






1.基本思想
GAN分为一个生成器(Discriminator,简称D)和一个生成器(Generator,简称G),简单的说,G和D就是两个多层感知器或卷积神经网络,他的基本思想,即为G和D的生成博弈过程。
训练D来让他能辨明真假数据,即给D输入真数据,将label赋值为1,输入假数据,将label赋值为0.
而G是要愚弄D,使他认为G生成的为真数据,即给G输入噪声z,让他生成一个假数据G(z),将G(z)输入D,赋值为1。此G的训练过程中,固定D的参数不变,只调整G的参数,否则D只需简单的迎合G就能达到G的目的。
基本结构:

2.损失函数
结合上述基本思想,我们可以得出以下损失函数:
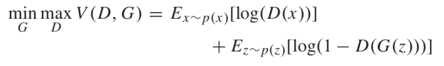
如何理解这个式子呢?首先,固定G,只训练D,要使D(real)尽量的大,D(G(z))尽量的小,即1-(G(z))尽量的大,所以对于D,要max V(D,G)。其次,固定D,只训练G,此时与上式的第一项D(x)就没有关系了,只看后一项,要使D(G(z))尽量的大,即1-(G(z))尽量的小,所以对于G,要min V(D,G)。
3.基于pytorch用GAN实现mnist手写数字生成
3.1 定义一些要用的模块
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torchvision.utils import save_image
z_dimension = 100 # the dimension of noise tensor
3.2 读minst数据集
我们使用torchvision扩展库读取mnist数据,只需调用torchvision.datasets.MNIST(),该函数的参数:
root:表示数据将要存在哪里,我们这里设置的是’./data’,那么函数会将解压后的文件存在‘./data/raw’,将处理过的文件存在‘./data/processed’
train:为True表示要读取训练集,为False表示要读取测试集
download:表示是否要从网络上下载数据,一般设为True,如果指定的root位置没有数据,才会下载数据,否则不需要重新下载数据
transform:表示要将读取的原始数据转换为什么格式,为了方便pytorch使用,一般转换为tensor,而这里,我们先将原始数据转换为tensor,再将其做归一化操作,使用torchvision.transforms.Compose函数,把多个步骤合在一起
读取完数据,使用torch.utils.data,DataLoader分批读取类实例trainset和testset的内容
transform = transforms.Compose([
#将PILImage或者numpy的ndarray转化成Tensor,这样才能进行下一步归一化
transforms.ToTensor(),
#transforms.Normalize(mean,std)参数:
transforms.Normalize([0.5], [0.5]),
])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False)
可以验证一下,如图,一个batch内,image.size=128,labels.size=128,与我们在torch.utils.data,DataLoader参数中设置的一样

3.3 构建生成器和判别器
为了运行速度快一点,我们使用简单的线性结构构建生成器和判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.dis = nn.Sequential(
nn.Linear(784, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.dis(x)
return x
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.gen = nn.Sequential(
nn.Linear(z_dimension, 256),
nn.ReLU(True),
nn.Linear(256, 256),
nn.ReLU(True),
nn.Linear(256, 784),
nn.Tanh()
)
def forward(self, x):
x = self.gen(x)
return x
3.4 数据处理,将x的范围由(-1,1)伸缩到(0,1)
def to_img(x):
out = 0.5 * (x + 1) # 将x的范围由(-1,1)伸缩到(0,1)
out = out.view(-1, 1, 28, 28)
return out
3.5 定义生成器、判别器、优化器
D = Discriminator().to('cpu')
G = Generator().to('cpu')
#因为我们只需要区分real和fake,所以使用二分类交叉熵损失函数即可
criterion = nn.BCELoss()
D_optimizer = torch.optim.Adam(D.parameters(), lr=0.0003)
G_optimizer = torch.optim.Adam(G.parameters(), lr=0.0003)
os.makedirs("MNIST_FAKE", exist_ok=True)
3.6 训练
def train(epoch):
print('\nEpoch: %d' % epoch)
#将模型调整到训练状态
D.train()
G.train()
all_D_loss = 0.
all_G_loss = 0.
for batch_idx, (inputs, targets) in enumerate(trainloader):
#使网络在GPU上进行训练
inputs, targets = inputs.to('cpu'), targets.to('cpu')
#num_img即为图片的数量
num_img = targets.size(0)
#real的标签是1,fake的标签是0
real_labels = torch.ones_like(targets, dtype=torch.float)
fake_labels = torch.zeros_like(targets, dtype=torch.float)
#把输入的28*28图片压平成784,便于输入D进行运算
inputs_flatten = torch.flatten(inputs, start_dim=1)
# Train Discriminator
real_outputs = D(inputs_flatten)
#criterion就是上一步定义的nn.BCELoss()
D_real_loss = criterion(real_outputs, real_labels)
z = torch.randn((num_img, z_dimension)) # Random noise from N(0,1)
fake_img = G(z) # Generate fake images
fake_outputs = D(fake_img.detach())
D_fake_loss = criterion(fake_outputs, fake_labels)
D_loss = D_real_loss + D_fake_loss
#清空上一步的残余更新参数值
D_optimizer.zero_grad()
# 误差反向传播, 计算参数更新值
D_loss.backward()
# 将参数更新值施加到 net 的 parameters 上
D_optimizer.step()
# Train Generator
z = torch.randn((num_img, z_dimension))
#fake_img是G从噪声生成的
fake_img = G(z)
#再把fake_img送入D,让D判别真假
G_outputs = D(fake_img)
G_loss = criterion(G_outputs, real_labels)
G_optimizer.zero_grad()
G_loss.backward()
G_optimizer.step()
all_D_loss += D_loss.item()
all_G_loss += G_loss.item()
print('Epoch {}, d_loss: {:.6f}, g_loss: {:.6f} '
'D real: {:.6f}, D fake: {:.6f}'.format
(epoch, all_D_loss/(batch_idx+1), all_G_loss/(batch_idx+1),
torch.mean(real_outputs), torch.mean(fake_outputs)))
# Save generated images for every epoch
fake_images = to_img(fake_img)
save_image(fake_images, 'MNIST_FAKE/fake_images-{}.png'.format(epoch + 1))
for epoch in range(40):
train(epoch)
为了更清楚一点,在上述代码中加入这几行,打印batch_idx的内容,inputs, targets的大小:

输出的部分内容:
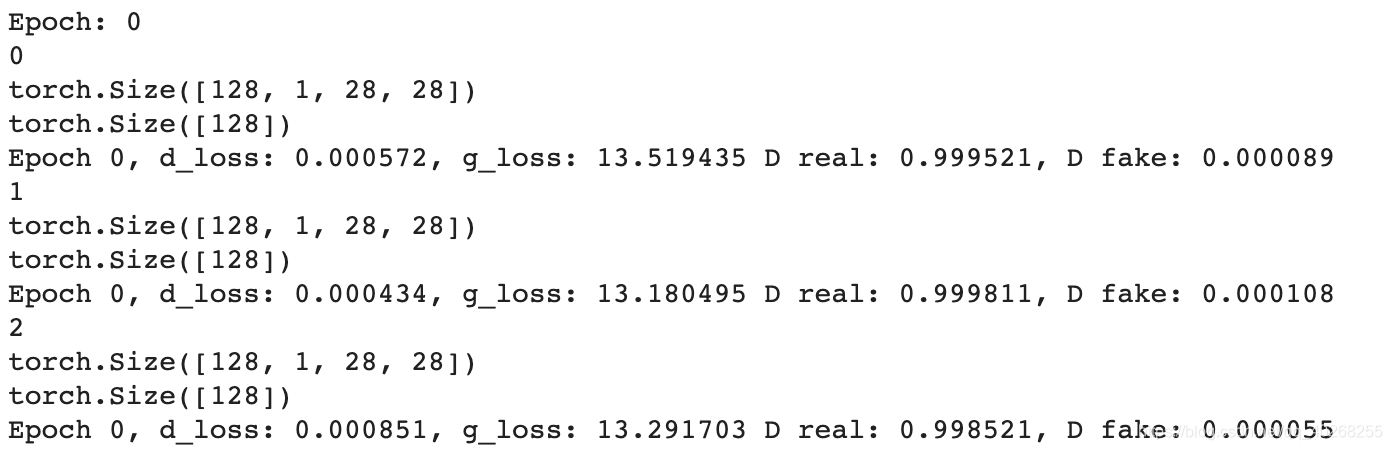
可以看出,batch_idx是循环的次数,inputs是图片,targets是他的标签
3.7 可视化训练过程
代码是上一部分代码的最后两行:
# Save generated images for every epoch
fake_images = to_img(fake_img)
save_image(fake_images, 'MNIST_FAKE/fake_images-{}.png'.format(epoch + 1))
由于最后一个batch的大小是96,所以我们输出的也是96张图的一个集合,如图,epoch 0几乎都是噪声:


可以看出,在epoch0,G和D的loss都比较大
epoch20:

epoch40:

这时的效果虽比epoch0好了很多,至少噪声大大减小,也能模糊的辨别数字,但还不是很理想,可能是因为我们使用线性分类器的原因,训练次数过小也是一个原因,也可以从损失函数等方面改进














 1198
1198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









