






WaterMark与EventTime
在EventTime中数据是使用自带的时间戳来进行计算,可以防止 Flink 内部处理数据是发生乱序的情况,但无法解决数据到达 Flink 之前发生的乱序问题。所以,为了解决消息乱序的问题,会让WaterMark结合EventTime使用。这里进行举例说明:
public static void test(StreamExecutionEnvironment env){
SingleOutputStreamOperator<String> stream = env.socketTextStream("localhost", 9527)
/**
* flink1.12时间类型默认是eventtime,不需要指定
* 在使用基于event的窗口函数时,必须在前面指定watermark
* 这里设置watermark为0,即表示不接收延迟数据
*/
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(0)) {
@Override
public long extractTimestamp(String s) {
return Long.parseLong(s.split(",")[0]);
}
});
stream.map(new MapFunction<String, Tuple2<String,Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
String[] split = s.split(",");
return Tuple2.of(split[1],Integer.parseInt(split[2]));
}
})
.keyBy(x -> x.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))//滚动窗口,每5秒一次
.sum(1)
.print();
}
上述简单做了一个词频计算,这里设置的是每5秒计算一次,不接收延迟数据。输入如下: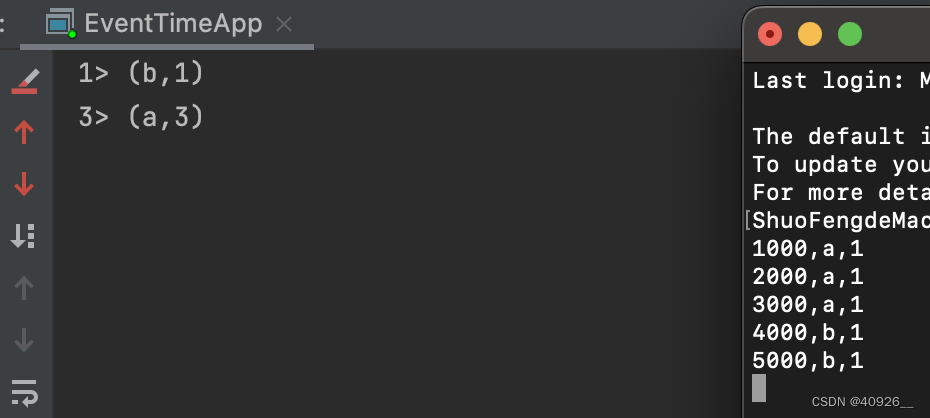
这里时间戳输入到5000时触发了窗口计算,会计算[0,5000)这个区间的数据。
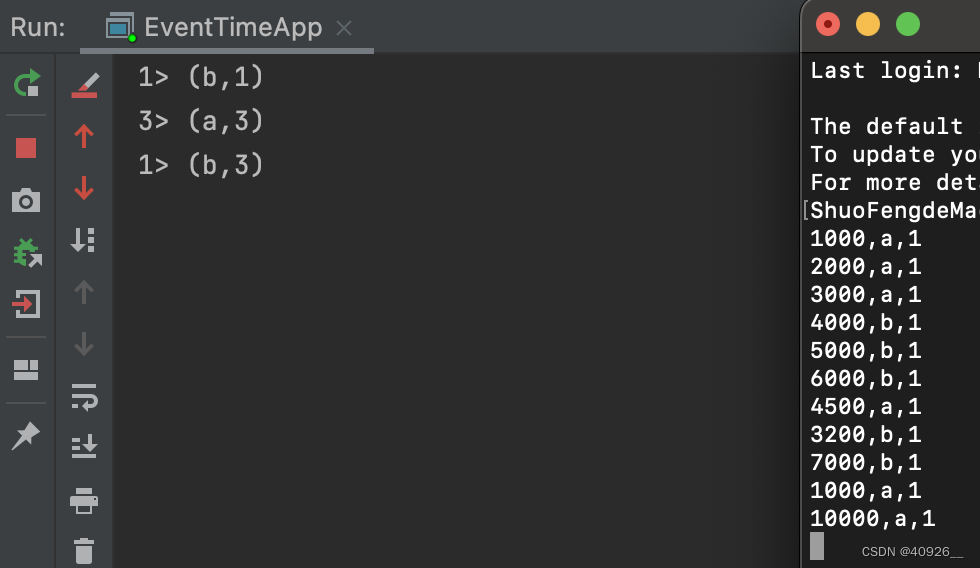
由于网络原因,这个时候来了几条延迟数据:(4500,a,1)、(3200,b,1)、(1000,a,1)因为设置的是零延迟,在数据流时间戳达到10000时触发窗口计算。所以这几条数据就被丢弃,只会计算[5000,10000)这个区间的数据。
WaterMark的使用
WaterMark设定方法有两种:
1、Punctuated Watermark :
数据流中每一个递增的EventTime都会产生一个Watermark。在实际的生产中用Punctuated方式,在TPS很高的场景下,会产生大量的Watermark,在一定程度上造成了对下游算子造成压力。所以只有在实时性要求非常高的场景才会选择Punctuated的方式。
datastream.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<String, Long, Integer>>() {
@Override
public long extractAscendingTimestamp(Tuple3<String, Long, Integer> element) {
return element.f1;
}
});
2、Periodic Watermark :
默认200毫秒为一周期(或达到一定的记录条数)产生一个Watermark。在实际的生产中使用Periodic的方式必须结合时间和积累条数两个维度,周期性的产生Watermark,否则在极端情况下会有很大的延时
Time interval = Time.milliseconds(300000L);
ds.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Tuple3<String, Long, Integer>>(interval) {
@Override
public long extractTimestamp(Tuple3<String, Long, Integer> element) {
return 0;
}
});
这里又分为自定义和系统自带,一般情况下使用系统的。
延迟数据处理
对于上述提到的案例,我们稍微修改下参数,这里改为2
那么现在就变成允许2秒延迟数据再触发窗口计算,如下:
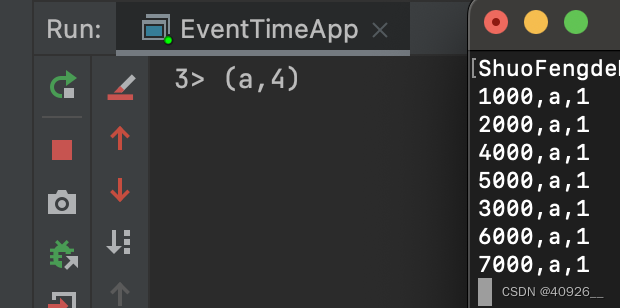
如图,这里任然是5秒一个窗口,计算[0,5000)区间内数据,这个时候允许延迟2秒数据,则数据流中最大时间戳 >= 窗口结束时间 + 允许延迟时间触发窗口计算,统计[0,5000)区间内数据。这个时候(3000,a,1)这条数据虽然晚到,但也能被处理计算。
这里总结下窗口触发条件:
watermark >= 窗口结束时间
watermark = 当前时间戳最大时间 - 允许延迟时间
如果有一种情况,当(3000,a,1)这条数据,在2秒延迟以外到达,这个时候窗口已经触发计算完了,窗口已经关闭,那么这个时候延迟的数据怎么处理呢?flink给我一个策略:SideOutputTag又叫侧数据流,他可以把延迟数据搜集起来。
public static void test2(StreamExecutionEnvironment env){
OutputTag<Tuple2<String, Integer>> outputTag = new OutputTag<Tuple2<String, Integer>>("late-data") {};
DataStreamSource<String> stream = env.socketTextStream("localhost", 9527);
SingleOutputStreamOperator<Tuple2<String, Integer>> window_stream =
stream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(2)) {
@Override
public long extractTimestamp(String s) {
return Long.parseLong(s.split(",")[0]);
}
})
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
String[] splits = s.split(",");
return Tuple2.of(splits[1], Integer.parseInt(splits[2]));
}
})
.keyBy(x -> x.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(6))) //滚动窗口
.sideOutputLateData(outputTag)//延迟数据放入侧输出流里
.allowedLateness(Time.seconds(3))//最大允许延迟3秒
.sideOutputLateData(outputTag)//延迟之外的数据保存在侧输出流
.sum(1);
window_stream.print();
DataStream<Tuple2<String, Integer>> sideOutput = window_stream.getSideOutput(outputTag);
sideOutput.printToErr();
}
这里是watermark+allowedLateness+sideOutputLateData的一个综合案例,接下来输入以下数据进行分析:
1000,a,1
3000,a,1
2000,a,1
5999,a,1
7000,a,1
7999,a,1
2999,a,1
4999,a,1
11000,a,1
1999,a,1
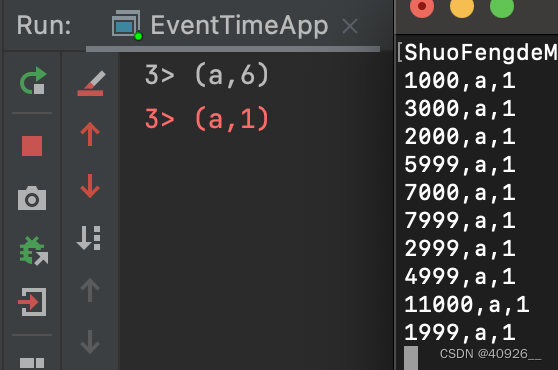
先说下代码里的配置:
watermark = 2s 、 window = 6s、 allowedLateness = 3s
这里我第一条数据输入(1000,a,1),那么第一个窗口会计算[0,6000)。需要说明的是窗口的起点是0,而不是1000,是因为在TumblingEventTimeWindows里设置只有windowSize,而没有offset。所以这边默认从0开始,下面是源码。
然后回到输入的数据流里,因为watermark设置是2秒,所以当数据流时间戳达到2+6=8秒时,即(7999,a,1)这条数据到来,会触发[0,6000)分区的窗口计算。这是会计算(1000,a,1),(3000,a,1),(2000,a,1),(5999,a,1)的求和结果,即(a,4)。
这个时候再输入(2999,a,1),(4999,a,1),但由于前面配置了allowedLateness等于3秒,所以第一个窗口会在2+6+3=11秒后关闭,再输入(11000,a,1)触发触发第一个窗口计算,会在累加(2999,a,1),(4999,a,1)求和的结果,即(a,6)。计算完毕并关闭窗口。最后再来一条(1999,a,1)数据,因为第一个窗口已经关闭,此时数据保存在outputTag侧输出流里,通过getSideOutput打印到控制台。














 1019
1019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









