






文本分类概述(NLP)
**文本分类问题:**给定文档p,将文档分类为n个类别中的一个或多个
**文本分类应用:**常见的有垃圾邮件识别,情感分析
**文本分类方向:**主要有二分类,多分类,多标签分类
**本分分类方法:**传统机器学习方法(贝叶斯、SVM等),深度学习方法(fastText,TextCNN等)
**本文的思路:**本文主要介绍文本分类的处理过程,主要哪些方法。致力让读者明白在处理文本分类问题时应该从什么方向入手,重点关注什么问题,对于不同的场景应该采用什么方法。
文本分类的处理大致分为文本预处理、文本特征处理、分类模型构建等。
中文分词:
基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
1、基于字符串匹配的分词方法,将句子拆分成多个部分,将每一个部分与字典一一对应,如果该词语在词典中,分词成功,否则继续拆分匹配直到成功。
2、基于理解的分词方法:基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。基本思想就是在分词的同时,进行句法、语义分析,利用句法信息和语义信息处理歧义现象。通常包括三个部分:分词子系统、句法语义子系统、总控部分。
3、基于统计的分词方法:
过程:统计学认为分词是一个概率最大化的问题,即拆分句子,基于语料库,统计相邻的字组成的词语出现的概率,相邻的词出现的次数多,就出现的概率大。
主要的统计模型有:N元语法模型,隐马尔可夫模型,最大熵模型,条件随机场。
文本预处理
1、分词:中文任务分词必不可少,一般使用Jieba分词,工业界的翘楚。
2、去停用词:建立停用词字典。
3、词性标注:分词后判断词性,使用jieba的时候设置参数就能获取。
文本特征工程
1、基于词袋的特征表示。TF-IDF模型
2、基于embedding的特征表示:通过词向量计算文本的特征。
3、基于NN Model抽取的特征:NN的好处在于能end2end实现模型的训练和测试,利用模型的非线性和众多参数来学习特征,不需要手工提取特征。
特征融合
对于特征维数较高、数据模式复杂的情况,建议用非线性模型(GDBT,XGboost);对于特征维数较低,数据模式简单的情况,建议用简单的线性模型即可(如LR)。
深度学习文本分类
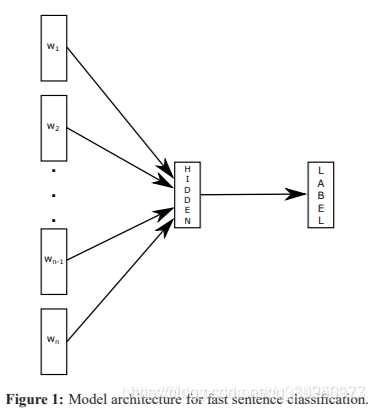
1、fastText模型:句子中所有的词向量进行平均,然后直接连接一个softmax层进行分类。
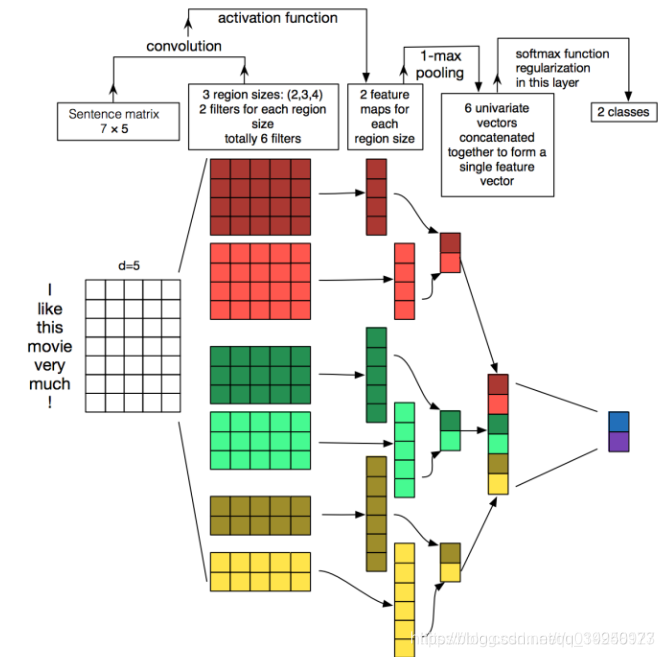
2、TextCNN:利用CNN来提取句子中类似n-gram的关键信息。
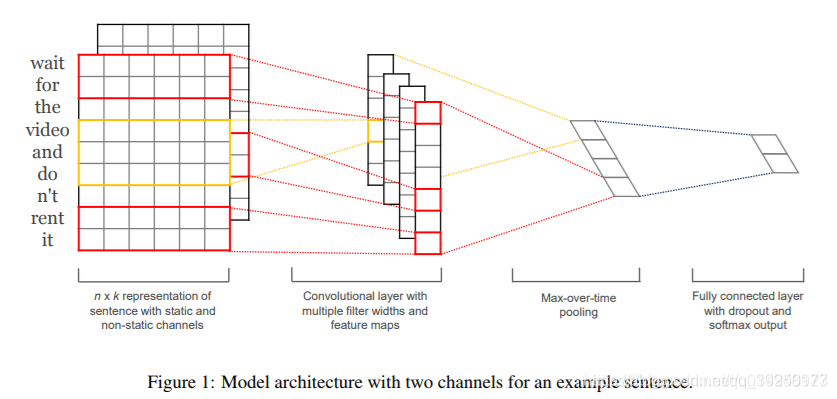
3、TextRNN:Bi-di’rectional RNN从某种意义上可以理解为可以捕获变长且双向的“n_gram”信息。
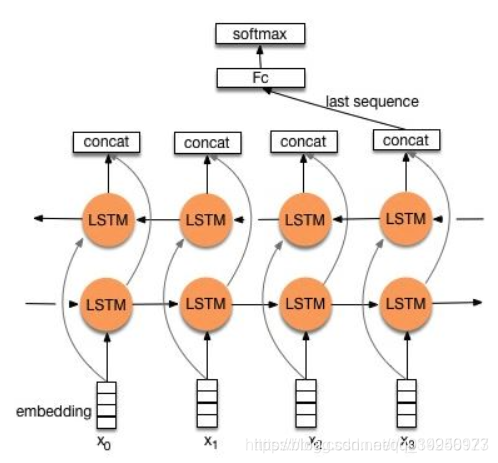
4、TextRNN+Attention:注意力机制是自然语言处理领域一个常用的建模长时间记忆机制,能够直观的给出每个词的贡献,基本成了seq2seq模型的标配了。实际上文本分类从某种意义上也可以理解为一种特殊的seq2seq,所以考虑从把Attention引入进来。
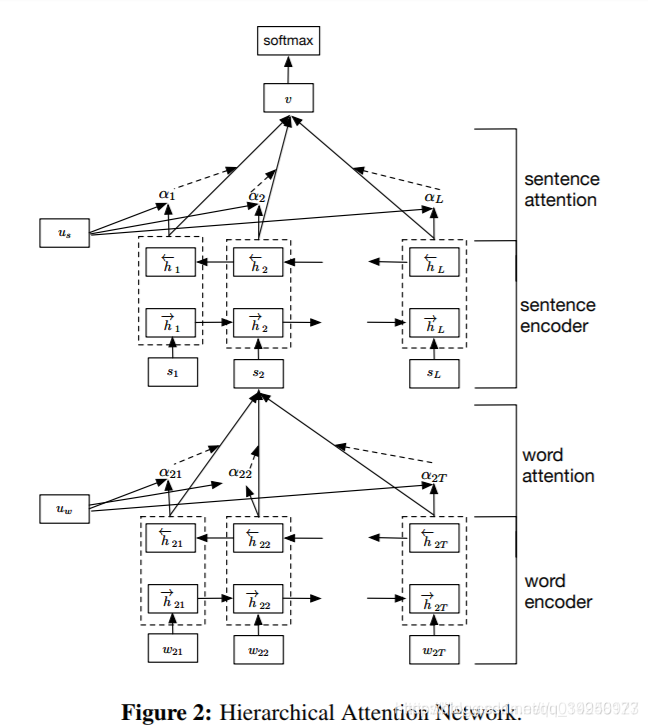
最后
1、模型并不是最重要的,TextCNN已经能取得不错的结果。
2、理解你的数据。
3、一定要用dropout
4、未必一定要softmax loss
5、类目不均衡问题。
6、避免训练震荡。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









