







导读
本文来自社区投稿,作者:布鲁瓦丝
社区小伙伴在 Windows 环境使用 MMClassification 和 MMDetection 都轻轻松松的,但在走完 MMSegmentation 全流程之后,却感叹“踩了不少坑”?这是怎么回事呢?
他把自己的遇坑经验凝练总结出来,写下了这篇专门给新手无伤通关的避坑教程。感谢他的分享,我们快来一起学习下吧~
https://github.com/open-mmlab/mmsegmentationgithub.com/open-mmlab/mmsegmentation
目录
Windows 配置环境的痛:mmcv-full
在 v1.4.0 之前,mmcv-full 的安装没有针对 Windows 的现成预编译包,所以大部分新手会卡在 build MMCV 的过程中......这种情况下有两种解决方案。
方案 1:新版编译版本自动安装
在 1.4.0 之后,MMCV 会跟上 PyTorch 版本更新 Windows 环境下的mmcv-full预编译包,但是可用的版本范围比较局限,依赖 PyTorch、CUDA、mmcv-full 低版本的炼丹师自然就不适合这种安装方式了(看方案2),下面是以 PyTorch1.11.0、 CUDA11.3 为例的安装命令。
- 一句命令安装
mmcv-full,下载速度还是不错的
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.11/index.html
方案 2:手动操作
如果你不希望更新到新版 MMSegmentation 或者 MMCV,也可以尝试手动安装,下面以在 GPU+CPU 双环境运行的目标来安装 mmcv-full,参考了官方文档,所有命令行运行在 powershell,使用 cmd 的炼丹师需要注意两个命令行的命令差异。
- 创建虚拟环境
conda create --name mmcv python=3.7 # 经测试,3.6, 3.7, 3.8 也能通过
conda activate mmcv # 确保做任何操作前先激活环境- 进入一个临时文件路径,克隆
mmcv-full源码
git clone https://github.com/open-mmlab/mmcv.git
cd mmcv # 进入项目文件夹- 安装依赖
所有依赖中,也安装了 ninja 库用于加快最后编译的速度
pip install -r requirements.txt #
建议使用镜像加速 => pip install -r requirements.txt -i https://pypi.douban.com/simple- 配置编译环境
安装 Microsoft Visual Studio Community 2017/2019/...... ,确保环境变量中的 Path 存在编译所需的值。以 VS2019 Community 为例:C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.27.29110\bin\Hostx86\x64 。
- 编译安装
mmcv-full
$env:MMCV_WITH_OPS = 1
$env:MAX_JOBS = 8 # 根据可用的CPU和内存量进行设置
python setup.py build_ext # 如果成功, 将会自动弹出来编译 flow_warp
python setup.py develop # 执行安装- 检测是否安装成功
pip list # 使用anaconda的话,也可以在openmmlab依赖的虚拟环境下 => conda list数据集自定义类别
更改 CLASSES 和 num_classes
不敢调试的新手炼丹师首次面对 mmseg 的项目可能无所适从,因此也很难养成自己编写数据集加载代码的习惯。其实能搜到很多水平不一的资料教你编辑现有的数据集加载方式(比如常见的 ADEDataset),修改 CLASSES,然后设置 num_classes,可能更改完发现编辑后的代码根本没应用上,网络 decoder 不断吐槽你 num_classes 不对,然后你又去检查手里的数据集......其实是因为认识较浅,下面展示更合理的走通指南:
- 选择好模型后,先把相关联配置文件里的全部
num_classes设置好值,比如经典 ADE 数据集提取并划分了 150 个实例类,num_classes就是150,计入num_classes的所有类的名称下一步都要写入CLASSES。(背景类未算入 150,下一节会讲解为什么) - 下面,进入
mmseg项目下的mmseg/datasets,以遥感语义分割任务为例新建 py 文件uavdataset.py, 继承自custom.py中的CustomDataset,然后开始实现自己的数据集......在定义CLASSES的时候, tuple 初始化为自己类名的集合即可(比如关于街区 block、农田 field 和其他利用地 notused 的遥感语义分割任务),用于上色的PALETTE也可以用类似的方式配置(配置格式:[R, G, B])。
# mmseg/datasets/uavdataset.py
...
CLASSES = ('block', 'field', 'notused')
PALETTE = [[120, 120, 120], [180, 120, 120], [120, 180, 120]]
...- 然后参考
configs/_base_/datasets的其他配置文件编写uavdataset.py作为UAVDataset的配置文件。最后,在选用的模型配置文件中更换数据集加载方式为UAVDataset。
对源码的增改没有效果?
- OpenMMLab 各种工具箱的官方文档中,都会教你用
pip install -v -e .安装项目,但很多新手对pip的这种命令并不了解。其实这个命令是用来开启mmseg库编辑模式的,这样修改mmseg库内的代码片段可以自动被应用上,无需重新安装(如图截取自 MMSegmentation 官方文档的安装教程,其中注释已经解释了这种 pip 命令的含义)。
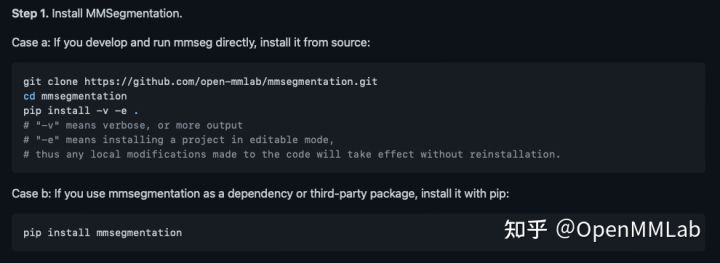
- 切记!使用
python setup.py install安装的mmseg每次编辑源码都需要重新安装,这也是为什么大部分新手更改CLASSES却不生效的原因,建议换用以下安装方法 :
cd ~/mmsegmentation-master/ # 进入你的mmseg项目路径下
pip install -v -e . # 重新安装 英文句点表示安装当前路径下的项目
- 也有可能会有小伙伴问可不可以用
python setup.py develop,我没做过实验。但是setup.py也是门学问,既然官方文档教新手们用pip的方式就能成,也就没必要找太多替换方案了,新手上来没必要钻研在这上面。
独特的数据集参数:reduce_zero_label
借助 reduce_zero_label 管理 0 值背景
mmseg 中已经为各种公共分割数据集编写了描述文件和加载代码,对于有用过 PyTorch 的小伙伴而言,学习各种数据集的描述文件还是很自如的,只有 reduce_zero_label 对于 mmseg 的新手比较陌生,所以,在搭建自己的 mmseg 数据集时,新手最疑惑的大概就是 reduce_zero_label 到底应该是 True 还是 False。
它有什么用呢?从名字直译过来就是“减少 0 值标签”。在多类分割任务中,如果你的数据集中 0 值作为 label 文件中的背景类别,是建议忽略的。
打开加载数据的源码片段可以看到一段处理 reduce_zero_label 的代码,意思是:若开启了 reduce_zero_label,原本为 0 的所有标注设置为 255,也就是损失函数中 ignore_index 参数的默认值,该参数默认避免值为 255 的标注参与损失计算。前文按下不表的 150 类的 ADE 数据集,它不包含背景的原因就是开了 reduce zero label,原本为 0 值的背景设置为了 ignore_index。
# mmseg/datasets/pipelines/loading.py
...
# reduce zero_label
if self.reduce_zero_label:
# avoid using underflow conversion
gt_semantic_seg[gt_semantic_seg == 0] = 255
gt_semantic_seg = gt_semantic_seg - 1
gt_semantic_seg[gt_semantic_seg == 254] = 255
...
reduce_zero_label 导致的常见问题描述
我们这里以 ADE 数据集源码为例,reduce_zero_label 默认设置为 True,然而,就算新手掌握了上一节的 reduce_zero_label,也可能对 ADE 了解比较肤浅,会怀疑配置文件中开启的 reduce_zero_label 是不是把 150 个实例类中的第一个给忽略掉了,毕竟 num_classes 不就是 150 吗,然后想当然把 reduce_zero_label 关掉。
错误原因分析
# configs/_base_/datasets/ade20k.py
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', reduce_zero_label=True), # ADE中reduce_zero_label默认设置为True
dict(...),
...
]
label 中实际参加训练的确实只有 150 类,定义在 CLASSES 中,但 label 文件中实际包含了 151 类,而背景类(剩下仍没有标记的,或者被意外忽略的区域都归为背景,在 label 中值为 0)不包含在 150 个 CLASSES 中,需要在训练的时候设置成 ignore_index,所以我们借助上一小节的 reduce_zero_label 将背景从 151 个类中提出来单独设置为了 ignore_index,我们倘若错误地将 reduce_zero_label 关掉了,那 num_classes 就是 151 了。
如何增强对数据集更多参数的理解?
实际工程中的数据集往往是我们自己设计预测类别和标注规则的,如果背景真的很重要,那无论是修改 ADE 的配置文件,还是硬搬 ADE 格式数据集的使用方式,都不如尊重开发者写好的数据集加载代码,改用自己编写的数据集加载方式(只需继承自 CustomDataset 即可)。
在一行行编写的过程中,新手炼丹师可以不断参考研究现存的其他数据集的解决方案,如果遇到不懂的地方也能有查漏补缺的方向,尤其是 reduce_zero_label 这种参数,需要充分理解消化才能运用自如。不断尝试尝试尝试的过程中,新手炼丹师也会对各式各样的数据集加载方式产生自己的理解和看法,在迎接特殊任务的时候能够分析自己的数据集,创新设计出自己独特的数据集加载方式。
数据集文件后缀的坑:大小写
接着看 mmseg/datasets 的 ade.py,这里 ADE20KDataset 类有两个 suffix(文件后缀)相关的参数配置,img_suffix 负责定义图像文件的后缀名,seg_map_suffix 定义标签文件的后缀名。默认配置:
# mmseg/datasets/ade.py
...
def __init__(self, **kwargs):
super(ADE20KDataset, self).__init__(
img_suffix='.jpg', # 图像的后缀名
seg_map_suffix='.png', # 标签的后缀名
reduce_zero_label=True,
**kwargs)
...但是有些炼丹师拿到的图像后缀是 .JPG,它和 .jpg 的区别仅仅是大小写不同,但是数据集加载会不断报 FileNotFound 的错误。所以新手遇到此类报错一定要注意大小写差异,直接修改配置文件中的 suffix 相关参数即可。
日志可视化
经常可以看到社区的小伙伴在问训练遇到的问题,而且喜欢直接对终端的日志截图,就算是巨佬也不一定对一长串数字敏感。当我遇到这类情况一般会教他们去官方文档找可视化的章节,学习官方提供的绘制日志曲线图的脚本。但是运行脚本可视化是很麻烦的,使用的教程很少还很容易报错,而 tensorboard 可视化库是各工具箱都通用的,可以一句命令可视化训练过程的各种指标,并展示在统一的本地网页上,也给新手提供了更好展现自己训练问题的手段,在 mmseg 使用 tensorboard 的方法也很简单:
- 在
config/_base_中找到default_runtime.py,第 6 行一般默认是注释起来的,将这行取消注释也就开启了 tensorboard 记录,以后启动的训练都会在work_dirs的对应文件夹中生成tf_log文件夹。
# config/_base_/default_runtime.py
# yapf:disable
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook', by_epoch=False),
dict(type='TensorboardLoggerHook') # 启动tensorboard记录(该行一般默认被注释起来)
])
# yapf:enable
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
cudnn_benchmark = True
- 那么这个
tf_log文件夹怎么使用呢?我们只需要复制绝对路径,打开终端,切换到 OpenMMLab 所依赖的环境,并安装tensorboard的 python 库。
pip install tensorboard- 然后将 tensorboard 日志部署到本地 IP 和端口。
tensorboard --logdir {TF_LOG_PATH} # TF_LOG_PATH替换为自己的tf_log文件夹绝对路径即可执行成功之后可以看到终端打印了一个本地 IP 和端口,默认是 http://localhost:6006/,按住 ctrl 键鼠标点击即可进入浏览器打开可视化页面,终端连续多次按下 ctrl + c 组合键可以停止 tensorboard 服务。
后记
我使用 OpenMMLab 各种工具箱的时候编写的几个辅助脚本在我的 GitHub,涵盖了数据集预处理、维护和质检等功能,大家可以去看看有没有能帮上自己的。 MMSegmentation 的大小坑真的让我哭笑不得哈哈哈,也辛苦 MMSegmentation 开源开发者的付出,祝自己有一天能加入 OpenMMLab 的大家庭一起维护这个开源之星,也祝各位炼丹师实验顺利。
系列传送门
OpenMMLab:超详细!带你轻松掌握 MMSegmentation 整体构建流程68 赞同 · 10 评论文章正在上传…重新上传取消
OpenMMLab:超详细!手把手带你轻松用 MMSegmentation 跑语义分割数据集26 赞同 · 2 评论文章正在上传…重新上传取消














 2225
2225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









