







XGBoost算法
1,算法简介
XGBoost(Extreme Gradient Boosting),即一种高效的梯度提升决策树算法。他在原有的GBDT基础上进行了改进,使得模型效果得到大大提升。作为一种前向加法模型,他的核心是采用集成思想——Boosting思想,将多个弱学习器通过一定的方法整合为一个强学习器。即用多棵树共同决策,并且用每棵树的结果都是目标值与之前所有树的预测结果之差 并将所有的结果累加即得到最终的结果,以此达到整个模型效果的提升。
XGBoost是由多棵CART(Classification And Regression Tree),即分类回归树组成,因此他可以处理分类回归等问题。
2,算法推导
下图是一个预测一家人喜欢电脑游戏的回归问题。可以看到样本落到叶子结点,对应的权重即为样本的回归分数。多棵树的预测结果即为最终的结果。
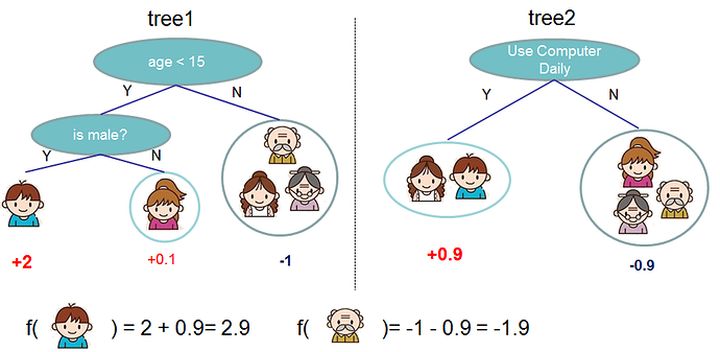
上面的模型可定义为:
y ^ i = ∑ k = 1 K f k ( x i ) , f k ∈ F \hat{y}_{i}=\sum_{k=1}^{K} f_{k}\left(x_{i}\right), f_{k} \in \mathcal{F} y^i=k=1∑Kfk(xi),fk∈F
其中,K表示树的数目,f表示函数空间F中的一个函数,代表树这种抽象结构。那么 y i ′ y_i^{\prime} yi′表示的即为最终预测结果。我们定义目标函数为:
obj ( θ ) = ∑ i n l ( y i , y ^ i ) + ∑ k = 1 K Ω ( f k ) \operatorname{obj}(\theta)=\sum_{i}^{n} l\left(y_{i}, \hat{y}_{i}\right)+\sum_{k=1}^{K} \Omega\left(f_{k}\right) obj(θ)=i∑nl(yi,y^i)+k=1∑KΩ(fk)
其中, l l l为我们的损失函数,Ω为惩罚项。它在形式上如下图所示:

对于增量模型的定义,我们是用每一个树的预测结果去拟合上一棵树预测结果的残差,这样整体的树模型效果才会越来越好。
y ^ i ( 0 ) = 0 y ^ i ( 1 ) = f 1 ( x i ) = y ^ i ( 0 ) + f 1 ( x i ) y ^ i ( 2 ) = f 1 ( x i ) + f 2 ( x i ) = y ^ i ( 1 ) + f 2 ( x i ) \begin{aligned} \hat{y}_{i}^{(0)} &=0 \\ \hat{y}_{i}^{(1)} &=f_{1}\left(x_{i}\right)=\hat{y}_{i}^{(0)}+f_{1}\left(x_{i}\right) \\ \hat{y}_{i}^{(2)} &=f_{1}\left(x_{i}\right)+f_{2}\left(x_{i}\right)=\hat{y}_{i}^{(1)}+f_{2}\left(x_{i}\right) \end{aligned} y^i(0)y^i(1)y^i(2)=0=f1(xi)=y^i(0)+f1(xi)=f1(xi)+f2(xi)=y^i(1)+f2(xi) . . . . . . ...... ...... y ^ i ( t ) = ∑ k = 1 t f k ( x i ) = y ^ i ( t − 1 ) + f t ( x i ) \hat{y}_{i}^{(t)}=\sum_{k=1}^{t} f_{k}\left(x_{i}\right)=\hat{y}_{i}^{(t-1)}+f_{t}\left(x_{i}\right) y^i(t)=k=1∑tfk(xi)=y^i(t−1)+ft(xi)
可以看到,0棵树模型的预测结果为0,一颗树模型的预测结果为第一颗树的表现,在数值上等于上一课的预测结果加上当前树的表现;2棵树模型的预测结果等于第一颗树的表现加上第2棵树的表现,在数值上也等于上一课的预测结果加上当前树的表现;
因此,我们可以得到t棵树模型的预测结果,在数值上等于前面t-1棵树的预测结果,加上第t棵树的表现。那么对于t棵树我们的目标函数为:
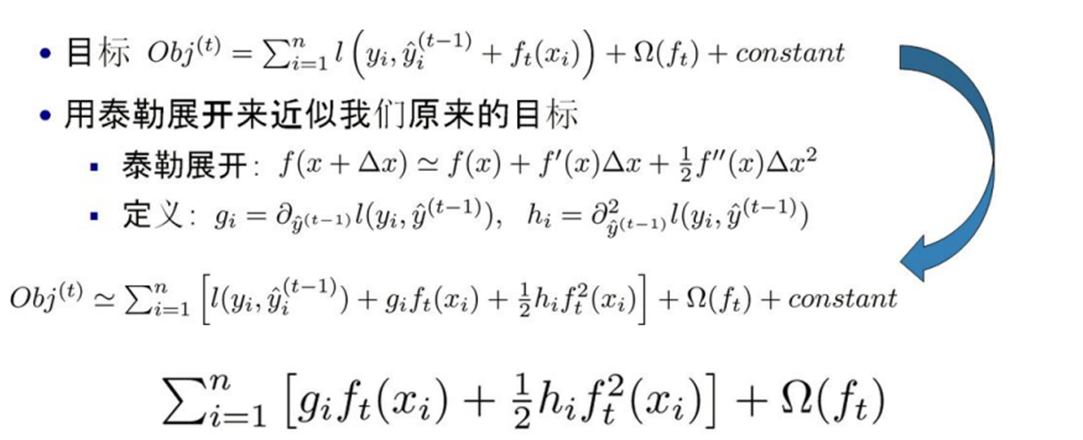
因为,当我们求到t棵树模型时,前面t-1树的结果或是结构肯定是已经是确定了的,所以我们将它视为常数便得到上图的最后一个式子。这里的gi和hi是我们的损失函数关于 y i ^ ( t − 1 ) \widehat {y_i}^{(t-1)} yi (t−1)的一阶、二阶导数,只要损失函数确定,我们的gi,hi就确定了。比如,当我们选取MSE,即均方误差作为损失:
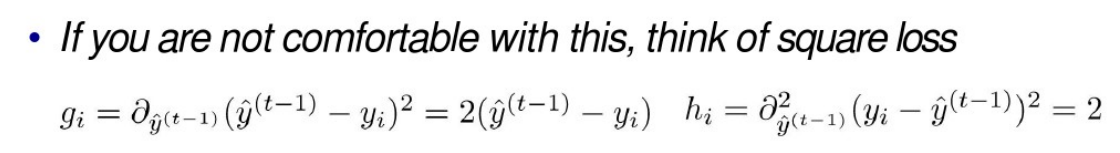
可以看到,这里的梯度值其实就是前面t-1棵树与当前树模型的差值,我们称之为残差。每次我们加的梯度,就是用残差去拟合上几棵树预测的结果,只有这样我们的模型才可能更精确,更接近我们的真实值。
接着,我们对上面的目标函数进行处理:
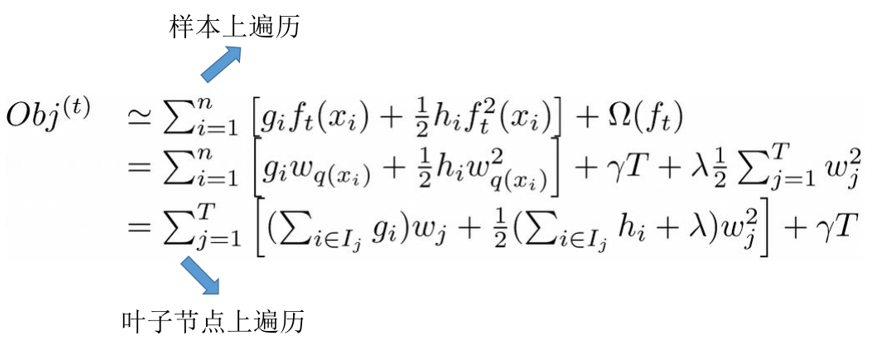
这里我们定义上面的f(x):
f t ( x ) = w q ( x ) , w ∈ R T , q : R d → { 1 , 2 , ⋯ , T } f_{t}(x)=w_{q(x)}, w \in R^{T}, q: R^{d} \rightarrow\{1,2, \cdots, T\} ft(x)=wq(x),w∈RT,q:Rd→{1,2,⋯,T}
其中w表示叶子结点上的分数所组成的向量,即我们的权重向量;q表示一种映射关系,即每个数据样本对应的叶子结点。那么一棵树的结构就可以描述为叶子结点对应权重的组合。同时,我们定义 I j = { i ∣ q ( x i ) = j } I_{j}=\left\{i \mid q\left(x_{i}\right)=j\right\} Ij={i∣q(xi)=j},表示某个样本映射到的结点集合。因为多个样本会落到一个结点,所以这里的n>T。同时,我们也将目标函数的定义范围由n个样本转变为了T个结点。
因为映射到同一叶子结点上的样本的权重都相同,所以我们继续对上图中的式子进行处理:
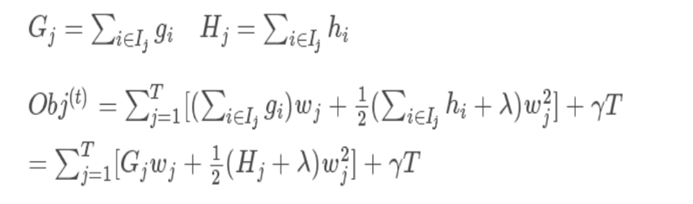
因为 G j G_j Gj, H j H_j Hj都是前t-1棵树已经确定了的,因此对于一棵确定的树,即T已知的情况下,此时我们的目标函数就只和 w j w_j wj相关了,易知:对 w j w_j wj求偏导,偏导数为0时的w值,代入目标函数将取得最小值。(隐含条件是 H j H_j Hj必须为正值)如下图所示:
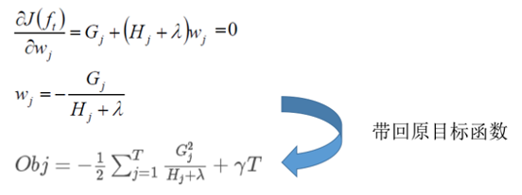
再回到上面,对于一个确定的树结构q(x),我们便能求得目标函数,有了目标函数,我们树模型的评判标准便也就确定了。见下图:

那么,如何确定树的结构呢?这就涉及到分裂点选择的问题了。最原始的猜想就是枚举出所有可能的树结构,即特征值和分裂阀值,然后再根据目标函数计算比较出最优的选择。比如,当我们的结点按如下方式进行划分:(这里做了一个简单的年龄排序)
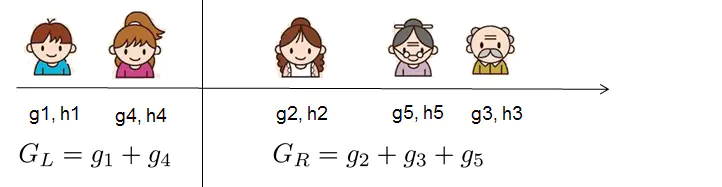
那么使用我们的目标函数对这次划分做出评判,即切分前的obj减去切分后的obj:
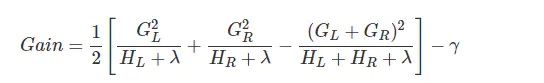
如果增益Gain为正值,说明切分后的obj更小,模型更好。
类似的,其他结点也递归的重复这个过程,直到达到树的最大深度,或是当样本权重和小于设定阈值时停止生长以防止过拟合。这样一颗树的训练过程就完成了。下一棵树的训练过程同样是计算梯度,然后确定树结构。
好,至此,我们的XGBoost算法的树模型训练过程就结束了,这里引用一张图,梳理一下推导过程。
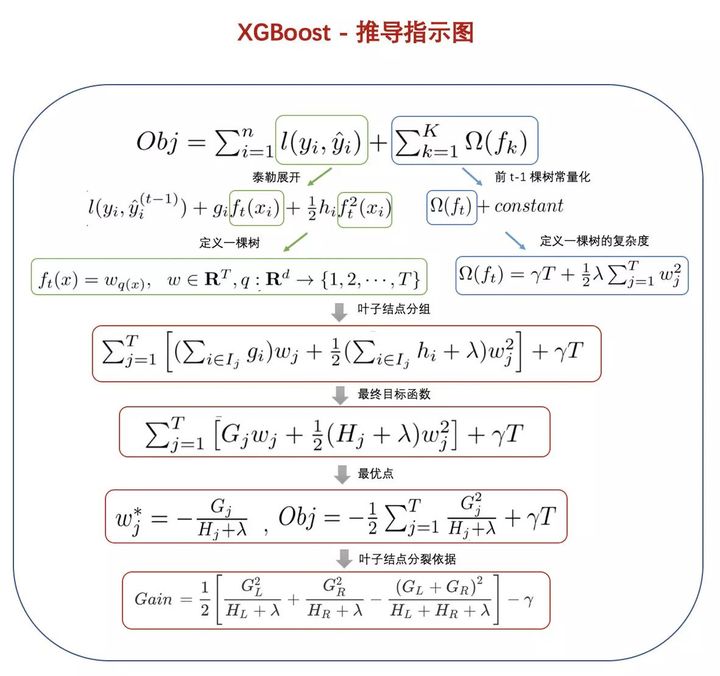
实际上,我们只是理清了XGBoost树模型的训练过程,其他的比如树结构的选取是如何进行的等,XGBoost提供了许多方案以及其他的一些优化算法,还需要仔细研究,期待后续~
参考引文:
https://www.jianshu.com/p/7467e616f227
https://zhuanlan.zhihu.com/p/27816315
XGBoost A Scalable Tree Boosting System
陈天奇论文PPT下载

















 1332
1332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









