









上一篇介绍了双目视觉检测技术及应用,这一篇聊一聊光度立体法。
光度立体法原理
光度立体法是一种通过测量物体表面上不同点的亮度来推测物体的形状和深度的方法。其原理基于以下假设:
- 光线在触及物体表面时,会在不同的点上产生不同的亮度。
- 光线越靠近物体表面垂直入射,则亮度越高。
- 光线越远离物体表面垂直入射,则亮度越低。
基于这些假设,光度立体法通过观察物体表面上不同点的亮度差异,推断出物体表面的形状和凹凸程度。具体步骤如下:
- 选择一条光线,并将其沿与物体表面垂直的方向照射到物体上。
- 测量不同点上的亮度,并记录每个点的亮度数值。
- 根据亮度数值的差异,推断出物体表面上不同点的高低关系。
- 根据高低关系,构建物体的三维模型。
需要注意的是,光度立体法的原理假设光线在垂直入射时能够准确反映物体表面的高低关系。然而,在现实情况下,光照条件、表面材质等因素会对测量结果产生一定的干扰,需要通过一定的校正和处理方法来提高测量精度。
光度立体法有哪些应用?
光度立体法在计算机视觉和计算机图形学领域有着广泛的应用。以下是一些使用光度立体法的应用:
-
三维重建:通过使用多个相机同时捕捉同一个场景的图像,利用光度立体法可以准确地重建出场景中物体的三维形状和位置。
-
深度估计:光度立体法可以用于估计图像中每个像素的深度信息,从而实现对图像的深度感知和测量。如检测平坦平面上的缺陷,检测洗发水瓶上的缺陷,读取盲文等
-
虚拟现实和增强现实:在虚拟现实和增强现实应用中,光度立体法可用于实时地获取用户视角下的三维深度信息,从而实现真实感的渲染和交互。
-
自动驾驶和机器人导航:利用光度立体法可以获取机器人周围环境的深度信息,从而帮助机器人进行导航和避障。
-
视频处理和图像编辑:光度立体法可以用于对视频和图像进行景深效果的添加和编辑,从而增强图像的视觉效果。
光度立体法与双目视觉技术的区别?
光度立体法和双目视觉技术都是用于获取场景的三维信息的方法,但它们有一些区别:
-
原理:光度立体法基于图像中像素之间的光强度信息来推断深度关系,通过对多个图像进行比较,可以计算出每个像素的深度。而双目视觉技术则是利用两个相机同时拍摄同一个场景,通过计算两个相机之间的视差(即对应点之间的像素偏移量),从而推断出深度信息。
-
硬件需求:光度立体法只需要使用一个相机对应多个角度光源来捕捉图像,而双目视觉技术需要使用两个相机配合固定角度的光源来同时捕捉不同视角的图像。
-
精度和稳定性:由于光度立体法是基于图像强度的变化,因此在光照条件变化较大或纹理缺乏的情况下,其深度估计可能会受到影响。而双目视觉技术可以通过比较两个视角的图像来减少光照变化造成的影响。
-
解决问题的范围:光度立体法主要用于计算物体的深度信息,而双目视觉技术不仅可以计算深度,还可以进行物体识别、跟踪、立体匹配等。光度立体法在静态场景的三维重建和深度估计方面有着广泛的应用。而双目视觉技术不仅可以用于静态场景的深度估计,还可以用于动态场景下的实时跟踪和位姿估计。
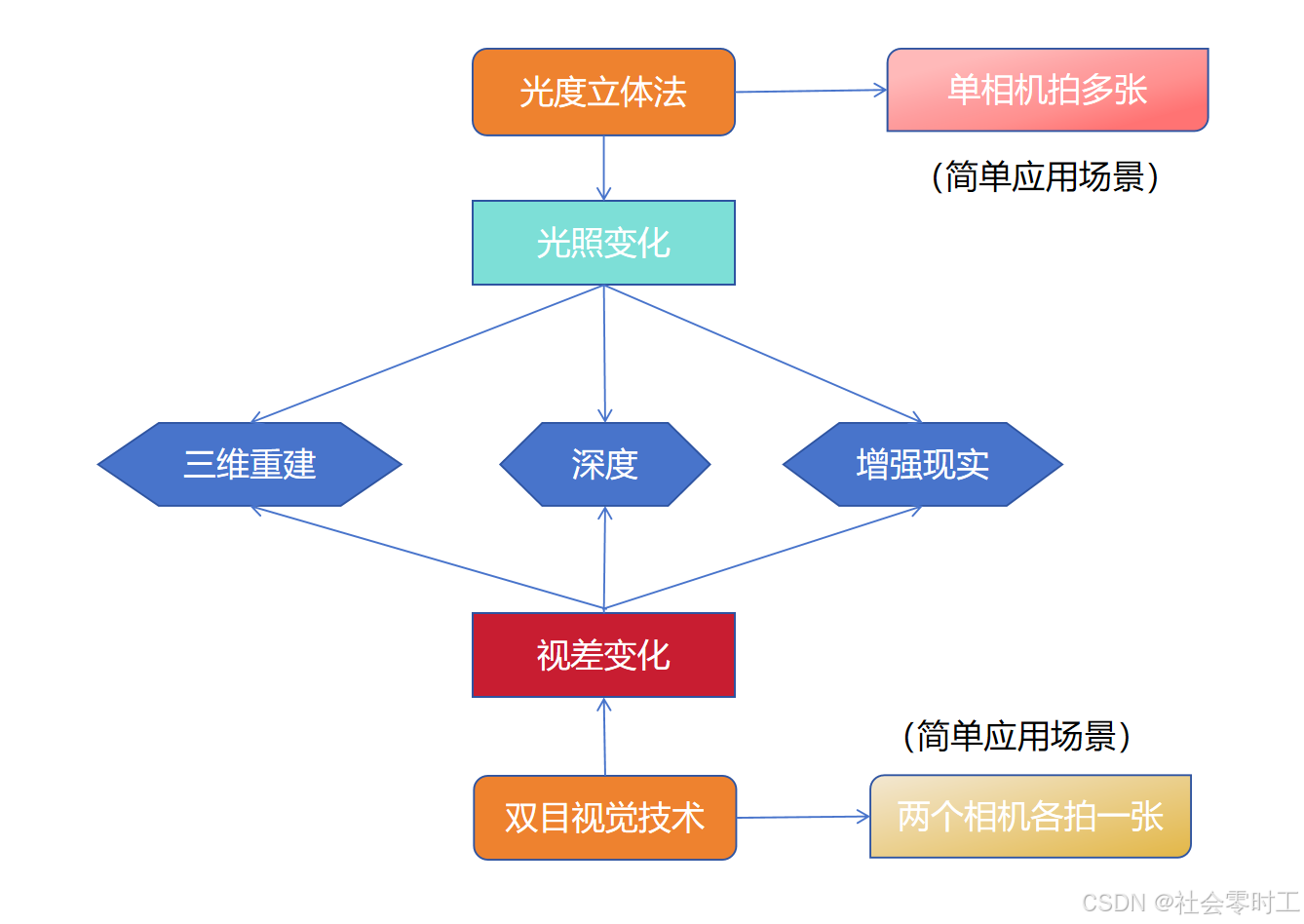
总的来说,光度立体法更适用于光照条件较好、有纹理的环境下进行深度估计,而双目视觉技术更适用于更广范围的计算机视觉问题。虽然光度立体法和双目视觉技术都是计算物体深度的方法,但它们的原理和应用有所不同,每种方法都有其适用的场景和限制。在具体应用时,需要根据实际需求选择适合的方法。
光度立体法检测表面缺陷示例
import cv2
import numpy as np
def compute_disparity(img1, img2):
# 转换为灰度图像
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 使用SIFT特征匹配
sift = cv2.SIFT_create()
keypoints1, descriptors1 = sift.detectAndCompute(gray1, None)
keypoints2, descriptors2 = sift.detectAndCompute(gray2, None)
# 使用暴力匹配
bf = cv2.BFMatcher()
matches = bf.knnMatch(descriptors1, descriptors2, k=2)
# 筛选好的匹配点
good_matches = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good_matches.append(m)
# 计算视差图
disparity_map = np.zeros_like(gray1, dtype=np.float32)
for match in good_matches:
x1, y1 = keypoints1[match.queryIdx].pt
x2, y2 = keypoints2[match.trainIdx].pt
disparity_map[int(y1), int(x1)] = abs(x1 - x2)
# 归一化到0-255范围
disparity_map = cv2.normalize(disparity_map, None, alpha=0, beta=255, norm_type=cv2.NORM_MINMAX, dtype=cv2.CV_8U)
return disparity_map
# 读取两幅图像
left_image = cv2.imread('left_image.jpg')
right_image = cv2.imread('right_image.jpg')
# 计算视差图
disparity_map = compute_disparity(left_image, right_image)
# 进行图像缺陷检测
# ...
# 显示视差图
cv2.imshow('Disparity Map', disparity_map)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个示例中,我们首先将图像转换为灰度图像,并使用SIFT特征描述符进行特征匹配。然后,使用暴力匹配方法筛选出最佳匹配点。根据匹配点的坐标差异计算视差图,然后对视差图进行归一化处理,最后显示视差图像。
需要注意的是,此示例仅提供了一个简单的实现示例,并仅考虑了基本的特征匹配和视差计算过程。在实际应用中,还需要根据具体情况进行参数调整和优化,以获得更好的检测结果。后续缺陷检测,可根据具体的特征,选择blob分析,或者深度学习相关的分类,分割模型进行筛选查找都可以。

















 1401
1401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









