






最近在入新坑,本意是想记录下学习过程的一些知识点,属实是没想到越学越多。。。


一、BERT的模型框架
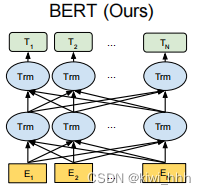
Bert的所做的就是,输入一个句子,基于任务然后吐出来一个基于训练任务的词向量(embedding)。原论文中提到的BERT的模型框架如下,模型框架基于Transformer中的Encoder(因为Bert的任务是生成语言模型,所以只用到Encoder模块,Encoder做的事情其实是读取文本输入),使用了双向的Transformer(Transformer其实就是一个自注意力模型),BERT利用Attention机制(注意力机制)构建Transformer模块,在此基础上,用多层Transformer来组装模型。这里说的双向是从左到右+从右到左一步到位的预训练,原论文中对比了OpenAI GPT和ELMo, OpenAI GPT使用单向(顺序读取,从左到右)预训练模型,而ELMo则是从左到右和从右到左独立训练,通过向量拼接实现双向读取,这种双向读取文本输入允许模型根据单词的所有上下文来学习单词在上下文中的embedding。图中最底层的输入E代表的是embedding,中间层的Trm代表由Transformer堆叠而成(其实是Transformer中的Encoder),最后的T代表Token。
顺便放一些小概念的记录:
- embedding:词嵌入,是一种将文本中的单词或其他文本单位映射到连续向量空间中的表示方法。这种表示方式可以将文本中的单词或其他文本单位转换成实数向量。词嵌入的目标是将文本中的单词表示成一组连续的向量,使得具有相似语义的单词在向量空间中的距离较近,而语义不相似的单词在向量空间中的距离较远。这种连续向量表示可以捕捉到单词之间的语义和语法关系,从而在文本处理任务中能够更好地表示词语之间的相似性和差异性。
- Encoder-Decoder:一种用于生成模型的结构,其中编码器(Encoder)负责将输入数据映射到低维度的编码表示,解码器(Decoder)负责将编码表示映射回原始输入数据。
- encoding:编码,通常指的是将输入数据转换为低维度、紧凑表示的过程。
- Token:指文本中的一个基本单位,通常可以是一个单词、一个词组、一个标点符号、一个字符等,取决于文本处理的需求和方法。token表示为向量,作为词嵌入矩阵。
- OOV:out of the vocabulary
二、BERT的训练过程
BERT的训练过程其实包含两部分:预训练+微调参数。
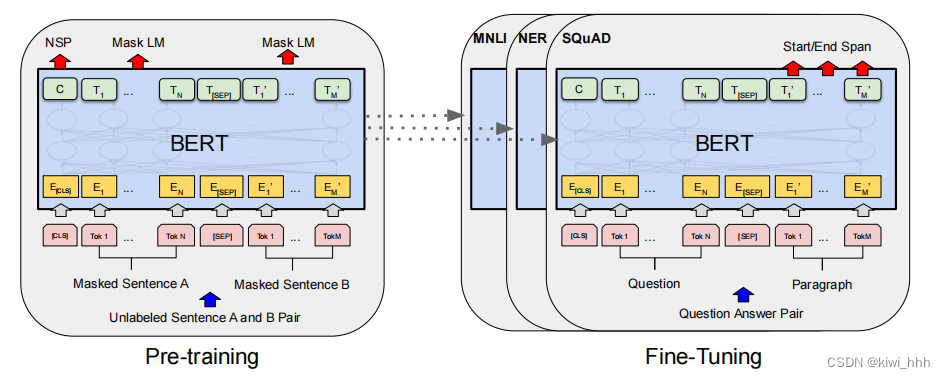
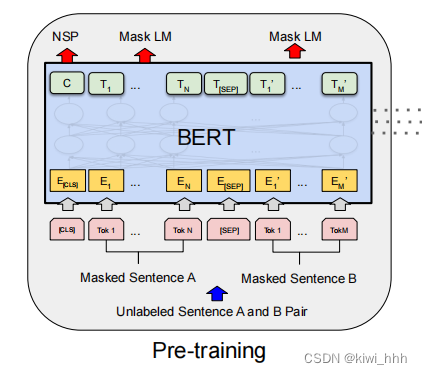
1、预训练
BERT的预训练是无监督的预训练,预训练任务还分为两个子任务:MLM(Masked Language Model)、NSP(Next Sentence Prediction)。在训练BERT的时候,这两个任务是同时训练的,所以BERT的损失函数是把这两个任务的损失函数加起来的。
1.1 Masked Language Model
掩码语言模型(Masked Language Model,MLM)是一种用于自然语言处理的机器学习模型,灵感源于英语的完形填空。它通过训练来填充(mask)或遮盖掉输入文本中的某些词语,然后模型需要根据上下文来预测被遮盖掉的词语是什么,通过这样的训练,MLM能够学习到丰富的语言统计信息和上下文关系。 MLM预测的是被masked 的位置。在MLM中,会随机mask每一个句子中15%的单词,模型会根据上下文来预测被masked的单词,而不是预测整个句子。通过这种方法,可以利用双向语境信息,但问题是mask这15%的单词就不会出现在训练模型中,在后续做fine-tuning的时候,这些单词又很可能会出现,这就导致在fine-tuning时没有该单词的信息,预测结果会产生很大的偏差。为了解决这个问题,作者提出了以下方法,随机遮住15%的Tokens作为训练样本,让模型去预测mask位置原有的词语,这masked了的15%的Tokens又分为三种情况:
(1)80%的字符用"MASK"这个字符替换
(2)10%的字符用另外的字符替换
(3)10%的字符保持不动
举个例子,15%的训练样本中有80%的情况是这样的:My dog is cute. → My dog is [MASK].有10%的情况是这样的:My dog is cute. → My dog is white.剩下10%则是原封不动:My dog is cute. → My dog is cute.
关于随机选取10%的其他单词来替代有一个好处,编码器不知道哪些词需要预测的,哪些词是错误的,因此被迫需要学习每一个token的表示向量,并且赋予了模型一定的纠错能力,由此保证了模型对每个token分布式的表征,否则模型就会记住被mask处的单词是原始单词,这样会导致过拟合。也可以理解为相当于给训练模型添加了一定的“噪声”,而随机替换的单词只占到全体的1.5%,比例很小,不会损害模型的语言理解能力。而在训练过程中,loss只会计算mask的单词,其他未mask处的loss直接为0。
训练技巧:序列长度大大(512) 会影响训练速度,所以90%的steps都用seq_len=128训练,余下的10%步数训练512长度的输入。
具体实现注意:
i) 在encoder的输出上添加一个分类层。
ii) 用嵌入矩阵乘以输出向量,将其转换为词汇的维度。
iii)用softmax计算词汇表中每个单词的概率
BERT的损失函数只考虑了mask的预测值,忽略了没有掩蔽的字的预测。这样的话,模型要比单向模型收敛得慢,不过结果的情境意识增加了。
1.2 Next Sentence Prediction
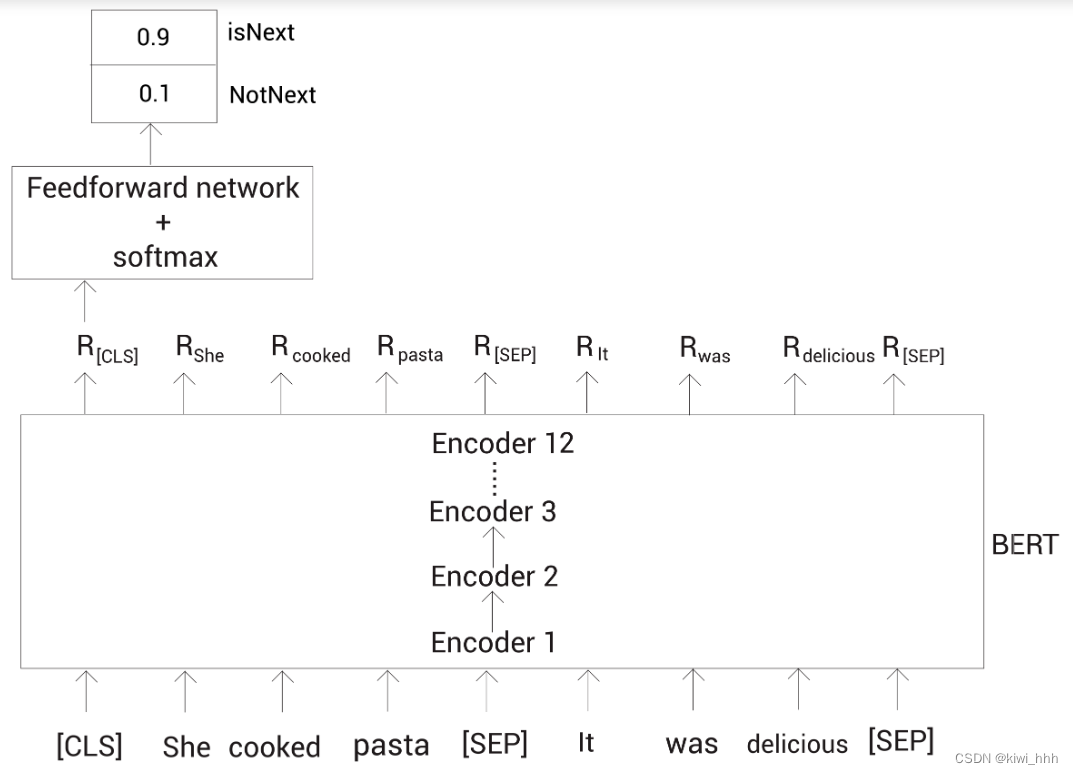
Next Sentence Prediction(NSP)在预训练阶段的任务是用于预测两个句子是否是连接在一起的,就是预测某个句子是不是指定句子的下一个句子。许多重要的下游任务,如问答(QA)和自然语言推理(NLI),都是基于对两个句子之间关系的理解,此时的模型输入为一对句子。具体来说,在训练期间,50% 的输入是一对连续句子标记为IsNext),而另外 50% 的输入是从语料库中随机选择的不连续句子(标记为NotNext)。这种做法也相当于给数据添加一部分噪声,以防止数据记住标签。
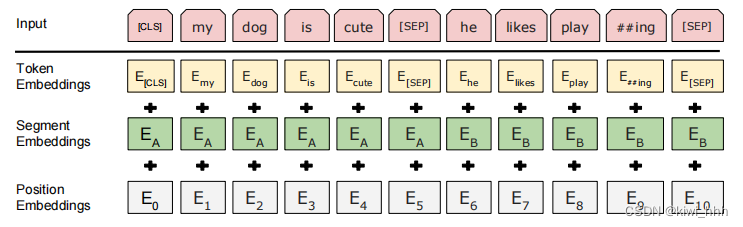
为了帮助模型区分训练中的两个句子是否是顺序的,在第一个句子的开头插入 [CLS] 标记,在每个句子的末尾插入 [SEP] 标记。两个句子对应的词语对应的embedding还要加上位置embedding和标明token属于哪个句子的embedding。原论文中举了两个句子:My dog is cute. He likes playing.
首先对这两个句子分词,得到分词后的tokens然后连到一起:
tokens = [my,dog,is,cute,he,likes,play,# #ing]
接下来增加一个新的标记到第一个句子前面,叫作[CLS]标记:
tokens = [ [CLS] my,dog,is,cute,he,likes,play,# #ing]
然后增加一个新的标记到每个句子的结尾,叫作[SEP]标记:
tokens = [ [CLS] my,dog,is,cute, [SEP] he,likes,play,# #ing [SEP] ]
[CLS] 标记只加在第一个句子前面,而[SEP] 标记加到每个句子末尾。
CLS,classification,这个单词的意思就是告诉Bert,这里是要做一个分类任务,是一个够代表整个文本的的语义特征向量,取出来就可以直接用于分类了。SEP,separator,这个单词的意思就是告诉Bert,左右的两个句子是分开的,因为 NLP 中有的任务是单句输入,有的是多句输入,所以 BERT 为了处理各种任务,设置了 SEP 进行分割,用一套框架就能处理所有任务。
前期工作做好之后,在把数据喂给BERT之前,使用一个叫作标记嵌入的嵌入层转换这些标记为嵌入向量,通过下面三个Embedding层将输入转换为Embedding向量,这些Embedding向量的值会在训练过程中学习得到。BERT的Embedding 由Token,Segment,和Position三部分构成,因为他们要相加,所以单个向量的维度必须是相等的,这样才能相加。
- Token embeddings:词的向量表示。Token中包括CLS和SEP,将各个词转换成固定维度的向量,在BERT中,每个词会被转换成768维的向量表示,“[CLS] my dogis cute [SEP] he likes play ##ing [SEP]”被转换成了一个(11, 768)维的向量。
- Segment embeddings:判断两个文本是否是语义相似的,用来区分每个token属于前一段话还是后一段话,是一个可学习的嵌入向量,与SEP一起,用来区分不同句子。Segment Embeddings 层只有两种向量表示。如果输入是两个句子,前一个向量是把0赋给第一个句子中的各个token, 后一个向量是把1赋给第二个句子中的各个token。“[CLS] my dog is cute [SEP] he likes play ##ing [SEP]”就表示成为“0 0 0 0 0 0 1 1 1 1 1”,也是一个(11, 768)维的向量;如果输入仅仅只有一个句子,那么它的segment embedding就是全0。
- Position embeddings:辅助BERT区别句子对中的两个句子的向量表示。通过训练得到,举例:加入position embeddings会让BERT理解“I think, therefor I am”中的第一个“I” 和第二个 “I”应该有着不同的向量表示。
以上就是BERT编码层的输入了。为了预测第二个句子是否确实是第一个句子的后续句子,执行以下步骤:(多层感知机(MLP,Multilayer Perceptron):多层感知机最底层是输入层,中间是隐藏层,最后是输出层。除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,多层感知机层与层之间是全连接的。 具体:https://blog.csdn.net/fg13821267836/article/details/93405572)
-
整个输入序列的embedding被送入Transformer 模型
-
[CLS]对应的输出经过简单MLP分类层变成2*1向量([isNext,IsnotNext])形式
-
用softmax计算IsNext的概率
为了进行分类,将[CLS]标记的embeding表示喂给一个带有softmax函数的全连接网络,该网络会返回输入的句子对属于isNext和notNext的概率。如下图:
1.3 数据集
原论文中作者在预训练阶段采用Toronto BookCorpus数据集和English Wikipedia(英语维基百科),从语料库中采样两个句子(或文本片段)。
2、微调参数
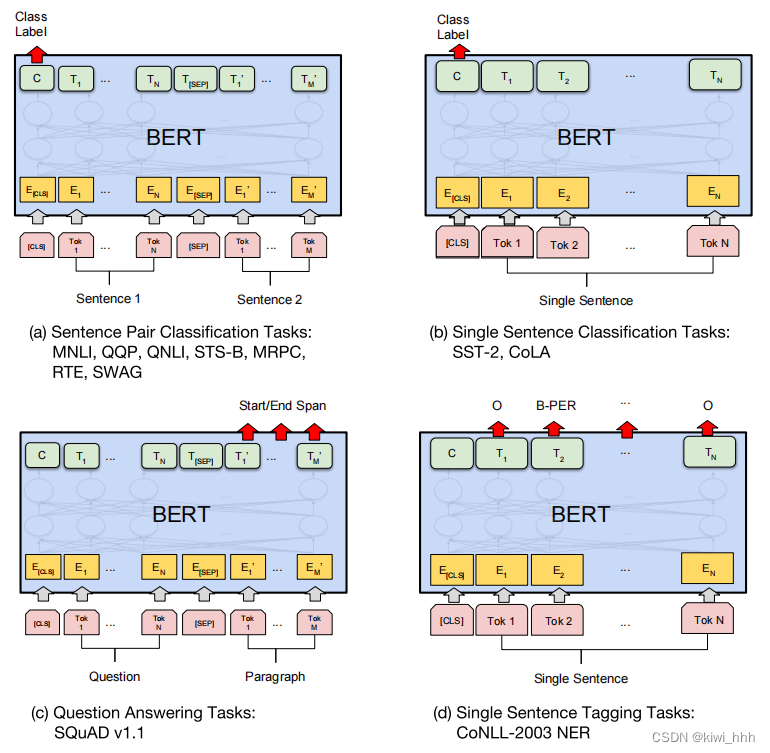
BERT的fine-tuning,是根据任务在预训练模型上再加一层简单的网络层,取相应的token作为输入进入新加的网络层中。对于所有任务,BERT 都是端对端地微调全部参数,对于不同的下游任务,仅需要对BERT不同位置的输出进行处理。对于句子对任务 (句子关系判断任务),需要用[SEP]分隔两个句子输入到模型中,然后将[CLS]的输出送到分类器进行分类;对于情感分析等单句分类任务,可以直接输入单个句子,再将[CLS]的输出直接输入到分类器进行分类;对于问答任务,将问题与答案拼接输入到BERT模型中,然后将答案位置的输出向量进行二分类并在句子方向上进行softmax (只需预测开始和结束位置即可);对于命名实体识别任务,对每个位置的输出进行分类即可。
三、一些其他补充
1、优化器
BERT采用AdamW优化器,是在Adam+L2正则化的基础上进行改进的算法。Adam是一种自适应优化算法,可以根据历史梯度信息来调整学习率。结合了RMSProp和Momentum两种优化算法的思想,并且对参数的更新进行了归一化处理,使得每个参数的更新都有一个相似的量级,从而提高训练效果。AdamW选择将L2正则项加在了Adam的m、v等参数被计算完之后、在与学习率lr相乘之前。
2、激活函数
深度神经网络要加入激活函数来具备非线性拟合的能力,ReLU就是一个较好的激活函数。而同时为了避免其过拟合,又需要通过加入正则化来提高其泛化能力,Dropout就是一种主流的正则化方式,而zoneout是Dropout的一个变种。BERT使用的激活函数叫作GELU(Gaussian Error Linear Unit),激活函数用GELU代替RELU,GELU通过来自上面三者的灵感,希望在激活中加入正则化的思想。
3、分词方法
BERT的分词过程:
- 读取文本中的一行,将文本转化成unicode编码(假设输入是utf-8)并去掉开头和结尾的空格。
- 使用basic_tokenizer,根据空格等进行分词,包括unicode变化,移除’\t’制表符和空白字符,对中文字符按字分开。在原版的BERT中,要将大写转为小写。
- 使用WordpieceTokenizer。用最长匹配优先算法,根据词表进行分词。
4、优缺点
优点:微调下游任务的时候即使数据集非常小(比如小于5000个标注样本),模型性能也有不错的提升。
缺点:BERT收敛速度较慢;由于有最大输入长度的限制(每个句子最多512个token),适合句子和段落级别的任务,不适用于文档级别的任务(如长文本分)。BERT使用的是训练式的固定位置编码,预训练时token序列最长就是512(训练出来的位置向量就512个),多的会被截断。遇到更长句子,BERT会从长文本中截取一部分,具体截取哪些片段需要观察数据,如新闻数据一般第一段比较重要就可以截取前边部分;或者抽取长文本的关键句子作为摘要,然后进入BERT。
------------------------------------------------------分割线------------------------------------------------------------------
先到这里吧,暂时写不动了,后续会再补充上去了。有问题欢迎指正。
参考:
- https://blog.csdn.net/lichji2016/article/details/119617876
- https://blog.csdn.net/wzk4869/article/details/130301647
- https://zhuanlan.zhihu.com/p/558393190?utm_id=0
- https://zhuanlan.zhihu.com/p/398310661?utm_id=0
- http://www.taodudu.cc/news/show-1705502.html?action=onClick
- https://blog.csdn.net/fkyyly/article/details/121912934
- https://blog.csdn.net/qq_35707773/article/details/127699755
- https://www.jianshu.com/p/e17622b7ffee
- https://zhuanlan.zhihu.com/p/349492378















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









