







欢迎来到机器学习房地产公司! 你的第一个任务是利用加州普查数据, 建立一个加州房价模
型。 这个数据包含每个街区组的人口、 收入中位数、 房价中位数等指标。
任务:
你的模型要利用这个数据进行学习, 然后根据其它指标, 预测任何街区的的房价中位数。
项目设计:
这是一个监督学习任务,因为我们的数据是有标签的,然后我们要预测一个值,所以是一个回归问题。同时,我们有多个变量,所以这是一个多变量回归问题。
选择性能指标:
回归问题的典型指标是均方根误差(RMSE)。均方根误差测量的是系统预测误差的标准差。例如, RMSE 等于 50000, 意味着, 68% 的系统预测值位于实际值的 50000 美元以内, 95% 的预测值位于实际值的 100000 美元以内。通常一个特征都会符合高斯分布,
即满足 “68-95-99.7”规则: 大约68%的值落在 1σ 内, 95% 的值落在 2σ 内, 99.7%
的值落在 3σ 内, 这里的 σ 等于50000) 。公式如下:
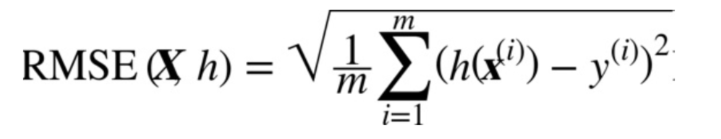
常见机器学习符号:
m 是测量 RMSE 的数据集中的实例数量。
x^(i)是数据集第 i 个实例的所有特征值( 不包含标签) 的向量, y^(i)是它的标签( 这
个实例的输出值) 。
例如:如果数据集中的第一个街区位于经度 –118.29°, 纬度 33.91°, 有 1416 名居
民, 收入中位数是 38372 美元, 房价中位数是 156400 美元( 忽略掉其它的特
征) , 则有:



h 是系统的预测函数, 也称为假设( hypothesis) 。 当系统收到一个实例的特征向
量 , 就会输出这个实例的一个预测值 y^( 读作 y-hat ) 。

这里的h(x(i))是指的预测值,而y(i)是指的真实值。
RMSE(X,h) 是使用假设 h 在样本集上测量的损失函数。
在大多数情况下RMSE(均方根误差)对付回归任务是足够的,但是可能会用到其他函数。平均绝对偏差(MAE)。公式如下:
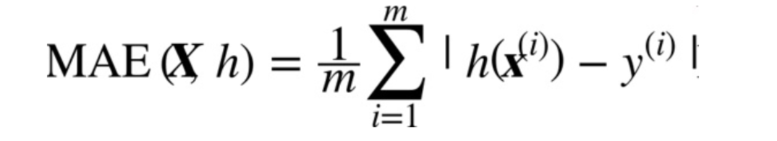
编写程序加载展示数据:
import pandas as pd
import os
##加载房价数据
HOUSING_PATH="E:\jupyter\hand on ML with sl"
def load_housing_data(housing_path=HOUSING_PATH):
csv_path=os.path.join(housing_path,"housing.csv")
return pd.read_csv(csv_path)
##os.path.join 路径拼接
housing=load_housing_data()
housing.head()
打印前5条数据

每一行都表示一个街区。 共有 10 个属性( 截图中可以看到 6 个) : 经度、 维度、 房屋年龄中位数、 总房间数、 总卧室数、 人口数、 家庭数、 收入中位数、 房屋价值中位数、 离大海距离。
##查看数据的具体描述
housing.info()

数据集中共有 20640条数据,但是总房间数只有 20433 个非空值, 207 个街区缺少这个值。
由上图可以看出,除了距离大海距离是对象(文本)类型的,其他都是数值类型的。
housing["ocean_proximity"].value_counts()
###使用values_counts()查看数据的值有哪些,各个值有多少数目。

housing.describe()
###使用describe方法对这些数据进行简单的描述。可以得到各个属性的数目、均值、方差、最大值、最小值、25%的占了多少。

count 、 mean 、 min 和 max 几行的意思很明显了。 注意, 空值被忽略了( 所以, 卧室总数
是 20433 而不是 20640) 。 std 是标准差( 揭示数值的分散度) 。 25%、 50%、 75% 展示了
对应的分位数: 每个分位数指明小于这个值, 且指定分组的百分比。 例如, 25% 的街区的房
屋年龄中位数小于 18, 而 50% 的小于 29, 75% 的小于 37。 这些值通常称为第 25 个百分位
数( 或第一个四分位数) , 中位数, 第 75 个百分位数( 第三个四分位数) 。
对完整数据集调用 hist() 方法,画出每个数值属性的柱状图。
import matplotlib.pyplot as plt
housing.hist(bins=50,figsize=(20,15))
plt.show()
##bins指每张图柱子的个数
##figsize指每张图的尺寸大小

创建测试集
###创建测试集
from sklearn.model_selection import train_test_split
train_set,test_set =train_test_split(housing,test_size=0.2,random_state=42)
#random_state=42设置随机种子
使用sklearn来对数据集进行划分,测试集占20%,设置随机种子。
根据收入分类进行分层采样
数据集中的每个分层都要有足够的实例位于你的数据中,这样可以减少偏差,上面的纯随机的取样方法当数据集较大时往往是可行的,但是当数据集不大时,会有采样偏差的风险。故使用分层采样,使得每一个分层都要有一定量的数据在其中。数据中不能有太多的分层,并且每个分层都要足够大。后面的代码通过将收入中位数除以 1.5( 以限制收入分类的数量) , 创建了一个收入类别属性, 用 ceil 对值舍入( 以产生离散的分类) , 然后将所有大于 5的分类归入到分类 5:使用Scikit-Learn的 StratifiedShuffleSplit 类来进行处理:
import numpy as np
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
###将小于0.5的数据用0.5代替
from sklearn.model_selection import StratifiedShuffleSplit
split=StratifiedShuffleSplit(n_splits=1,test_size=0.2,random_state=42)
for train_index, test_index in split.split(housing,housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
housing["income_cat"].value_counts()/len(housing)

数据可视化
###数据可视化
housing = strat_train_set.copy()
###创建数据副本
###地理数据可视化
housing.plot(kind="scatter",x="longitude",y="latitude")

改变透明度,显示高密度的散点图
##改变透明度,显示高密度的散点图
housing.plot(kind="scatter",x="longitude",y="latitude",alpha=0.1)

现在来看房价 。 每个圈的半径表示街区的人口( 选项 s ) , 颜色代表价格( 选项 c ), 我们用预先定义的名为 jet 的颜色图( 选项 cmap ) , 它的范围是从蓝色( 低价)到红色( 高价) :
import matplotlib.pyplot as plt
housing.plot(kind="scatter",x="longitude",y="latitude",alpha=0.4,s=housing["population"]/100,label="population",c="median_house_value",cmap=plt.get_cmap("jet"),colorbar=True)
plt.legend()

这张图说明房价和位置( 比如, 靠海) 和人口密度联系密切.
查找关联
使用corr()方法计算出每对属性间的标准相关系数(皮尔逊相关系数)
##使用corr()方法计算出每对属性间的标准相关系数(皮尔逊相关系数)
corr_matrix=housing.corr()
###查看每个属性和房价中位数之间的关联度
corr_matrix["median_house_value"].sort_values(ascending=False)

相关系数的范围是-1到1,当接近1时,代表强正相关,反之,强负相关。例如, 当收入中位数增加时, 房价中位数也会增加。 当相关系数接近 -1 时, 意味强负相关; 你可以看到, 纬度和房价中位数有轻微的负相关性( 即, 越往北, 房价越可能降低) 。 最后, 相关系数接近 0, 意味没有线性相关性。
检测属性间相关系数的方法2
使用Pandas的scatter_matrix函数,可以绘制出每个数值属性对其他数值属性的图。
from pandas.tools.plotting import scatter_matrix
attributes=["median_house_value","median_income","total_rooms","housing_median_age"]
scatter_matrix(housing[attributes],figsize=(12,8))
得到各个属性系数相关图如下:

由图可知:最有希望用来预测房价中位数的的属性是收入中位数。将图像放大。
housing.plot(kind="scatter",x="median_income",y="median_house_value",alpha=0.1)

这张图说明了几点。 首先, 相关性非常高; 可以清晰地看到向上的趋势, 并且数据点不是非常分散。 第二, 我们之前看到的最高价, 清晰地呈现为一条位于 500000 美元的水平线。 这张图也呈现了一些不是那么明显的直线: 一条位于 450000 美元的直线, 一条位于 350000 美元的直线, 一条在 280000 美元的线, 和一些更靠下的线。 你可能希望去除对应的街区, 以防止算法重复这些巧合.
属性组合实验
###从数据中提取数据,成为新的属性
housing["rooms_per_household"]=housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"]=housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
###相关矩阵
corr_matrix=housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)

新的 bedrooms_per_room 属性与房价中位数的关联更强。 显然, 卧室数/总房间数的比例越低, 房价就越高。 每户的房间数也比街区的总房间数的更有信息, 很明显, 房屋越大, 房价就越高。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









