







最近在学习LSTM(Long Short-term Memory ),网上的文章基本上都是基于下图对LSTM进行介绍。然而,有几个问题一直困扰着我:LSTM与传统RNN算法相比,它能够有效处理长依赖问题(long time lags),原因是什么呢?LSTM的网络架构为什么要设计成这样呢?引入门控机制的原因是啥呢?
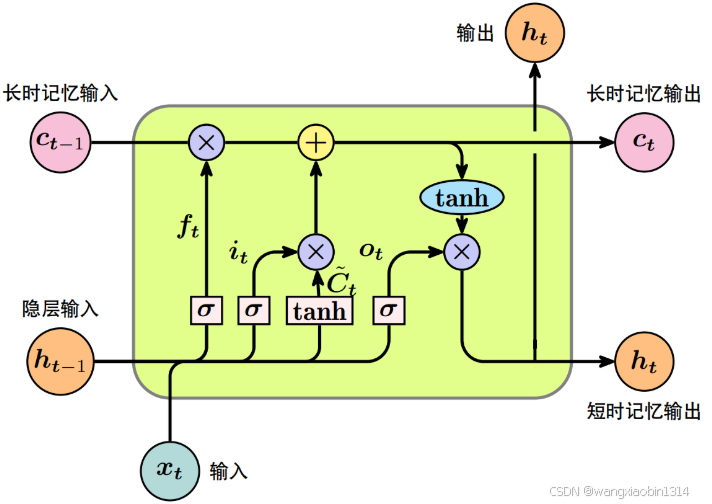
为了解答上述疑惑,我翻阅网上的文章、咨询DeepSeek和豆包,均没有找到我想要的答案。因此,我决定阅读原论文,通过论文去了解作者的思想。为了深度解读LSTM的思想,我将分两篇论文进行解析:一篇是Long Short-term Memory (Sepp Hochreiter,199),另一篇是Learning to Forget:Continual Prediction with LSTM(Felix A.Gers,1999)。本文先对Long Short-term Memory (Sepp Hochreiter,1997)进行精读。 Learning to Forget:Continual Prediction with LSTM(Felix A.Gers,1999)精读详见LSTM思想解析—论文精读(Learning to Forget: Continual Prediction with LSTM)。
一、传统RNN网络存在的问题
传统的RNN算法由于误差在反向传播时,存在梯度爆炸或梯度消失的问题,造成RNN无法处理长依赖问题。RNN为什么会出现梯度爆炸或梯度消失的问题呢?是由于RNN在反向传播计算偏导时有个连乘,具体公式推导可参考RNN循环神经网络之原理详解
的2.4节。
为此,作者就提出了一个大胆的想法:既然是因为梯度爆炸或梯度消失导致RNN不能处理长依赖问题。那么,如果误差在反向传播时在某个网络结构中保持不变,那么就可避免梯度消失或爆炸,不能处理长依赖的问题也就得到了解决。
二、CEC的提出(constant error carrousel)
既然误差在反向传播时保持不变(论文中叫恒定误差流,constant error flow)可以解决RNN存在的问题,那么满足什么条件可以达到误差流恒定呢?下面做公式推导。
对于传统的BPTT(BPTT是RNN做反向传播时所用到的一种算法,具体过程详见RNN循环神经网络之原理详解中2.3节反向传播推导),在时刻t计算各类神经元的误差:
1、对于RNN的某个输出层神经元K
设其输出值用表示,真实值用
表示,损失函数使用均方误差,那么k的误差信息可以表示为:
其中,
2、对于非输入层神经元i
假设其激活函数为,其输入为
表示从神经元j到神经元i的连接权重。那么,在t时刻神经元i的反向传播误差可表示为
也就是神经元i的误差是由各个与它相联的神经元的误差在t+1时刻的误差传过来的。(可借助BP神经网络的反向传播来理解这句话)
简单起见,作者首先假设非输入层神经元j它只有自连接(与其他神经元没有连接,只有自己和自己相连),那么根据上文公式,该神经元j在t时刻的误差为(换了个下标):
为了确保经过神经元j的误差不衰减(恒定误差流),即,根据上述公式需要满足:
由可得
根据定义: 又因为
且神经元j只有自连接,因此
。
所以:
根据
所以
由于 可设定
并且
这就是所谓的CEC(constant error carrousel)
三、输入门及输出门的提出原因
由于上述公式推导的假设前提是:非输入层的神经元j只有自连接,与其他神经元没有关系。当然,这是不可能的,神经元j必然会与其他神经元有关联。因此,就会引发两个问题:
-
问题一、输入权重冲突:为了简单起见,我们假设神经元j除了自连接外,还有个神经元i与它连接,连接权重为
(从i到j)。假设,对于来自于神经元i的某一输入激活了神经元j(该神经元j对这个输入产生的输出是否正确有较大影响),假设神经元i是非零。那么权重
-
问题二、输出权重冲突:假定神经元j被激活了,它目前存储着之前的某一输入。为了简单起见,神经元只与一个其他神经元k相连,权重
(从j到k)在某一时刻既要提取j的内容(此时j的内容可激活k),又要防止在其他时刻j去干扰k(防止j输出不相干的内容激活k)。例如,在许多任务中,在早期的训练阶段,要减少短时滞后误差;但在后期阶段,模型可能因为试图处理更复杂的长时滞误差而导致原本已控制的短时错误再次出现。也就是说权重
“短时滞后误差”:在训练初期,网络可能会关注那些与当前输入紧密相关的误差,即“短时间滞后误差”。这些误差通常是由于网络对最近输入的响应不够准确或及时造成的。例如,在语言模型中,如果网络在预测下一个词时只考虑了前一个词或很短的上下文,那么它可能会犯一些简单的语法或词汇错误。
“长时滞后误差”:随着训练的深入,网络开始尝试减少更复杂的“长时间滞后误差”。这些误差涉及更长的输入序列和更复杂的依赖关系。例如,在语言模型中,长时间滞后误差可能涉及对句子或段落整体结构的理解,以及对远距离词汇依赖的捕捉。
输入和输出权重冲突既可以出现在短时滞后中,也可以出现在长时滞后中。然而,在长时滞后情景中影响更为明显:随着时间滞后的增加(1)需要防止更多的输入信息的干扰,尤其在后期学习阶段;(2)越来越多的已经正确的输出也需要防止被干扰了。
四、LSTM网络架构
4.1 记忆细胞
为了解决输入和输出权重冲突,作者采用了CEC,并引入输入门和输出门去解决输入权重冲突和输出权重冲突问题。输入门单元的作用是保护存储在神经元j中的内容不受不相关输入的干扰(解决输入权重冲突)。同样的,输出门单元的作用是保护其他的神经元不受当前存储在神经元j中不相关的内容的干扰(解决输出权重冲突)。 于是就形成了一个比传统RNN更为复杂的单元:记忆细胞。
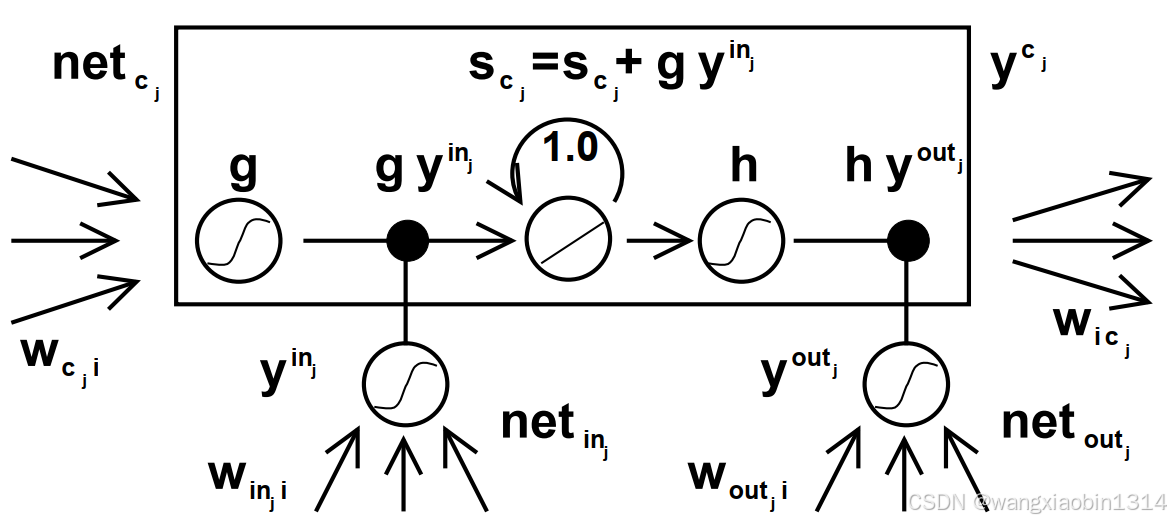
上图中,黑框中的便是记忆细胞。为输入门,
为输出门。自连接(权重为1)便是CEC。
表示第j个记忆细胞。每个记忆细胞都由中心线性单元+CEC构成。记忆细胞除了接收
的输入之外(该记忆细胞在上一时刻的输出),还接收来自输入门和输出门的输入。
其中:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









