







MapReuduce
1,MapReduce 概念
Mapreduce 是一个分布式运算程序的编程框架,其核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 hadoop 集群上。
Mapreduce 易于编程、扩展性好、适合处理PB级别数据;但是他不适合处理实时数据,流失计算、有向图计算等。
2,MapReduce 设计理念
MapReduce 思想模块主要分为:Input、Spilt、Map、Shuffle、Reduce 等。
Input:Read 读取数据;InputFormat 将文件拆分为多个 InputSplit,并由 RecordReaders 将 InputSplit 转换为标准的<key,value>键值对,作为 map 的输出;
Spilt:此过程对数据按行进行粗粒度切分,得到<Key,Value>型数据;
Map:细粒度切分,得到<Key,List>型数据;在环形缓冲区内对文件进行排序、分区操作,数据量大时会溢写到磁盘,缓冲区大小将决定着 MR 任务的性能,默认 size 为 100M。此过程可以设置 Combine 任务,即将按照相同 Key 进行初步聚合(partion>3 才会combine);
combine:初步聚合 Merge,主要包括按照分区号、相同 key 等策略,且同一分区内数据有序;
Shuufle:洗牌,即将各个 MapTask 结果合并输出到 Reduce,此过程数据的输出是一个 Copy 过程,此过程涉及到网络 IO ,是一个耗时的过程,也是一个核心的过程。
Reduce:对拆开的数据碎片进行合并。会涉及到 Merge 排序。
Partition:支持自定义输出分区,默认的分类器是 HashPartition。公式:(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks


下面我们试图阐述一下,MapReduce 具体的运行过程:
- 客户端提交任务之前,(InputFormat)会根据配置策略将数据划分为切片(SpiltSize 默认为 blockSize 128M) ,每个切片都对应的提交给一个 MapTask (YARN 负责提交);
- MapTask 执行任务,根据 map 函数,生成<K,V>对,将结果输出到环形缓存区,然后分区、排序、溢出;
- Shuffle,即将 map 结果划分到多个分区并分配给了多个 reduce 任务,此过程即为 Shuffle。
- Reduce,拷贝 map 后分区的数据(fetch过程,默认5个线程执行拷贝),全部完成后执行合并操作。

分布式特质在于一个 Job 有多个 MapperTask、Shuffle、Reduce。下图很好的说明了分布式并行过程。

3,mapreduce 程序编写:
MR 程序编写框架:
1)Mapper 阶段
(1)用户自定义的 Mapper 要继承自己的父类
(2)Mapper 的输入数据是 KV 对的形式(KV 的类型可自定义)
(3)Mapper 中的业务逻辑写在 map()方法中
(4)Mapper 的输出数据是 KV 对的形式(KV 的类型可自定义)
(5)map()方法(maptask 进程)对每一个<K,V>调用一次
2)Reducer 阶段
(1)用户自定义的 Reducer 要继承自己的父类
(2)Reducer 的输入数据类型对应 Mapper 的输出数据类型,也是 KV
(3)Reducer 的业务逻辑写在 reduce()方法中
(4)Reducetask 进程对每一组相同 k 的<k,v>组调用一次 reduce()方法
3)Driver 阶段
整个程序需要一个 Drvier 来进行提交,提交的是一个描述了各种必要信息的 job 对象。
4,MapReduce 经典词频统计案例
现编写第一个 MapReduce 程序实现 WordCount 案例:
环境准备:
IDEA新建一个 maven 工程,引入 hadoop 对应版本的核心依赖,并将配置文件纳入到资源管理中:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
1,编写map程序
public class WordCountMap extends Mapper<LongWritable, Text,Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
//重写map方法,实现业务逻辑
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1,获取一行
String line = value.toString();
//2,切割
String[] words = line.split(" ");
for(String word:words){
k.set(word);
context.write(k,v);
}
}
}
2,编写reduce程序
public class WordCountReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//子类构造方法中会有一个默认隐含的super()方法,用于调用父类构造
//super.reduce(key, values, context);
int sum = 0;
for(IntWritable count:values){
sum += count.get();
}
context.write(key,new IntWritable(sum));
}
}
3,编写驱动类
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1,获取job
Configuration configuration = new Configuration();
Job job = Job.getInstance();
//2,设置jar加载路径
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
// 4 设置 map 输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置 Reduce 输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
然后使用工具将 main 文件打成 jar 包:
在project structre->加入Artifacts,选择From moudles from dependencies,选择自己的 main 类,并设置 jar 包输出目录;然后通过工具栏的 Build,选择 build Artifacts->build 即可达成 jar 包。最后就是通过 FTP 工具,将 jar 包发送到集群环境中,使用以下命令即可运行。
hadoop jar jar包名 main类的全类名 输入目录 输出目录

5,开发技巧
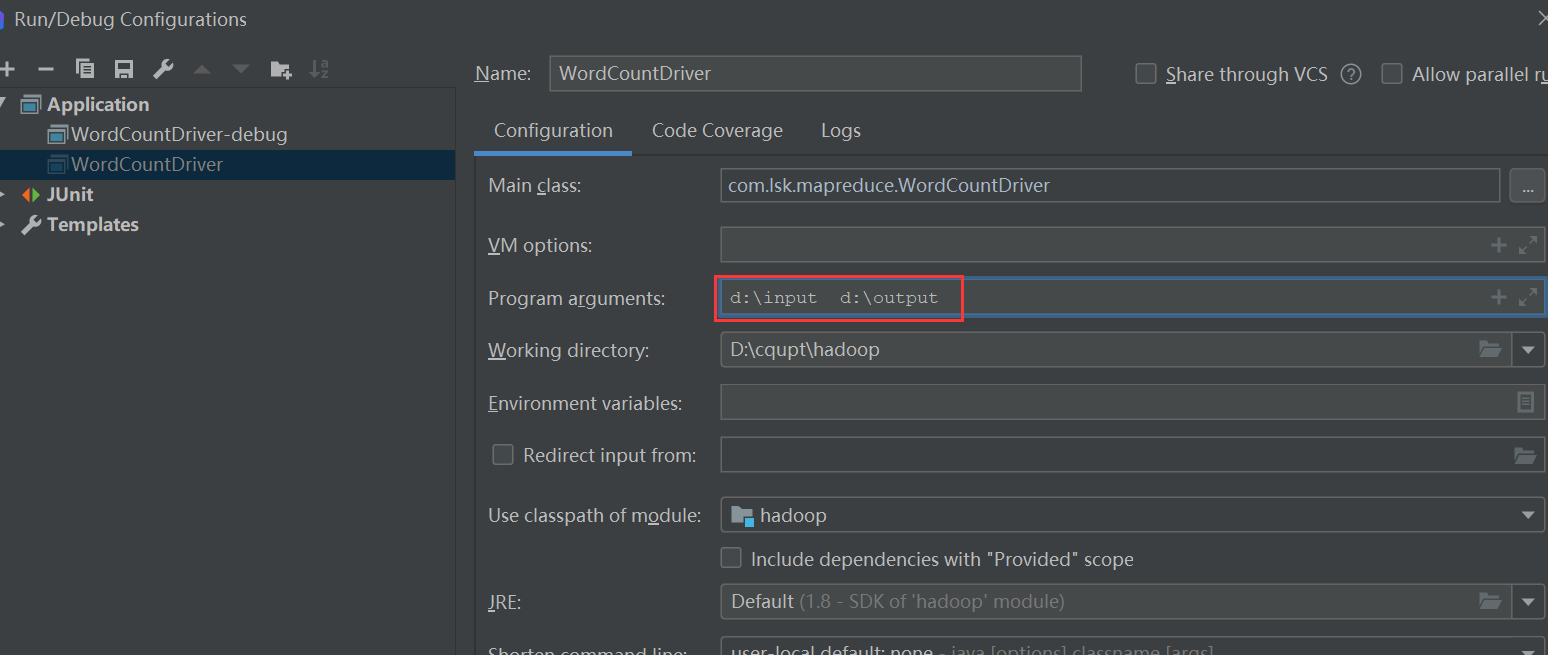
那么如何在本地运行 mapreduce 程序呢?
在实际的生产开发中,程序需要在本地测试无误后再打成 jar 包发布到集群中的。
首先我们需要设置 main 类的 configuration,提前添加好输入输出参数:
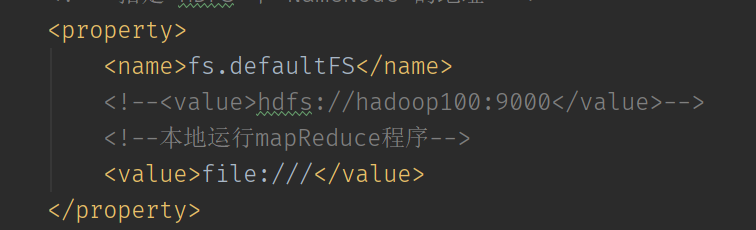
然后设置将文件系统修改为本地运行模式:
参考链接















 4934
4934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









