







一、概念理解
- 偏差:将模型的期望(或平均)预测和我们正在试图预测正确值之间的差定义为偏差。
- 方差: 将模型之间的多个拟合预测之间的偏离程度定义为方差。

二、数学定义
我们定义需要预测的真实结果
Y
Y
Y,与其对应的自变量
X
X
X(训练样本),之间有这样的关系:
Y
=
f
(
X
)
+
ϵ
Y = f(X) + ϵ
Y=f(X)+ϵ (我们认为
ϵ
ϵ
ϵ满足正态分布
ϵ
∼
N
(
0
,
σ
ϵ
)
)
’
ϵ∼N(0,σϵ) )’
ϵ∼N(0,σϵ))’。
令
y
D
y_D
yD为
x
x
x在测试样本中的值,
y
y
y为真实的值。
有可能出现噪音使得yD != y
为了方便讨论,这里假定E[ yD - y ] = 0
假设,
f
D
(
x
)
f_D(x)
fD(x)为训练集
X
X
X上学得模型
f
f
f在
x
x
x上的预测输出,学习算法的期望预测为:
f
E
x
p
e
c
t
e
d
D
(
x
)
=
E
[
f
D
(
x
)
]
f_{ExpectedD}(x) = E[ f_D(x) ]
fExpectedD(x)=E[fD(x)]
统计学习中有一个重要概念叫做residual sum-of-squares:
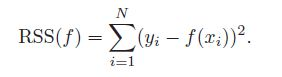
RSS看起来是一个非常合理的统计模型优化目标。但是考虑K-NN的例子,在最近邻的情况下(K=1),RSS=0,是不是KNN就是一个完美的模型了呢,显然不是,KNN有很多明显的问题,比如对训练数据量的要求很大,很容易陷入维度灾难中。
KNN的例子说明仅仅优化RSS是不充分的,因为针对特定训练集合拟合很好的model,并不能说明这个model的泛化能力好,而泛化能力恰恰又是机器学习模型的最重要的要求。真正能说明问题的不是RSS,因为它只是一个特定训练集合,而是在多个训练结合统计得出的RSS的期望,MSE(mean squared error),即期望泛化误差(均方误差)。
基于假设,我们可以得到关于测试集x的MSE(mean squared error):
M
S
E
(
x
)
=
E
[
(
f
D
(
x
)
−
y
D
)
2
]
=
E
[
(
f
D
(
x
)
−
y
D
+
f
E
x
p
e
c
t
e
d
D
(
x
)
−
f
E
x
p
e
c
t
e
d
D
(
x
)
)
2
]
=
E
[
(
f
D
(
x
)
−
f
E
x
p
e
c
t
e
d
D
(
x
)
)
2
+
(
f
E
x
p
e
c
t
e
d
D
(
x
)
−
y
D
)
2
+
2
∗
(
f
D
(
x
)
−
f
E
x
p
e
c
t
e
d
D
(
x
)
)
∗
(
f
E
x
p
e
c
t
e
d
D
(
x
)
−
y
D
)
]
=
E
[
(
f
D
(
x
)
−
f
E
x
p
e
c
t
e
d
D
(
x
)
)
2
]
+
E
[
(
f
E
x
p
e
c
t
e
d
D
(
x
)
−
y
D
)
2
]
+
0
=
E
[
(
f
D
(
x
)
−
f
E
x
p
e
c
t
e
d
D
(
x
)
)
2
]
+
E
[
(
f
E
x
p
e
c
t
e
d
D
(
x
)
−
y
D
−
y
+
y
)
2
]
=
E
[
(
f
D
(
x
)
−
f
E
x
p
e
c
t
e
d
D
(
x
)
)
2
]
+
E
[
(
f
E
x
p
e
c
t
e
d
D
(
x
)
−
y
)
2
]
+
E
[
(
y
−
y
D
)
2
]
+
2
∗
E
[
(
f
E
x
p
e
c
t
e
d
D
(
x
)
−
y
)
∗
(
y
−
y
D
)
]
=
E
[
(
f
D
(
x
)
−
f
E
x
p
e
c
t
e
d
D
(
x
)
)
2
]
+
E
[
(
f
E
x
p
e
c
t
e
d
D
(
x
)
−
y
)
2
]
+
E
[
(
y
−
y
D
)
2
]
=
v
a
r
2
(
x
)
+
b
i
a
s
2
(
x
)
+
ϵ
2
\begin{aligned} MSE(x)&= E[(f_D(x)-y_D)^2]\\ &=E[(f_D(x)-y_D+f_{ExpectedD}(x) -f_{ExpectedD}(x) )^2]\\ &=E[(f_D(x)-f_{ExpectedD}(x))^2+(f_{ExpectedD}(x)-y_D)^2+\\&2*(f_D(x)-f_{ExpectedD}(x))*(f_{ExpectedD}(x)-y_D)]\\ &=E[(f_D(x)-f_{ExpectedD}(x))^2]+E[(f_{ExpectedD}(x)-y_D)^2]+0\\ &=E[(f_D(x)-f_{ExpectedD}(x))^2]+E[(f_{ExpectedD}(x)-y_D-y+y)^2]\\ &=E[(f_D(x)-f_{ExpectedD}(x))^2]+E[(f_{ExpectedD}(x)-y)^2]\\&+E[(y-y_D)^2]+2*E[(f_{ExpectedD}(x)-y)*(y-y_D)]\\ &=E[(f_D(x)-f_{ExpectedD}(x))^2]+E[(f_{ExpectedD}(x)-y)^2]\\&+E[(y-y_D)^2]\\ &=var^2(x)+bias^2(x)+\epsilon^2 \end{aligned}
MSE(x)=E[(fD(x)−yD)2]=E[(fD(x)−yD+fExpectedD(x)−fExpectedD(x))2]=E[(fD(x)−fExpectedD(x))2+(fExpectedD(x)−yD)2+2∗(fD(x)−fExpectedD(x))∗(fExpectedD(x)−yD)]=E[(fD(x)−fExpectedD(x))2]+E[(fExpectedD(x)−yD)2]+0=E[(fD(x)−fExpectedD(x))2]+E[(fExpectedD(x)−yD−y+y)2]=E[(fD(x)−fExpectedD(x))2]+E[(fExpectedD(x)−y)2]+E[(y−yD)2]+2∗E[(fExpectedD(x)−y)∗(y−yD)]=E[(fD(x)−fExpectedD(x))2]+E[(fExpectedD(x)−y)2]+E[(y−yD)2]=var2(x)+bias2(x)+ϵ2
即MSE可以分解为方差,偏差与噪音之和。
















 3504
3504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









