






模型预测控制与强化学习-论文阅读(一)Integration of reinforcement learning and model predictive
最近才把初步的研究方向定下来,导师放养,实验室师兄师姐断代了,得靠自己摸索了,加油,多看论文多思考多动手!!!
这篇文章提出了Q-MPC,但是说实话,我看实验结果也没有表现出啥有优异。
看完之后,我对基于模型和无模型的强化学习的本质产生了好多疑问。。。
摘要
随着生物过程数字化改造的进展,一些研究建议应用基于数据的方法来获得一种基质供给策略,以最小化半间歇式生物反应器的运行成本。然而,由于可用数据量有限,疏忽应用无模型强化学习(RL)很可能无法改进现有控制策略。在本文中,我们提出了一种双深度Q网络和模型预测控制的集成算法。该方法以off-policy(异策略)的方式学习行动值函数,并解决了基于模型的最优控制问题,其中终端成本由动作价值函数分配。为了进行模拟研究,将所提出的方法、基于模型的方法和无模型方法应用于工业规模的青霉素过程(我也打算选用这个过程做研究)。
引言
(只列出一些对我稍微有启发意义的)
迄今为止,大多数研究采用基于模型的两级结构优化控制,其中执行开环优化以获得状态和输入参考轨迹,本地控制器跟踪这些参考。开环优化采用直接法、间接法、动态规划法,控制器一般选用MPC。
== **
然而
**==,将基于模型的最优控制应用于生物过程中存在两个问题:
- 模型-对象失配和在线计算的高计算成本。生物过程的系统动力学受细胞内代谢产物和酶调节的复杂生化反应控制。并且这些效应在宏观模型中表现为高度非线性或随机性。因此,用于基于模型的最优控制的集总模型涉及高水平的不确定性,这破坏了最优控制的性能。
- 此外,长操作时间使得难以准确预测产品质量,这在生物工艺的制造成本中占了很大一部分。这也意味着基于模型的最优控制预测到终端时间点的状态,这需要一个长的时间范围。
为了解决这些问题,一些研究建议应用无模型RL来获得最佳的基板进给策略。无模型RL的在线计算量比基于模型的控制(如MPC)要小得多,并且在理论上可以获得最优控制策略。
然而,使用无模型RL来获得生物过程的最佳进料策略可能会导致下列实际问题:
- 学习所需的数据量在实践中可能不可行。
- 所需的exploration不可行或明显损害工艺性能。
- 不可能明确施加状态约束。(只能在训练过程中限制范围?)
- 学习对超参数高度敏感。
- 如果成本(报酬)发生变化,要重新学习。
- 由此产生的控制策略不直观intuitive.。(应该是说不符合操作员直觉标准,可解释性不强)
在大多数情况下,建立在系统动力学先验知识基础上的模型在生物过程中可用。该可用模型可能不准确,但可用于计算在实践中提供有意义数据的近似最优输入。因此,我们提出了无模型RL和MPC的集成方法,与现有的无模型RL算法相比,该方法可以用相对较少的数据改进控制策略。
-
首先使用基于梯度的优化求解器,在连续动作空间上用DDQN算法描述优化问题。该方法是一种定义在连续动作空间上的off-policy算法,其中只有critic由深度神经网络近似。
-
然后,将最初表示为动作价值函数优化的actor推广为基于模型的最优控制问题。该基于模型的最优控制问题通过模型预测horizon内的状态和成本,并将动作价值函数设定为终端成本。
-
因此,所提出的方法可以被视为MPC的推广,因为actor以receding horizon fashion实现来自优化问题的控制输入。此外,通过将预测范围的长度设置为0,所提出的方法在连续动作空间中等效于DDQN。另一方面,通过将预计范围的长度设为整个批量操作时间,所提出方法等效于MPC。
提出的方法的优点如下所示。
- 它用更少的数据量改进了控制策略。
- 这是一种异策略算法。
- 它只需要学习critic,因此对超参数不太敏感。
- 可以明确施加状态约束。
- 可以明确exploration。
- 产生的控制策略更直观。
方法
一、NMPC
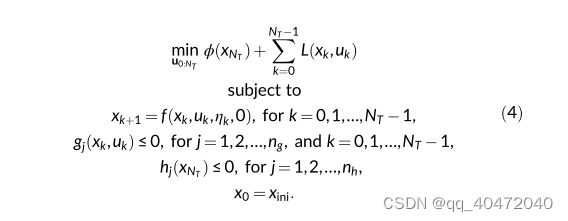
二、Model-free RL
在控制系统中,价值函数可以表示为:
动作价值函数:
得到了动作价值函数之后,就可以在不知道状态转移概率,得到最优控制策略:
Therefore, the model-free RL aims to obtain an optimal control policy
and the optimal action-value function without any knowledge of state
transition
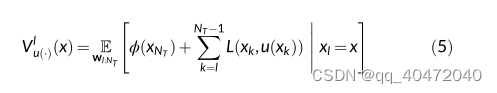
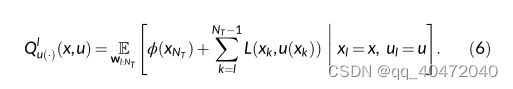

DQN:
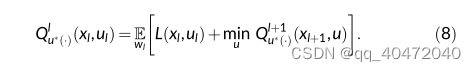
**
DDQN
**
DDQN是DQN的一种改进方法。

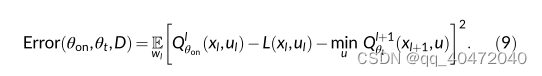
DQN存在Q值会被高估的问题,因为他在更新过程中自举(我通俗的理解为,用自己学习,然后就会高估自己。。)DDQN中选动作的Q网络跟计算Q值的Q网络不是同一个。
目标Q网络计算Q值,另一个Q网络选动作,更新参数。
**
策略梯度下降
**

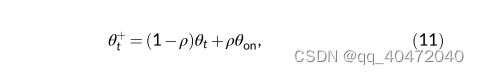
三、Q-MPC
跟DDQN类似,,但是DDQN中Actor是深度神经网络,而Q-MPC中Actor如下,通过滚动预测优化来选择动作。
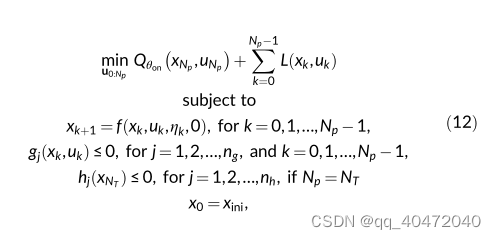
直接从工厂数据学习的action-value函数在预测时间段结束时设定(终端代价由Q函数表示?),因此所提出的Q-MPC可以有效地解决模型-工厂失配问题。
because the action-value function, which directly learns from the plant data, is assigned at the end of the prediction horizon, the proposed Q-MPC can effectively address the model-plant mismatch.
学习过程中,Q-MPC的学习过程类似于DDQN的学习过程。唯一的区别是对目标网络进行优化,DDQN通过枚举获得最优解。Q-MPC使用数值优化求解器来解决具有附加约束的优化问题,即


实验:青霉素产品生物反应器
我直接贴几个链接,青霉素仿真的一些平台和资料:
https://www.quartic.ai/blog/bridge-the-gap-of-process-control-and-reinforcement-learning-with-quarticgym/
https://download.csdn.net/download/sinat_15023595/9164655
https://www.sciencedirect.com/science/article/pii/S0168165614009377
仿真案例介绍:
青霉素发酵过程是一个典型的非线性、强耦合和滞后性的间歇过程。青霉素发酵过程被划分为两个阶段:菌体生长期和青霉素合成期。青霉素发酵过程是一个长时间持续的生产过程,其总过程大约在 400 h。前一个阶段是菌种生长阶段,持续 50 h~60 h,后两个阶段是青霉素合成和菌体衰老阶段,持续 340 h~350 h。在不同时期,菌体的生长环境又受诸多因素影响,在前两个阶段,青霉素生长的最佳温度是303 K,最佳 PH 是 6. 2~6. 5,在后两个阶段,青霉素合成的最佳温度是 298 K,最佳 PH 是 6. 5~6. 9。这使得青霉素发酵过程是一个非线性和多动态的过程,并且发酵过程有 9 个初始变量、7 个过程变量,这使得青霉素发酵过程是一个多输入和强耦合过程。

这个仿真案例可以在以下几个研究点上做研究
1确定影响青霉素生产的关键工艺参数(CPP)和关键质量属性(CQA)。
2开发软传感器,实时在线预测苯乙酸、生物量或青霉素浓度。
3为pH和温度变量制定增强的控制策略,与现有PID控制回路相比,将其波动降至最低。
4制定控制策略,控制以下一种或多种流量:底物、氮气或苯乙酸,以将这些变量保持在定义的可接受范围内。
系统简化模型
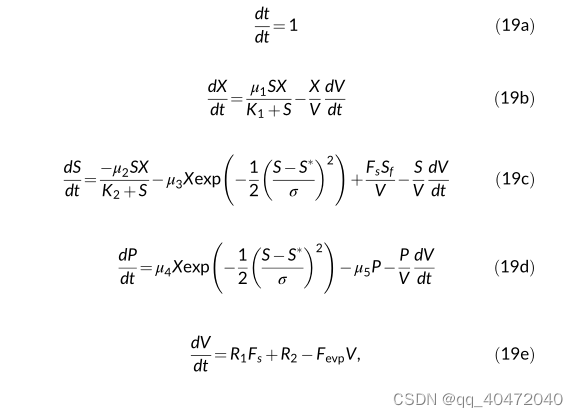
代价函数

控制问题
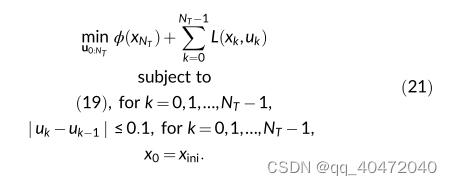
调参
在Python 3.7.0中使用CasADi编写和模拟虚拟工厂。优化问题也由CasADi编写,并通过IPOPT求解器进行数值求解。方程(19)的离散化通过有限元中的正交配置完成,动作值函数由深度神经网络近似,其中Keras API用于构建和学习深度神经网络。
深度神经网络有四层,其中每层的节点数分别为16、16、8和1。在DDPG的情况下,Actor也由具有三层的DNN近似,每层的节点数分别为8、8和1。对于所提出的方法,每100个时间步执行一次Critic学习,对于DDQN和DDPG,每20个时间步进行一次Critic学习。目标网络的更新是在更新在线网络五次之后执行的。等式(11)中的更新参数ρ设置为0.02。在缩放输入域中,等式(13)中的参数uex选择为0.1。batchsize选择为128,学习率选择为0.003。
结果 分析
原文分析了超级超级多。。。。。
仿真结果表明,与DDQN和DDPG相比,该方法以更少的数据量改进了控制策略,并且克服了模型对象失配问题,其性能也优于DDP。对于未来的工作,将研究Q-MPC的稳定性、递归可行性和鲁棒性。
感天动地,文章最后给出了代码链接: https://github.com/SNU-EPEL/Integration-of-Reinforcement-Learning-and-Model-Predictive-Control-to-Optimize-Semi-batch-Bioreactor














 1075
1075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









