






Sequence-to-Sequence Knowledge Graph Completion and Question
备注:ACL 2022 Main Conference
链接:https://arxiv.org/pdf/2203.10321v1.pdf
测试窗口:https://huggingface.co/apoorvumang/kgt5-wikikg90mv2
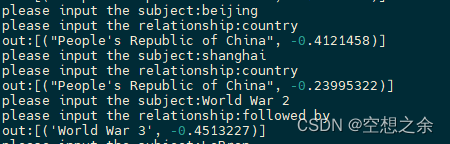
对于该预训练模型,作者提供了一个窗口,可以输入“实体| 关系"得到预测值。仅限于英文。
根据作者提供的代码,写了个demo,测试了几个数据,感觉效果还不错
作者也说了,如果要应用到中文上面,需要重新训练这个模型,不过作者用4块1080ti在WikiKG90Mv2上训练1轮的时间为5.5天,感觉要重新训练还是挺吃算力的。
摘要:
现成的编码器-解码器转换器模型可以作为可扩展和通用的KGE模型,获得KG链接预测和不完全KG问题回答的最新结果。通过将KG链接预测(KG link prediction)作为序列到序列(seq2seq)的任务来实现这一点,并将先前KGE方法采用的三重评分方法与自回归解码进行交换。与传统的KGE模型相比,这种简单但强大的方法将模型大小减少了98%,同时保持推理时间易处理。
Introduction
大多数知识图谱是不完整的。但一些缺失的事实可以利用知识图谱中的现有事实进行推断(Bordes等人,2013)。这项任务被称为知识图谱补全(KGC)
考虑到现实世界中KGs的巨大规模(Wikidata包含≈9千万个实体)和对下游任务的适用性,KGE模型应满足以下要求。
- 可扩展性–即模型大小和推理时间与实体数量无关
- 高质量–达到良好的经验性能
- 通用性–适用于多种任务,如KGC和QA
- 简单性–由一个具有标准架构和训练管道的单一模块组成。
传统的KGE模型满足了质量和简单性。它们建立在一个简单的架构上,在KGC方面达到了很高的质量,然而,由于它们为每个实体/关系创建了一个独特的嵌入,因此在模型大小和推理时间方面,它们与图中的实体数量呈线性扩展,并提供有限的多功能性。DKRL(Xie等人,2016a)和KEPLER(Wang等人,2021)等方法试图使用组合式嵌入解决可扩展性问题。然而,它们未能达到与传统的KGEs相媲美的质量
简单来说就是过去的工作无法同时满足四个要求,高质量的传统KGE无法满足可扩展性,满足可扩展性的方法打不到传统的高质量。
KG-BERT(Yao等人,2019年)利用预训练的BERT进行链接预测,在通用性方面具有潜力,因为它适用于下游的NLP任务。利用KGEs的QA方法在不完整的KGs上的表现优于传统的KGQA方法,但将KGEs与QA管道相结合是一项非艰巨的任务;试图这样做的模型往往只适用于有限的查询类型(Huang等人,2019;Sun等人,2021;Saxena等人,2020)或需要多阶段的训练和推理管道(任等人,2021)。在此,为了达到质量,这些模型牺牲了通用性和简单性。表9对各种方法的比较进行了总结。

作者提出,所有这些要求都可以通过一个简单的序列到序列(seq2seq)模型来实现。为此,将KG链接预测作为一个seq2seq任务,并在这个任务上训练一个encoder- decoder
Transformer模型(Vaswani等人,2017)。然后,使用这个模型进行链接预测的预训练,并进一步为问题回答进行微调;在为QA进行微调时,用链接预测的目标进行规范化。
这种简单而强大的方法,作者称之为KGT5,在图1中可以看到。通过这样一个统一的seq2seq方法,作者实现了
可扩展性–通过使用组合实体表示和自回归解码(而不是给所有实体打分)进行推理
高质量–在两个任务上获得了最优结果
通用性–同一个模型可以在多个数据集上用于KGC和KGQA
简单性–使用一个现成的模型获得所有结果,没有任务或数据集特定超参数调整。
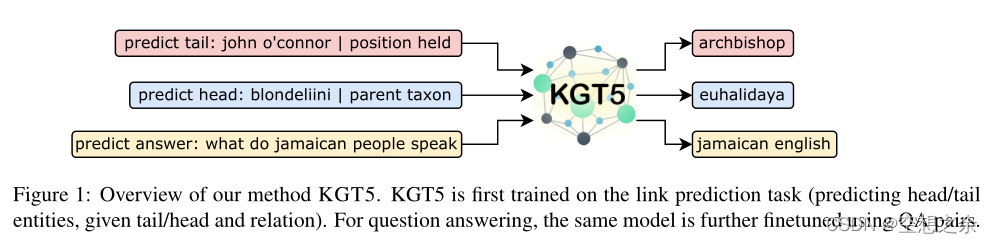
作者的主要贡献如下:
- KG链接预测和问题回答可以被视为序列到序列的任务,并通过单一的编码器-解码器Transformer(具有与T5-small(Raffel等人,2020)相同的架构)成功解决。
- KGT5,将KG链接预测的模型减少98%,同时在一个有9千万个实体的数据集上的表现优于传统的KGEs。
- 通过对不完整图的KGQA任务展示了这种方法的通用性。通过对KG链接预测的预训练和对QA的微调,KGT5在多个大规模KGQA基准上的表现与更复杂的方法相似或更好。
2 Background & Related Work
知识图谱可以视为(s,p,o)的三元组的集合,中文译为(主语-谓语-宾语)、(头实体-关系-尾实体),具体的区别见知乎专栏。
链接预测是通过回答(s, p, ?)和(?, p, o)形式的查询来预测K中缺失的三元组的任务。这通常是通过知识图谱嵌入(KGE)模型完成的。传统的KGEs为KG中的每个实体和关系分配一个嵌入向量。通过特定模型的评分函数f(es, ep,eo),使用主语(es)、谓语(ep)和宾语(eo)的特定嵌入,对(s, p,o)三联体的合理性进行建模。一旦经过训练,这些嵌入就可以用于下游任务,如问答。
知识图谱问题回答(KGQA)是一项利用KG作为知识来源来回答自然语言问题的任务。这些问题可以是简单的事实问题,需要对单一事实进行检索(例如,印度有哪些语言?),也可以是复杂的问题,需要对KG中的多个事实进行推理(例如,Leonardo DiCaprio是哪些类型的电影的男主角?) 当背景KGs不完整时,可以利用KGEs来执行KGQA。
2.1 Knowledge Graph Embeddings
Atomic KGE models. 文献中提出了多种KGE模型,主要是其评分函数f(es,ep,eo)的形式不同。Wang等人(2017)和Ruffinelli等人(2020)对这些模型、其评分函数、训练制度和链接预测性能进行了全面的调查。值得注意的是,尽管这些模型在链接预测任务中获得了卓越的性能,但它们受到了模型大小与KG中实体数量的线性缩放的影响,而且将它们应用于问题回答需要单独的KGE和QA模块。
Compositional KGE models. 为了解决模型大小与KG中实体数量的线性缩放问题,实体嵌入(entity embeddings)可以由标记嵌入(token embeddings)组成。DKRL(Xie等人,2016b)通过将实体描述的词嵌入与CNN编码器相结合,再加上TransE的评分函数来嵌入实体。KEPLER(Wang等人,2021)使用了一个基于Transformer的编码器,并将典型的KGE训练目标与掩盖的语言建模目标相结合。这两种方法都对实体和关系进行单独编码,这限制了这些模型对下游任务(如问题回答)的可转移性。MLMLM(Clouatre等人,2021)用一个基于RoBERTa的模型对整个查询进行编码,并使用[MASK]标记来生成预测。然而,它在大型KG上的链接预测方面的表现明显不如原子KGE模型,而且尚未应用于下游的基于文本的任务。
2.2 Knowledge Graph Question Answering
知识图谱问答(KGQA)传统上是通过语义解析来解决的(Berant等人,2013;Bast和Haussmann,2015;Das等人,2021a),其中自然语言(NL)问题被转换为对KG的符号查询。这对于不完整的KG来说是有问题的,其中一个缺失的链接就会导致查询失败。最近的工作集中在不完整的KG上的KGQA,这也是本文工作的重点。这些方法试图使用KG嵌入来克服KG的不完整性(Huang等人,2019;Saxena等人,2020;Sun等人,2021;Ren等人,2021)。
为了使用KGEs进行KGQA,这些方法首先在背景KG上训练一个KGE模型,然后将模型学到的实体和关系嵌入到QA管道中。但是现有方法仍然存在缺点,例如:Huang等人(2019)的方法只适用于单一事实问题的回答,而EmQL(Sun等人,2021)需要事先了解NL问题的查询结构。EmbedKGQA(Saxena等人,2020)能够进行多跳问题的回答,但无法处理涉及一个以上实体的问题。因此,这些方法缺乏通用性。LEGO(Ren等人,2021)理论上可以回答所有基于一阶逻辑的问题,但需要多个依赖于数据集的组件,包括实体链接、关系修剪和分支修剪模块;在这里,为了获得通用性,LEGO牺牲了简单性。
3 The KGT5 Model(作者的方法)
知识图谱链接预测和问题回答都作为序列到序列(seq2seq)任务。然后,在这些任务上训练一个简单的编码解码器Transformer–它的结构与T5-small(Raffel等人,2020)相同,但没有预训练的权重。在训练问题回答的同时,用链接预测目标进行规范化,作者将这种方法称之为KGT5,其结果是一个可扩展的KG链接预测模型,与传统的KGE模型相比,大型KG的参数少得多。这种方法也赋予了模型简单性和通用性,因此它可以很容易地适应任何数据集上的KGQA,而不考虑问题的复杂性。
3.1 Textual Representations & Verbalization
Text mapping. 对于链接预测,作者会要求实体/关系与其文本表述之间有一对一的映射关系。对于基于维基数据的KGs,使用实体和关系的典型提及作为其文本表示,然后使用一个消歧方案,将描述和唯一的ID附加到名称上。对于仅用于QA的数据集,不强制执行一对一的映射,因为在这种情况下,不必要的消歧甚至会损害模型性能。
Verbalization. 将(s,p,?)通过描述查询(s,p,?)转换为文本表示。这类似于Petroni等人(2019)进行的动词化,只是没有关系特定的模板。例如,给定一个查询(巴拉克·奥巴马,出生于,?),首先获得实体和关系的文本提及,然后将其描述为“预测宾语:巴拉克·奥巴马|出生于”。这个序列是模型的输入,输出序列应该是这个查询“美国”的答案,这是对实体“美国”的唯一提及。
3.2 Training KGT5 for Link Prediction
为了训练KGT5,需要一组(输入,输出)序列。对于训练图中的每个三元组(s,p,o ),将查询(s,p,)和(?p,o)动词化转成文本,以获得两个输入序列。相应的输出序列分别是o和s的文本提及。KGT5是用 teacher forcing(Williams和Zipser,1989)和交叉熵损失训练的。
RNN模型的训练分为两种,(关于teacher forcing 一种说法是每次都使用标准答案,另一种说法是有一定概率使用标准答案)
上一个state的输出作为下一个state的输入。这种方法的缺点是,若有一个单位节点的出错,那么会影响后续的一片单位节点的学习。错误结果会导致后续的学习都受到不好的影响,导致学习速度变慢,难以收敛。
使用来自先验时间步长的输出作为输入。在训练网络过程中,每次不使用上一个state的输出作为下一个state的输入,而是直接使用训练数据的标准答案(ground truth)的对应上一项作为下一个state的输入。但是导致一种叫做 Overcorrect (矫枉过正) 的问题
(待商榷) Teacher Forcing 正好介于上述两种训练方法之间 。具体来说就是,训练过程中的每个时刻,有一定概率使用上一时刻的输出作为输入,也有一定概率使用正确的 target 作为输入
需要注意的一点是,与标准的KGE模型不同,训练没有明确的负采样。在解码的每一步,该模型产生可能的下一个记号的概率分布。在训练时,使用交叉熵损失,该分布因不同于“真实”分布而被扣分(即,真实的下一个表征的概率为1,所有其他表征的概率为0)。因此,该训练过程最类似于Ruffinelli等人(2020)中的1vsAll+CE损失,除了不是针对所有其他实体对真实实体进行评分,而是在每一步针对所有其他表征对真实表征进行评分,并且该过程重复与表征化的真实实体的长度一样多的次数。这避免了对许多底片的需要,并且与实体的数量无关。
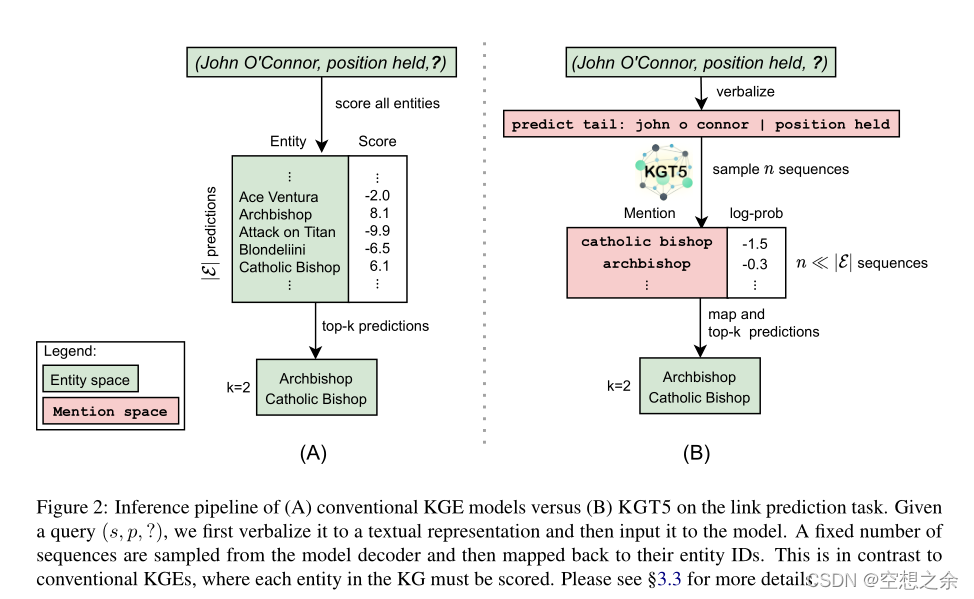
3.3 Link Prediction Inference
在传统的KGE模型中,回答一个查询(s,p,?)通过找到分数f(s,p,o) ∀o ∈E,其中f是特定于模型的得分函数。然后根据分数对实体o进行排名。在本文的方法中,给定查询(s,p,),先把它动词化(3.1)再喂给KGT5。然后,对来自解码器的固定数量的序列进行采样,然后将这些序列映射到它们的实体ids.8通过使用这样的生成模型,能够近似(以高置信度)top-m模型预测,而不必像传统KGE模型那样对KG中的所有实体进行评分。对于每个解码的实体,分配一个等于解码其序列的(对数)概率的分数。这给了一组(实体,分数)对。为了计算与传统KGE模型相当的最终排名指标,为抽样过程中未遇到的所有实体分配一个分数“∞”。传统KGE模型和KGT5的推理策略的比较如图2所示。
3.4 KGQA Training and Inference
对于KGQA,使用链接预测任务(3.2)在背景KG上预训练模型。这种预训练策略类似于其他KGQA工作中使用的“KGE模块训练”(孙等人,2021;任等2021)。然后,同一个模型被微调用于问题回答。因此,采用与Roberts等人(2020)相同的策略:将一个新的任务前缀(预测答案:)与输入问题连接起来,并将答案实体的提及字符串定义为输出。这种统一的方法允许将KGT5应用于任何KGQA数据集,而不管问题的复杂性,并且不需要子模块,例如实体链接。
为了在QA微调期间(特别是在具有小KG的任务上)对抗过拟合,作者设计了一个正则化方案:将从背景KG中随机采样的链接预测序列添加到每一批中,使得一批由相等数量的QA和链接预测序列组成。为了推断,使用波束搜索,然后使用基于邻域的重新排序(4.3)来获得模型的预测,该预测是单个答案。
4 Experimental Study
作者研究了KGT5(即一个简单的seq2seq Transformer模型)是否可以被联合训练来执行知识图链接预测以及问题回答。在本章节,作者首先描述使用的数据集(4.1),比较的基线(4.2)和实验设置(4.3)。实验结果在4.4-
4.8中进行了分析。在详细介绍之前,作者介绍了一下主要发现:
1.对于大kg上的链路预测,KGT5的基于文本的方法将模型大小减少到可比较的KGE模型的98%,达到或超过当前的最先进水平
2.在不完整KGs上的KGQA任务中,简单seq2seq方法在多个数据集上获得了比当前最先进的方法更好的结果。
3.KG链接预测训练可能比知识密集型任务(如KGQA)的语言建模预训练更有益。
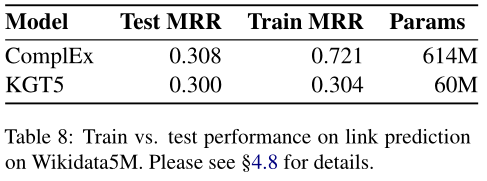
4.虽然KGT5擅长概括看不见的事实,但它在记忆事实方面相当糟糕。如果需要,这个问题可以通过使用KGT5和常规链路预测或KGQA系统的组合来缓解。
4.1实验结果
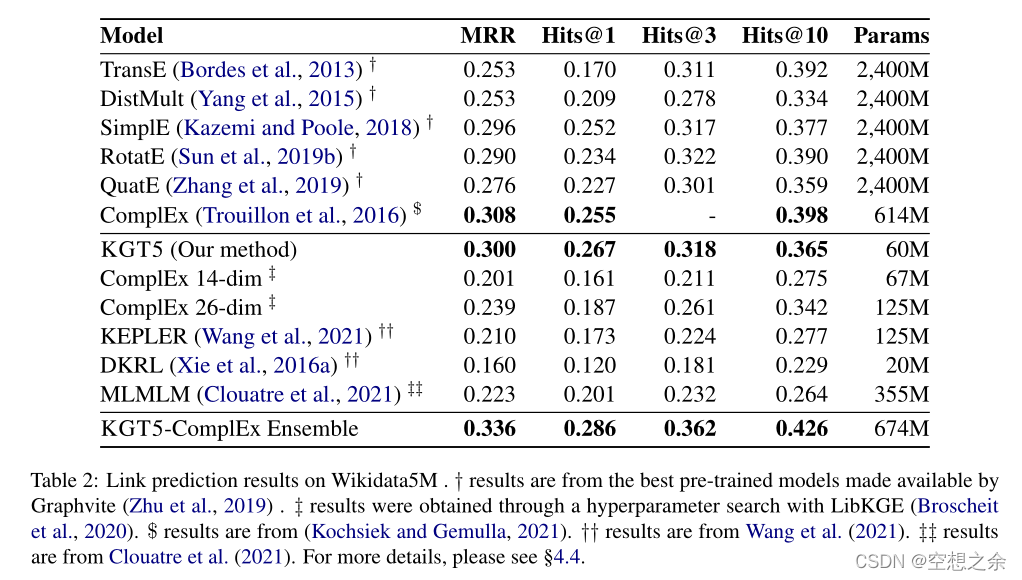
作者评估了KGT5在Wikidata5M和WikiKG90Mv2上的链接预测能力,这两个是最大的公开基准KGs。虽然KGT5是为大型问题设计的,但也在较小的基准KGs FB15k-237 、WN18RR和Y AGO310 上进行评估,以进行比较。
MRR,平均倒数排名,Mean Reciprocal Rank,越高越好。例:预测三次,第一次预测,正确结果排在第3位,第二次预测,正确结果排在第2位,第三次预测,正确结果排在第1位,系统的MRR为(1/3 + 1/2 + 1)/3 = 11/18
推荐算法常用评价指标:NDCG、MAP、MRR、HR、ILS、ROC、AUC、F1等
Wikidata5M上的链接预测结果
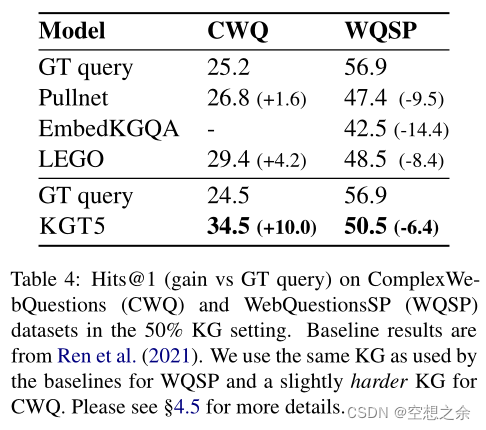
50% KG,CWQ和WQSP中@1。
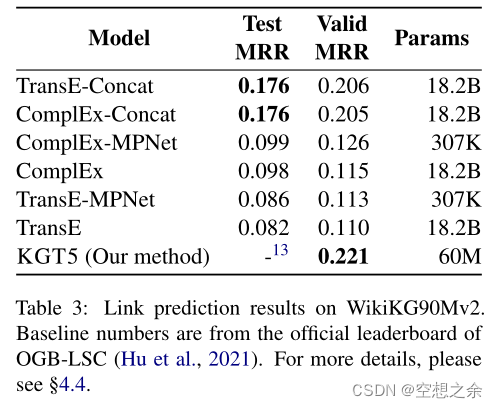
WikiKG90Mv2上的**链接预测
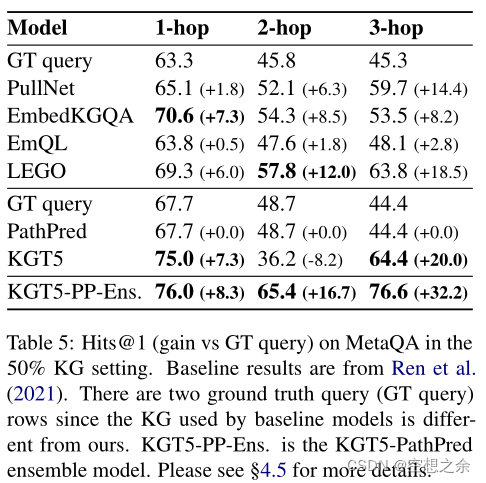
50% KG MetaQA** Hits@1
4.2 结果说明
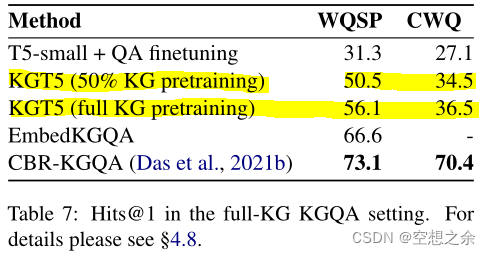
表7显示不如EmbedKGQA(一种基于复杂的方法)和CBR-KGQA。即尽管KGT5擅长概括看不见的事实,但它可能不擅长记忆事实。
作者建议不要****将KGT5作为一个独立的KGQA方法,只有当查询解析没有产生好的结果时才应该使用它。在比较使用实体名称/描述的模型和不使用实体名称/描述的模型时,必须小心谨慎。从实践的角度来看,可以利用文本数据的模型可能更有优势,并且在应用技术之前必须评估其利弊
5 Conclusion and Future Work
KG链接预测和QA可以被视为seq2seq任务,并且可以用单个编码器-解码器转换器模型来成功处理。通过在链接预测任务中训练一个与T5small具有相同架构的Transformer模型,然后在QA任务中对其进行微调来做到。也就是本文提到的KGT5,在大的KG上与最先进的KG完成方法竞争,同时使用的参数少了98%。在不完全KGs上的KGQA任务中,该统一方法在多个大规模基准数据集上优于基线。此外,比较了语言建模预训练和KG链接预测训练,发现对于知识密集型任务,如KGQA,链接预测训练可能更有益。
未来探索的一个有希望的方向是,在训练大型seq2seq模型时,是否可以将KG链接预测训练作为一个额外的预训练目标。此外,还应该研究模型大小的影响,以及较大的Transformer模型是否确实能够存储更多的关系信息。














 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









