







WACV2017 Author:Yu-Wei Chao
摘要
我们为HOI检测提出一个新的benchmark,HICO-DET。提出一个新模型HO-RCNN。模型的核心是Interaction Pattern,一种描述两个边界框之间空间关系的新型DNN输入。
1.介绍
本文主要有两个贡献:(1)提出HICO-DET数据集,它提供了超过15w个标注的人-对象对,跨越在HICO中的600个类别,即平均每个类别有250个实例。(2)提出了HO-RCNN,这是一种基于DNN的可以将检测单个bbox扩展到一对bbox的基于域的目标检测器,达到了当前SOTA。
代码和数据集:http://www-personal.umich.edu/~ywchao/hico/
2.相关工作
HOI检测:nothing useful.
目标检测:nothing useful.
3.HO-RCNN
我们的HO-RCNN以两步来检测HOI。第一步,用最SOTA的人和目标检测器来得到人-物的建议区域对。第二步,每个人-物建议区送入一个ConvNet来得到HOI分类的分数。我们的网络采用多流架构来提取被检测人、物体和人-物空间关系的特征。
人-物建议区域:我们首先得到人-物对的建议区域。一种简单的方法是像其他基于区域的对象检测方法一样,利用与类无关的边界框池化。但是,由于每个提建议区都是人与对象边界框的配对,因此建议区的数量将是候选边界框数量的平方。为了确保高召回率,通常需要保留数百到数千个候选边界框,这将导致成千上万的人-物建议区。相反,我们假设事先有一个感兴趣的HOI类别列表(例如“骑马”、“吃苹果”),这样我们就可以使用最先进的对象检测器首先检测人的边界框和感兴趣的对象类别(例如“马”、“苹果”)。我们保持bbox有最高的检测得分。对于每一个HOI类别(如“骑马”),通过将检测到的人和感兴趣的检测到的物体(如“马”)配对生成建议区,如图2所示。

多流结构:如图3,不同的流提取不同来源的特征。为了说明我们的想法,考虑一个HOI类的分类“骑自行车”。直观地说,人类和物体周围的局部信息,如人体姿态和物体局部上下文,是区分HOIs的关键,此外,人-物空间关系也是重要线索。我们的多流结构是由三个流组成的,它们对上述方法进行了编码:(1)human stream从检测到的人中提取局部特征。(2)object stream从检测到的物中提取局部特征。(3)pairwise stream提取成对编码检测到的人和物的空间关系的特征。每个stream的最后一层是为HOI输出一个置信分数的二进制分类器。最终的置信分数由所有stream的分数相加。为了扩展到多个HOI类,我们在每个stream的最后一层为每个HOI类训练一个二进制分类器。最后的分数是每个HOI类中所有stream相加。
人和物Stream:给定一个人-物建议区,human stream从human bbox中提取局部特征并产生置信分数。整张图片先使用bbox进行处理,并resize到一个固定的尺寸。然后,这个归一化的图像patch被送入到一个卷积网络中,该网络通过一系列卷积、最大池化和FC层来提取特征。最后一层是一个长度为K的FC层,其中K是HOI感兴趣的类别数量,同时每个输出是对应每一类的置信分数。object stream和human stream设计是一样的,但是输入是从人-物建议区的object bbox中裁剪和调整大小的。
Pairwise Stream:由于关注的是人和物的空间配置,所以这个stream的输入时应该忽略像素值,只使用bbox的位置信息。我们没有直接将bbox坐标作为输入,而是提出了交互模式(Interaction Patterns),这是一种特殊类型的DNN输入,用于表示两个bbox的相对位置。给定一对bbox,Interaction Patterns是一个2通道的二值图:第一个通道在第一个bbox所包围的像素处值为1,在其他地方值为0;第二个通道在被第二个bbox包围的像素处的值为1,在其他地方的值为0。在我们Pairwise Stream中,第一个通道对应于human bbox,第二个通道对应于object bbox。
虽然Interaction Patterns能够描述成对的空间配置,但仍然有两个重要的细节需要解决。首先,对于相同的配对配置,无论配对出现在图像的右侧还是左侧,Interaction Pattern应该是相同的。因此,我们从Interaction Pattern中删除了“attention window”之外的所有像素,只保留包含两个bbox的窗口。第二,Interaction Pattern的宽高比可能会根据attention window的不同而有所不同,但DNN输入是固定尺寸的。我们提出两种策略来解决这个问题:(1) 不考虑Interaction Pattern的长宽比直接把它的两边resize到一个固定尺寸,注意这会改变attention window的长宽比。(2)在保持长高比的情况下把Interaction Pattern的长边resize到一个固定长度,再把短边的两侧用0填充到固定的长度。


用多stream分类损失进行训练:一个人可以做多个动作,所以HOI识别应该被当做多标签分类。所以我们在每个HOI分类器输出后面使用一个sigmoid交叉熵损失进行训练,然后把所有独立损失相加来计算总的损失。
4.构造HICO-DET
Nothing Useful!
5.实验
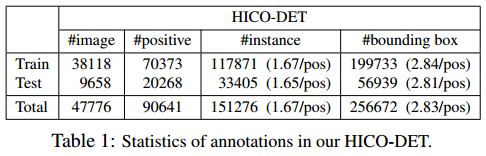

总结
1.公开了一个更大更牛批的数据集:HICO-DET,后面所有的HOI论文都是在V-COCO和HICO-DET上进行训练和测试的。
2.提出了一个HO-RCNN模型,human stream和object stream采用相同的设计,只是输入分别是human bbox和object bbox,其中pairwise stream使用二通道二值图的方法,:即human bbox和object bbox各为一个通道,其中bbox以内的值设为1,bbox以外的设为0。(这个方法后面有人用的)
3.其实这篇论文对网络细节没啥描述,不过幸好有代码。然后就是要注意在处理Interaction Pattern尺寸的时候那两种resize的方法。
思考:感觉这时候方法主要在两点创新:(1)怎么把别的东西加进来,比如iCAN加注意力机制,Scale那篇加零样本学习等等。(2)如何处理interaction分支,human和object分支比较固定,interaction分支更需要提取相关更精细更有用的交互信息。















 1644
1644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









