







python笔记4
1.read()、readline()与readlines()
read([size]), 从文件当前位置读取size个字节,如果未给定或为负则读取所有,返回从字符串中读取的字节。
readline(),每次读出一行内容,包括 “\n” 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 “\n” 字符。返回从字符串中读取的字节。
读取时内存占用小,比较适合打文件,每次返回一个字符串对象。
readlines(),读取整个文件所有行,直到结束符 EOF,保存在一个list中,每行作为一个元素。读取大文件会比较占内存。

linecache模块 比如像输出文件的第n行
对于open()的打开方式

2.split()和splitlines()
1)str.split(str="", num=string.count(str))
str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num – 分割次数。默认为 -1, 即分隔所有。
返回分割后的字符串列表。
2)S.splitlines([keepends = False])
keepends:在输出结果里是否包含行界符(\r’, ‘\r\n’, \n’),默认为False,不包含。返回包含各行作为元素的列表。

3.list的::
这个是python的slice notation的特殊用法。
a = [0,1,2,3,4,5,6,7,8,9]
b = a[i:j] 表示复制a[i]到a[j-1],以生成新的list对象
b = a[1:3] 那么,b的内容是 [1,2]
当i缺省时,默认为0,即 a[:3]相当于 a[0:3]
当j缺省时,默认为len(alist), 即a[1:]相当于a[1:10]
当i,j都缺省时,a[:]就相当于完整复制一份a了
b = a[i:j:s]这种格式呢,i,j与上面的一样,但s表示步进,缺省为1.
所以a[i:j:1]相当于a[i:j]
当s<0时,i缺省时,默认为-1. j缺省时,默认为-len(a)-1
所以a[::-1]相当于 a[-1:-len(a)-1:-1],也就是从最后一个元素到第一个元素复制一遍。所以你看到一个倒序的list。
例如,[3::-1], 表示以第3个为起点,往前输出index为3、2、1、0的数
l = [1, 2,3 ,4, 5, 6]
print(l[3::-1])
[4, 3, 2, 1]
3.continue 和 break
两者都用在for和while循环中。
continue跳出本次循环,也就是说对于本次循环,continue后的语句都不会执行。
break终止循环,即循环条件没有False条件或者序列还没被完全递归完,也会停止执行循环语句。如果使用嵌套循环,break语句将停止执行最深层的循环,并开始执行下一行代码。

4.join()
S.join(X),X为包含多个字符串的可迭代对象
将X转为用分隔符S链接的字符串。
tt = ["12", "345", "67"]
cc = ''.join(tt)
ee = '?'.join(tt)
print(cc)
print(ee)
12345678
12?345?678
5.itemgetter()
from operator import itemgetter
来自于operator模块的函数,用于获取对象的某些维度的数据,参数是一些序号
a = [1,2,3]
b = itemgetter(1) //定义函数b,获取对象的第2个域的值
b(a)
2
b = itemgetter(1,0) //定义函数b,获取对象的第2个域和第1个的值
b(a)
(2, 1)
要注意,operator.itemgetter函数获取的不是值,而是定义了一个函数,通过该函数作用到对象上才能获取值。
可以用在sorted函数里
Python内置的排序函数sorted可以对list或者iterator进行排序
sorted(iterable[, cmp[, key[, reverse]]])
参数解释:
1)iterable指定要排序的list或者iterable
2)cmp为函数,指定排序时进行比较的函数,可以指定一个函数或者lambda函数
cmp函数也可以用operator.itemgetter来实现,例如
通过student的第三个域排序:
sorted(students, key=operator.itemgetter(2))
sorted函数也可以进行多级排序,例如要根据第二个域和第三个域进行排序,可以这么写:
sorted(students, key=operator.itemgetter(1,2))
6.关于字典
1)对于键值对
值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
2)dict.items()
返回可遍历的(键, 值) 元组list
d = {'1': 10, '2': 20, '3':30}
print(d.items())
dict_items([('1', 10), ('2', 20), ('3', 30)])
3)dict.has_key(key)
key存在,返回True;否则,返回False
4)dict.keys()
返回所有的键组成的list
d = {'1': 10, '2': 20, '3':30}
print(d.items())
dict_keys(['1', '2', '3'])
7.关于列表
1)list.append(obj)
在列表末尾添加新的一个对象
2)list.extend(seq)
在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
8.关于python的 *星号
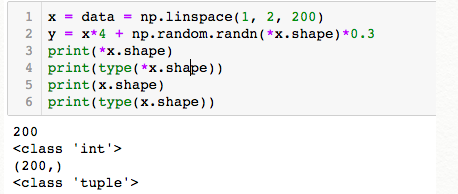
个人理解,*是解一层方括号的作用,但是两个*不会解两个方括号

对元组也适用,shape函数返回的是tuple















 1695
1695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









