






如果是单机,直接看附件操作即可!!!
一、规定主节点和从节点(例如:主节点10.1.4.146,次节点10.1.4.168)
二、次节点备份主节点模型文件、数据文件,保证所有路径在各台机器一致
三、保证各节点cuda版本、torch版本 、python、MMCV版本环境一致
cuda11.8+ torch2.0.0 +python 3.8 +MMCV2.0.0rc4 +mmsegmentation1.2.2
四、设置主节点、从节点之间可以实现ssh无密码访问
1. 确保SSH服务正常运行(在两台机器上分别执行)
sudo systemctl start sshd # 启动SSH服务
sudo systemctl enable sshd # 设置开机自启
2. 生成SSH密钥对(在两台机器上分别执行)
ssh-keygen -t rsa -b 4096
执行后会提示:
Enter file in which to save the key (/home/username/.ssh/id_rsa): [直接回车]
Enter passphrase (empty for no passphrase): [直接回车]
Enter same passphrase again: [直接回车]
3. 将公钥复制到对方机器
在机器A上执行:
ssh-copy-id username@machineB_IP
在机器B上执行:
ssh-copy-id username@machineA_IP
五、开放29500端口,保证主、从节点之间数据访问传输(在两台机器上分别执行)
sudo ufw allow 29500/tcp
sudo ufw disable 关闭防火墙
验证端口是否真正开放
在10.1.4.146 上监听端口:
nc -l 29500
在另一台机器测试连接:
ping 10.1.4.146
nc -zv 10.1.4.146 29500
六、NCCL 网络通信
1. 显式指定网卡接口
NCCL 无法自动选择网卡时,需要手动指定:
# 查看可用网卡名称
ip -br a
# 设置环境变量(以 enp0s31f6为例)
export NCCL_SOCKET_IFNAME=enp0s31f6
export GLOO_SOCKET_IFNAME=enp0s31f6
2. 禁用 InfiniBand(非IB环境)
如果未使用 InfiniBand 网络,强制禁用:
export NCCL_IB_DISABLE=1
3.整体代码(如果后续报NCLL网络问题,执行一下这几行命令即可)
export NCCL_SOCKET_IFNAME=enp0s31f6
export GLOO_SOCKET_IFNAME=enp0s31f6
export NCCL_IB_DISABLE=1
export NCCL_DEBUG=INFO
export NCCL_P2P_DISABLE=1
七、临时共享文件夹.dist_test 创建(用于主节点从次节点取相关模型结果)
方法 :使用 NFS
1. 在主机(Server)上配置 NFS
假设主机 IP 为 10.1.4.146,共享目录为 /mnt/mmsegmentation/my_project/.dist_test:
# 安装 NFS 服务端(Ubuntu/Debian)
sudo apt update
sudo apt install nfs-kernel-server
# 创建共享目录并设置权限
sudo mkdir -p /mnt/mmsegmentation/my_project/.dist_test
sudo chmod 777 /mnt/mmsegmentation/my_project/.dist_test # 临时放宽权限,生产环境建议细化权限
# 编辑 NFS 导出配置
sudo nano /etc/exports
在 /etc/exports 中添加:
/mnt/mmsegmentation/my_project/.dist_test *(rw,sync,no_subtree_check,no_root_squash)
保存后重启 NFS 服务:
sudo exportfs -a
sudo systemctl restart nfs-kernel-server
2. 在从机(Client)上挂载 NFS
在每台从机(如 10.1.4.168)执行:
# 安装 NFS 客户端
sudo apt update
sudo apt install nfs-common
# 创建本地挂载点
sudo mkdir -p /mnt/mmsegmentation/my_project/.dist_test
# 挂载 NFS 共享目录
sudo mount -t nfs 10.1.4.146:/mnt/mmsegmentation/my_project/.dist_test /mnt/mmsegmentation/my_project/.dist_test
# 验证是否挂载成功
df -h | grep .dist_test
ls /mnt/mmsegmentation/my_project # 应看到主机共享的文件
3. 设置开机自动挂载(在从节点执行)
编辑 /etc/fstab:
sudo nano /etc/fstab
添加以下行:
10.1.4.146:/mnt/mmsegmentation/my_project/.dist_test /mnt/mmsegmentation/my_project/.dist_test nfs rw,hard,intr 0 0
测试挂载:
sudo mount -a
八、mmsegmentation代码改动(主节点、从节点都改)
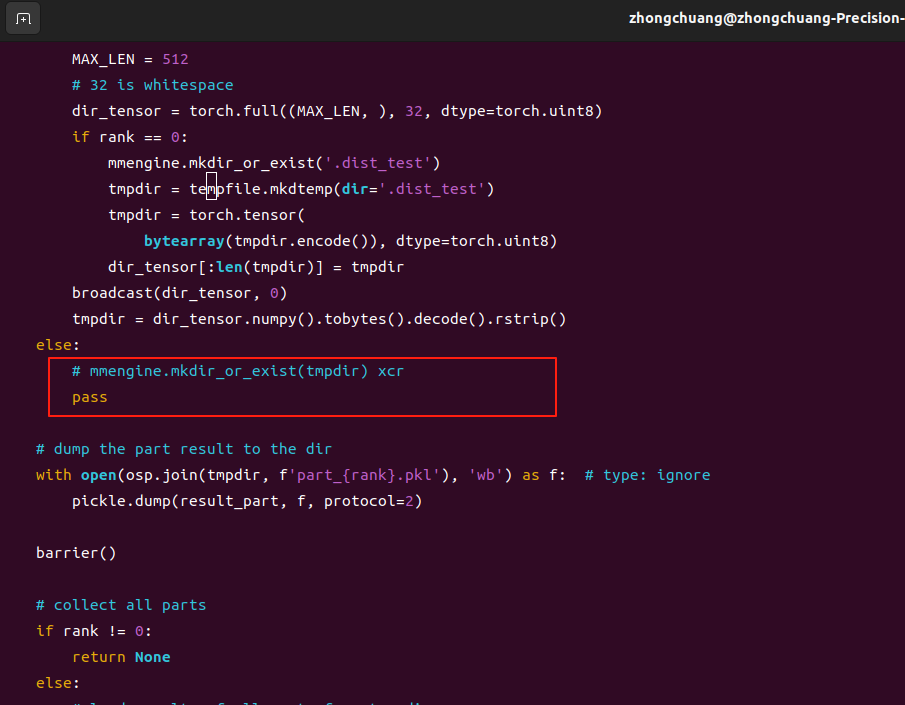
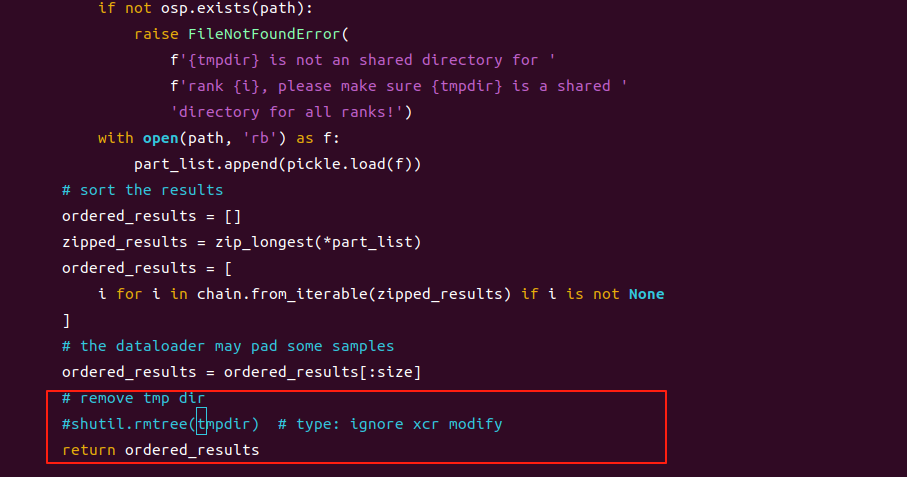
1、vi /home/li/anaconda3/envs/torch/lib/python3.8/site-packages/mmengine/dist/dist.py
collect_results_cpu函数
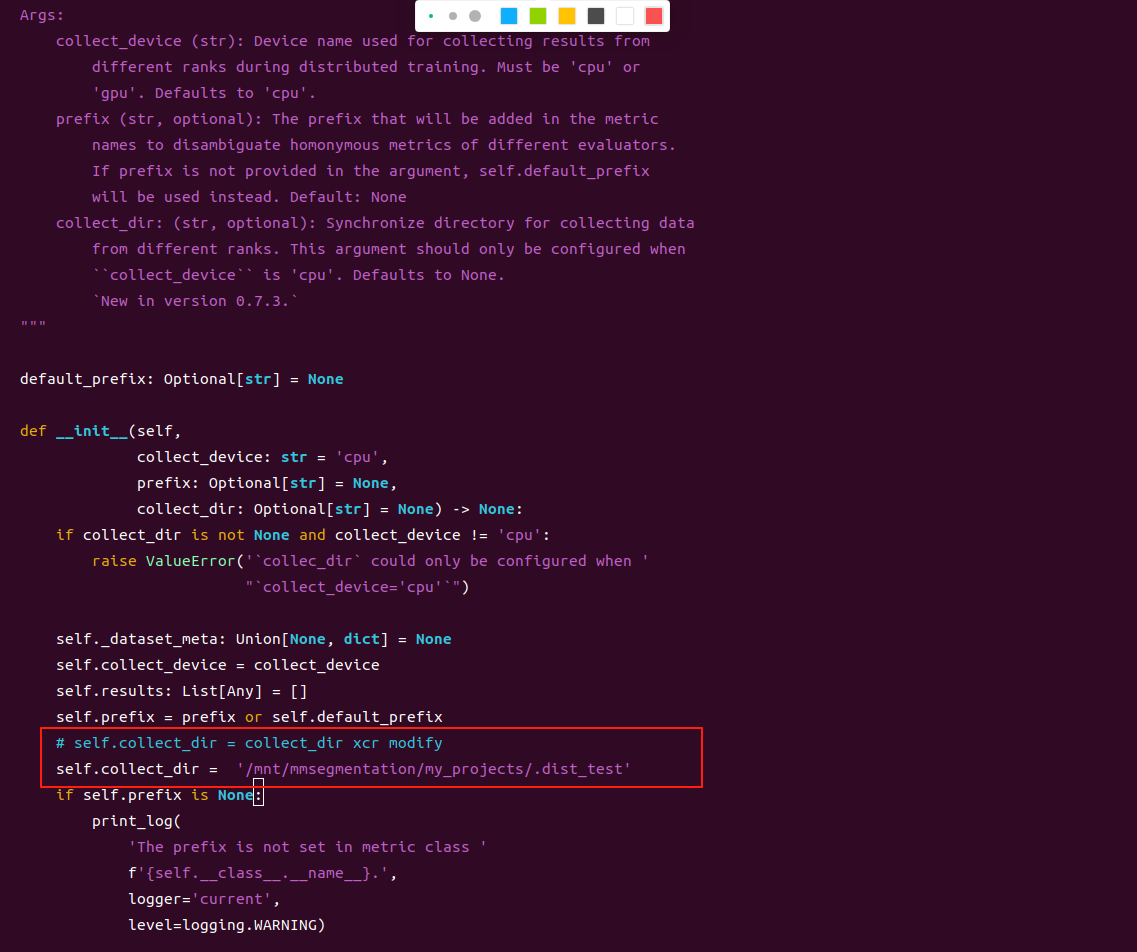
2、vi /home/li/anaconda3/envs/torch/lib/python3.8/site-packages/mmengine/evaluator/metric.py
3、tools/dist_train.sh
主节点
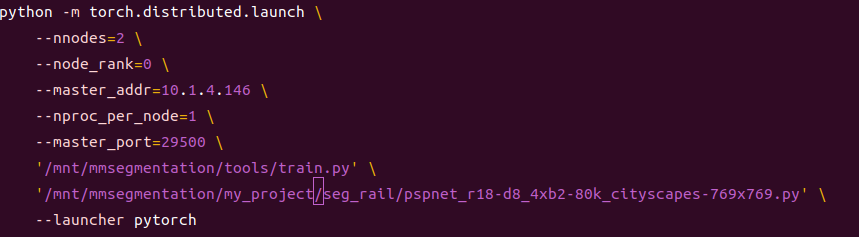
从节点
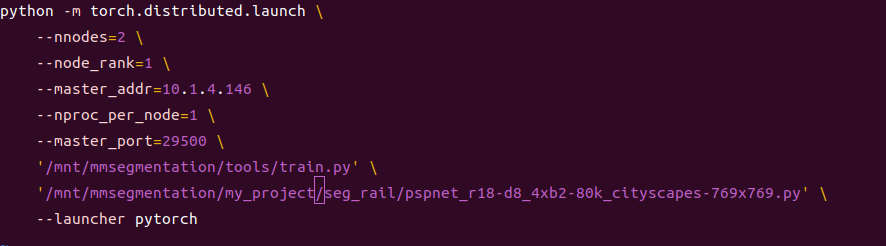
九、命令提交
主节点:NCCL_DEBUG=INFO NCCL_IB_DISABLE=1 bash ../tools/dist_train.sh
从节点:NCCL_DEBUG=INFO NCCL_IB_DISABLE=1 bash ../tools/dist_train.sh
附件:搭建mmsegmentation训练自己的数据基本操作(segformer为例)
1. 新建my_project->segformer_rail
将segformer参与训练的全部config文件放在segformer_rail文件下,根据想要训练的网络,在configs目录选取网络模型及输入尺寸,迭代次数等
1) 这里训练的是segformer,所以选取 segfomer/segformer_mit-b5_8xb1-160k_cityscapes-1024x1024.py,将其放在新建my_project->segformer_rail文件夹下,其中cityscapes是数据类型。
segformer_mit-b5_8xb1-160k_cityscapes-1024x1024.py文件中是这样的。
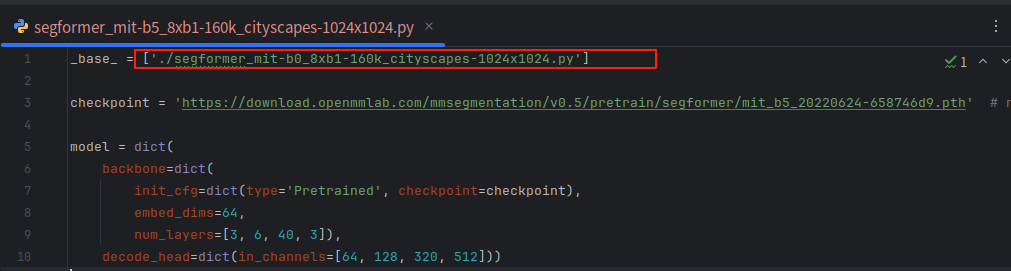
所以再将'./segformer_mit-b0_8xb1-160k_cityscapes-1024x1024.py'复制过来
segformer_mit-b0_8xb1-160k_cityscapes-1024x1024.py打开是这样的
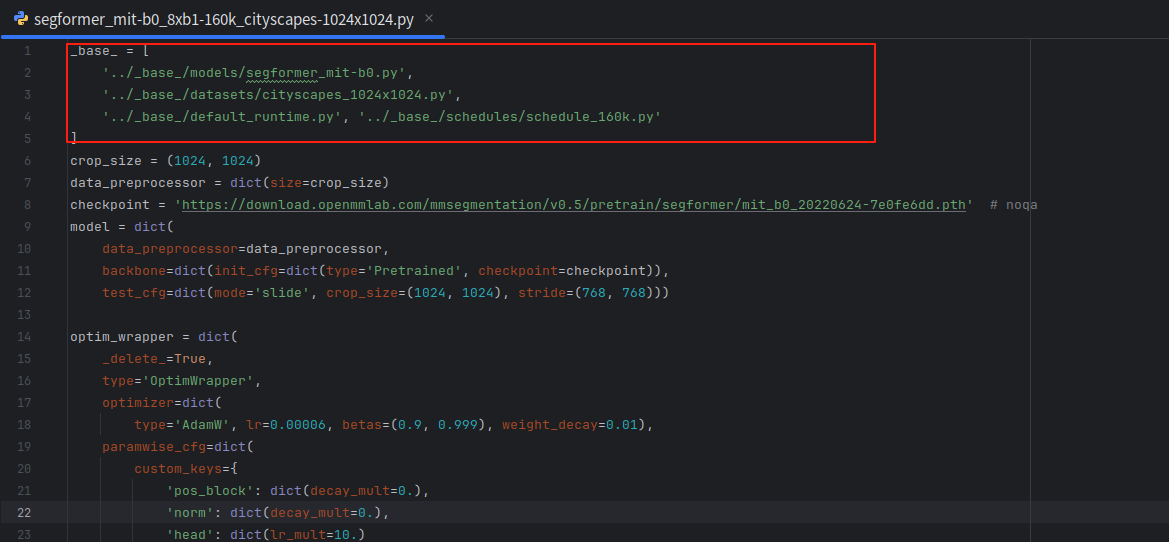
所以再将../_base_/models/segformer_mit-b0.py',
'../_base_/datasets/cityscapes_1024x1024.py',
'../_base_/default_runtime.py',
'../_base_/schedules/schedule_160k.py'复制过来
因为都有文件都放在同一目录下,所以将以上文件的路径进行修改
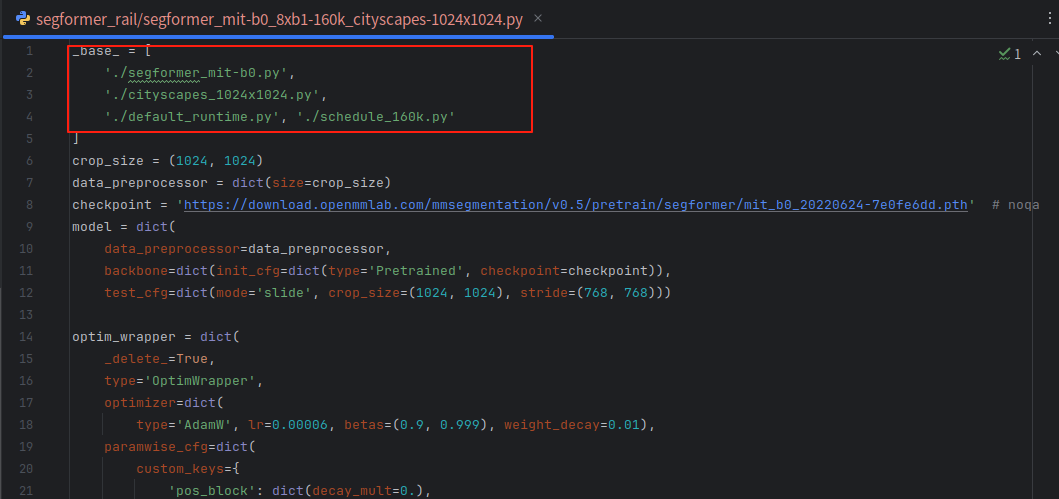
2)、新建一个空白__init__.py文件
2.按照需求修改训练config (即新建my_project->segformer_rail文件夹下的文件)
1)修改cityscapes.py,因为使用的是自定义数据集,修改dataset_type = 'MyCityscapesDataset',并指定数据集的路径
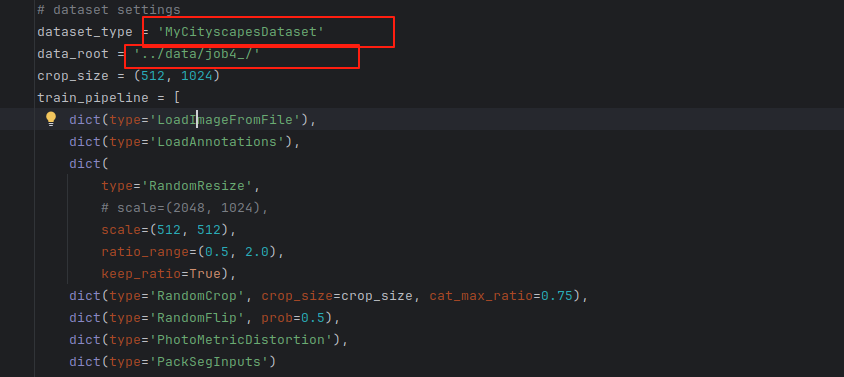
3.在mmseg/datasets新建一个文件mycityscapes.py仿照cityscape.py
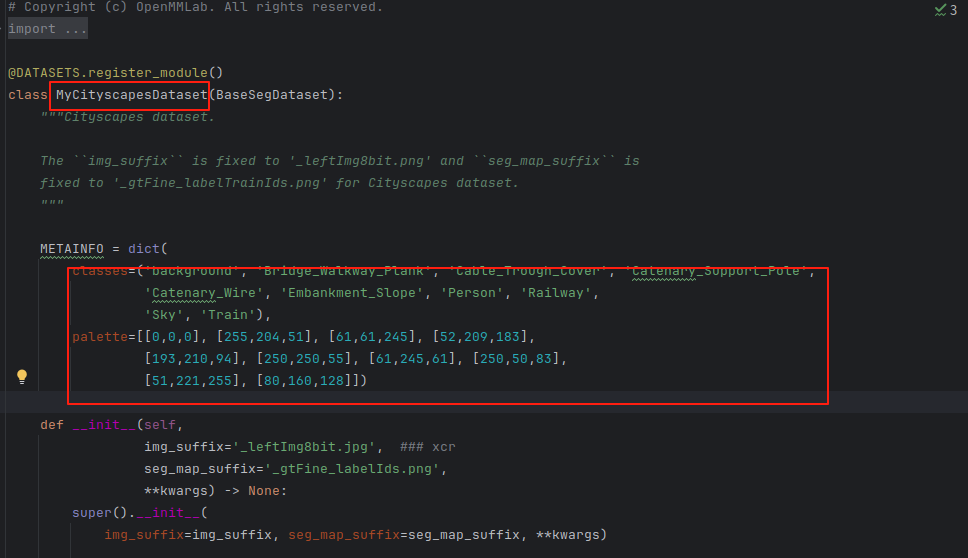
修改mycityscapes.py中的内容
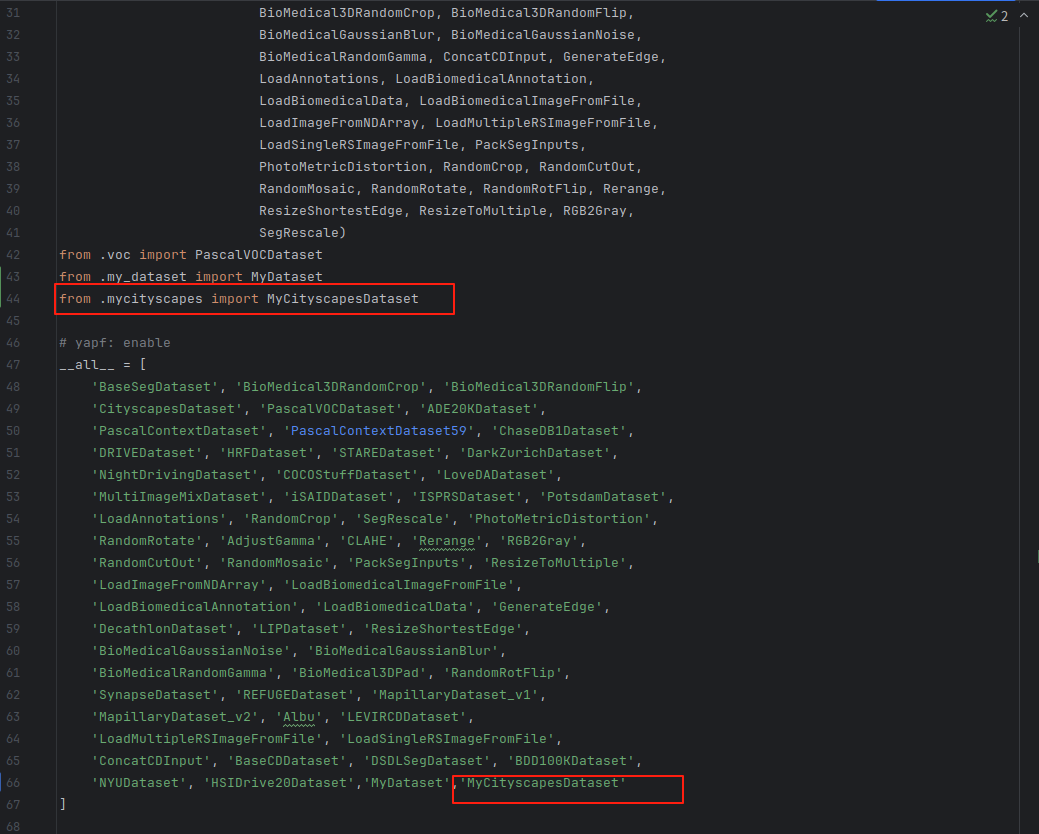
4.在mmseg/datasets/__init__.py中把自己的数据集添加进去:
5.修改segformer_mit-b0.py,需要修改num_classes 为自己的类别+1 算上背景 !!!!!
如果单卡,norm_cfg 修改为如下,norm_cfg = dict(type='BN', requires_grad=True)
6.修改mmseg/utils/classnames.py文件
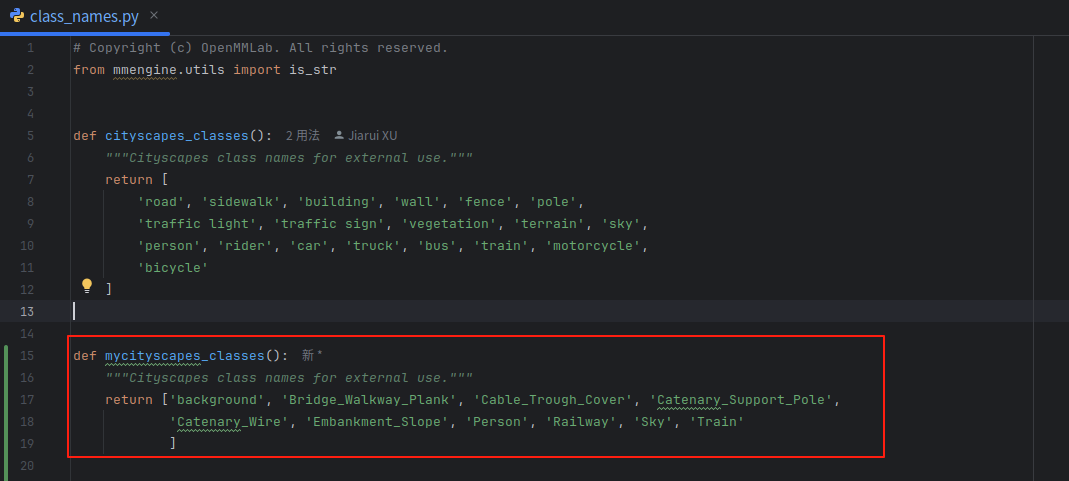
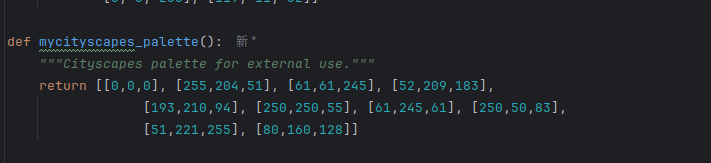
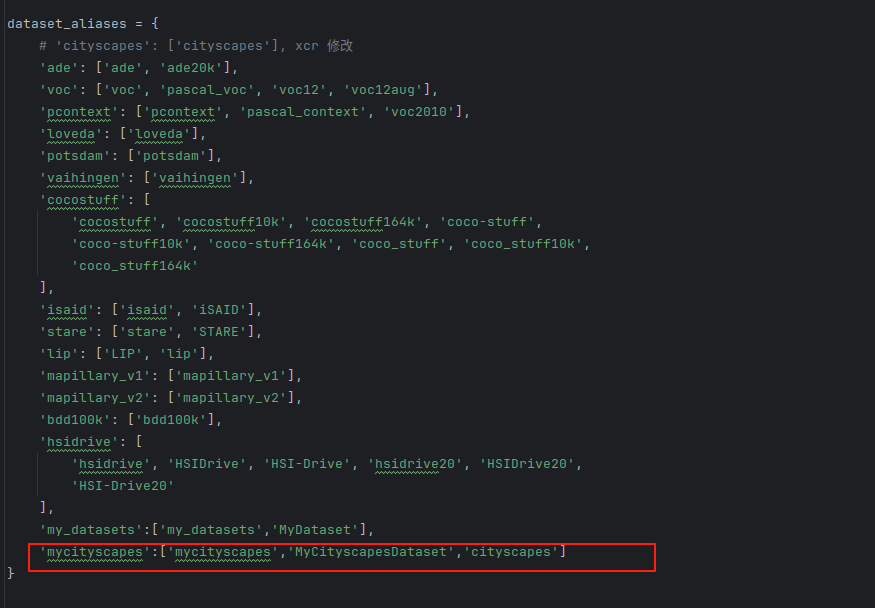
key-mycityscapes 与mycityscapes_palette中的mycityscapes 对应
7.提交训练命令(单机单卡、单机多卡如下,多机多卡见上文)
python ../tools/train.py ./segformer_rail/segformer_mit-b5_8xb1-160k_cityscapes-1024x1024.py --work-dir=./train_logs

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









