






3.提出的单目语义SLAM
在这一部分中,我们将阐述所提出的三维重建框架,其中CNN预测的稠密深度图与从直接单目SLAM获得的深度测量数据相融合。此外,我们还展示了CNN预测的语义分割如何与全局重建模型相融合。图2中的流程图描述了框架概况。我们采用基于关键帧的SLAM[12,4,20],特别是我们使用[4]中提出的直接半稠密方法作为基线。在这种方法中,视觉清晰帧的子集被收集为关键帧,其位姿基于图优化进行全局优化。同时,通过估计帧与其最近的关键帧之间的变换,在每个输入帧处进行相机姿态估计。
为了保持较高的帧率,我们仅在关键帧上通过CNN预测深度图。特别是如果当前估计的位姿与现有关键帧的位姿相差很远,则从当前帧创建新的关键帧,并通过CNN估计其深度。此外,通过测量每个深度预测的像素置信度来构造不确定度图。由于在大多数情况下,用于SLAM的摄像机不同于用于获取CNN训练数据集的摄像机,因此我们提出了一种特定的深度图归一化过程,以形成对不同摄像机内参的鲁棒性。另外,在进行语义标签融合时,我们使用第二个卷积网络来预测输入帧的语义分割。最后,在关键帧上创建一个位姿图,以便全局优化它们的相对位姿。
该框架的一个特别重要的阶段,也代表了我们的文章的一个主要贡献,是通过短基线立体匹配,通过优化关键帧和相关输入帧之间的灰度一致性最小化,来优化与每个关键帧相关联的CNN预测深度图。特别是,深度值将主要围绕具有梯度的图像区域进行优化,即在极线匹配可以改善精度的区域。这将在第3.3和3.4小节中具体描述。相关地,深度值的优化是由与每个深度值相关联的不确定性所决定的,该不确定性是根据一个特殊的置信度估计的(见下文3.3)。框架的每个阶段都会在下面的小节中详细介绍。
3.1 相机位姿估计
相机位姿估计方法是受[4]中关键帧方法启发的。系统有一组关键帧k1…kn∈K作为进行SLAM重建的结构元素。每个关键帧ki与关键帧位姿Tki、深度图Dki和深度不确定度图Uki相关联。与[4]相比,我们的深度图是稠密的,因为它是通过基于CNN的深度预测生成的(见第3.2节)。不确定度图表示每个深度值的置信度。与[4]将不确定度初始化为一个很大的恒定值不同,我们的方法根据深度预测的测量置信度来初始化不确定度(见3.3节)。在下面,我们将把一个通用的深度映射元素记为u=(x,y),它在图像域中有固定范围u∈Ω⊂|R2(|R2为2维欧氏空间),u˙是它的齐次表示。
在每一帧t上,我们的目标是估计当前相机的位姿T ,即最近的关键帧ki和帧t之间的转换,由3×3的旋转矩阵Rt∈SO(3)和3D平移向量tt∈|R3组成。基于目标函数的加权高斯-牛顿优化方法,通过最小化当前帧的强度图像It和最近关键帧ki的强度图像Iki之间的光度残差来估计该变换。
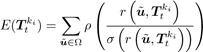
其中,ρ是Huber范数:

σ是测量残差不确定度的函数[4]。这里,r是光度残差,定义为:
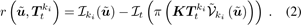
考虑到我们的深度图是稠密的,为了提高效率,我们将光度残差的计算限制在高灰度梯度区域内的像素子集上,该像素子集由图像域子集u˜ ⊂ u∈ Ω定义。另外,在(2)中,π表示将3D点映射到2D图像坐标的透视投影函数。
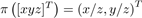
而Vki(u)表示从关键帧的深度图计算得到的三角测量的三维元素
Vki(u) = K-1u˙Dki (u) (4)
其中K是相机内部矩阵。
获得Ttki后,世界坐标系中的当前相机姿态计算为Tt=TtkiTki。
3.2 基于CNN的深度预测与语义分割
每次创建新的关键帧时,都会通过CNN预测相关的深度图。我们采用的深度预测结构是基于[16]中提出的最新方法,它将残差网络(ResNet)[9]扩展为全卷积网络。具体来说,架构的第一部分基于ResNet-50[9],并使用图像网络上的预先训练好的权重初始化[24]。该体系结构的第二部分用一系列由非池化层和卷积层组合而成的剩余上采样块,取代了ResNet-50中提出的最后一个池化层和全连接层。在上采样之后,在最终卷积层之前丢弃(???),最终卷积层输出表示预测深度图的单通道输出图。损失函数基于反向Huber函数[16]。
遵循其他方法的成功典范,在深度预测和语义分割任务中采用相同的架构[3,29],我们还重新训练了该网络,以从RGB图像中预测像素级语义标签。为了解决这一问题,我们对网络进行了改进,使其具有与类别数量相同的输出通道,并采用softmax层和交叉熵损失函数,通过反向传播和随机梯度下降(SGD)来最小化。必须指出的是,虽然原则上可以使用任何语义分割算法,但这项工作的主要目标是展示如何在我们的单目SLAM框架内成功融合逐帧级分割地图(见3.5)。
3.3 关键帧创建和位姿图优化
使用预训练的CNN进行深度预测的一个局限是,如果用于SLAM的传感器和用于获取训练集的传感器内参不同,则3D重建的最终绝对尺度将不准确。 为了改善这个问题,我们使用当前摄像机的焦距fcur和用于训练的传感器焦距ftr之比来调整CNN回归的深度。
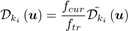
其中D〜ki是由CNN直接从当前关键帧图像Ii回归的深度图。
图3展示了在ICLNUIM数据集[8]上进行过程的调整,效果非常显著(5)(比较(a)和(b))。如图所示,与CNN直接预测的深度图相比,调整后的性能有了显著的提高。改进后的位姿追踪精度和深度精度都得到了提高。
(A) Comparison on Pose Trajectory Accuracy

图3 (a)直接CNN深度预测 (b)深度调整后和 (c)深度调整和细化后(A)位姿轨迹精度 (B)深度估计精度
蓝色像素表示正确估计的深度,即误差在真实数据的10%以内。这是在ICL-NUIM数据集上进行比较的[8]。
此外,我们将每个深度图Dki与不确定性图Uki相关联。在[4]中,通过将每个元素设置为一个大的常量值来初始化这个图。由于CNN在每一帧上都是稠密图,但不依赖于任何时空正则化,因此我们提出通过基于当前深度图,与在最近关键帧上的场景点之间的差异,来计算置信值,从而初始化我们的不确定性图。因此,这种置信度表示了每个预测深度值在不同帧之间的差异性:对于与高置信度相关联的那些元素,连续的求精过程将比[4]中的过程快并且有效得多。
具体地说,不确定性图Uki定义为当前关键帧ki的深度图与最近关键帧kj的深度图之间的元素平方差,ki到kj的估计变换值为Tkikj.
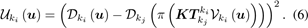
为了进一步提高每个新的初始化关键帧的精度,我们在使用新的输入帧(深度细化过程在第3.4小节中描述)对其深度图和不确定性图进行细化后,将其与从最近的关键帧(这显然不适用于第一个关键帧)传播的深度图和不确定性图进行融合。为了达到这个目的,我们首先定义了一个从最近的关键帧kj传播的不确定性图为:
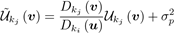
其中v ,根据[4],σ2p是用于增加传播不确定度的白噪声方差。然后,将两个深度图和不确定性图按照加权方案融合在一起。
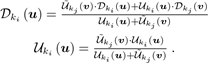
最后,位姿图也在每个新的关键帧处更新,方法是使用图中已经存在的关键帧创建新边,这些关键帧与新添加的关键帧有着相似的区域(即具有较小的相对位姿)。此外,关键帧的位姿每次都通过位姿图优化进行全局优化[14]。
3.4 逐帧深度细化
此阶段的目的是基于在每个新帧处估计的深度图,连续地细化当前关键帧的深度图。为了实现这一目标,我们使用了文献[5]中描述的短基线立体匹配策略,通过在当前帧t的每个像素处计算深度图Dt,和沿极线的5-像素匹配的不确定性图Ut。这两个图基于估计的相机姿态Tkit与关键帧ki对应。
然后,将估计的深度图和不确定度图直接与最近的关键帧ki的深度图和不确定度图融合:
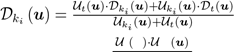
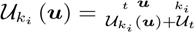
重要的是,由于提出了基于CNN的预测,关键帧与稠密深度图相关联,因此可以稠密地执行此过程,即关键帧的每个元素都被细化,而不是像[5]一样仅沿高梯度区域细化深度值。由于低纹理区域内的观测深度往往具有很高的不确定性(即Ut值较高),因此,所提出的方法自然会产生一个精细的深度图,其中靠近高强度梯度的元素将通过在每个帧处估计的深度进行精细化,而大量的低纹理区域内的元素将逐渐保持CNN的预测深度值,而不受不确定深度观测的影响。
图3展示了在ICL-NUIM数据集上进行深度图细化过程的高效[8]。图(c)表示,对深度图进行调整和深度细化后获得的性能,在深度估计和位姿追踪方面,相对于以前的情况有了显著改进。
3.5 全局模型与语义标签融合
上述过程得到的关键帧可以融合在一起,生成重建场景的三维全局模型。由于CNN被训练为除了深度图之外,还可以提供语义标签,通过一个我们称为语义标签融合的过程,语义信息还可以与3D全局模型的每个元素相关联。
在我们的框架中,采用了文献[27]中提出的实时方案,其目的是将从RGB-D序列的每个帧获得的深度图,和连通分量图逐步融合在一起。该方法使用Global Segmentation Model(GSM)来平均每个3D元素随时间的标签分配,从而对逐帧分割中的噪声具有鲁棒性。在我们的例子中,位姿估计是作为算法的输入提供的,因为相机位姿是通过单目SLAM估计的,而输入深度图是那些只与关键帧相关联的。这里,我们使用语义分割图,而不是[27]中的连通分量图。场景的三维重建是在新的关键帧上逐步构建,其中每个三维元素都与用于训练CNN的集合中的语义类相关联。















 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









