLPClassifier(hidden_layer_sizes = (2,2,2,2),max_iter = 2000)
#输出用时
%time MLP_clf6.fit(X6,y6)
#输出最大迭代次数
print(MLP_clf6.n_iter_)
plt.figure(figsize=(10,4))
plt.subplot(1,2,1)
plot_decision_boundary(MLP_clf5,X5, y5)
plt.subplot(1,2,2)
plot_decision_boundary(MLP_clf6,X6, y6)

2.6观察四层,每层十个神经元效果:
MLP_clf5 = MLPClassifier(hidden_layer_sizes = (5,5,5,5),max_iter = 2000)
#输出用时
%time MLP_clf5.fit(X5,y5)
#输出最大迭代次数
print(MLP_clf5.n_iter_)
MLP_clf6 = MLPClassifier(hidden_layer_sizes = (5,5,5,5),max_iter = 2000)
#输出用时
%time MLP_clf6.fit(X6,y6)
#输出最大迭代次数
print(MLP_clf6.n_iter_)
plt.figure(figsize=(10,4))
plt.subplot(1,2,1)
plot_decision_boundary(MLP_clf5,X5, y5)
plt.subplot(1,2,2)
plot_decision_boundary(MLP_clf6,X6, y6)
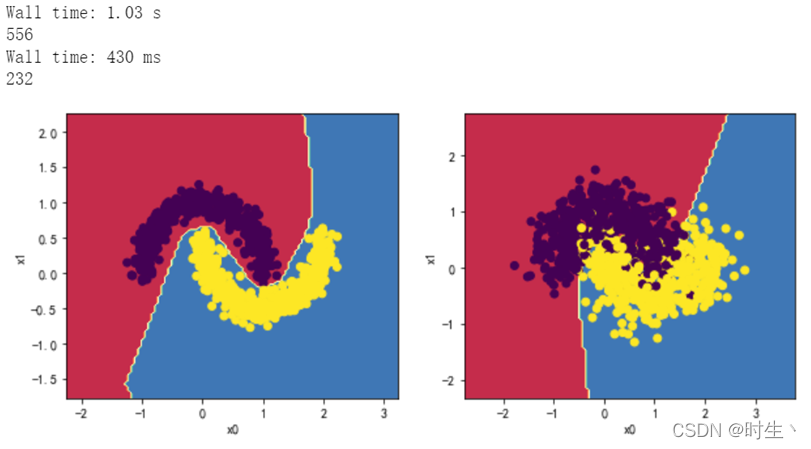
结论:
通过上面实验同样可以看出,神经元数的增加能够有效地提高边界划分的精度;而深层的神经网络又可以通过特征的补充来让边界更加灵活且适应复杂情况,拟合效果也有所提升;
并且我们可以看到当只是提升隐藏层数而没有提升每层神经元数量时,很容易出现错误情况,即过多的层数导致函数出现不收敛。
四、实验总结
- 异常情况:
在四隐藏层且每层两个神经元时出现了明显的不收敛现象,这既不属于欠拟合也不属于过拟合,这两种情况是模型对训练集学习的效果不好;而不收敛可以理解为模型根本没有学到,不能说效果好不好; - 分析原因:
神经网络在进行训练集训练时,其实是在用已知的样本数据计算模型最佳参数,即权重ω与偏置量b,而上述的迭代次数则是利用梯度下降法找寻稳定的最佳参数时所迈的“步数”;不收敛现象我们可以解释为模型最终的参数没有趋于稳定,为什么在神经元数较多时不会出现这一现象,目前分析是因为模型在每一个隐藏层有足够多数量的权重值可以平衡某一异常权重,此时最终权重值不易出现错误。(后续深入学习将更新) - 结语:
通过本次实验,学生了解了神经网络基本的实现与应用,并且知道了神经元数量与隐藏层数对神经网络模型的影响,收获颇丰。















 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









