









 提出一种基于图和异质性感知的推特机器人检测框架,构建异构信息网络并利用关系图transformers和语义注意力网络进行表示学习。
提出一种基于图和异质性感知的推特机器人检测框架,构建异构信息网络并利用关系图transformers和语义注意力网络进行表示学习。
论文链接:https://shimo.im/files/m8AZV1nNVVCbaWAb/ 「20314-Article Text-24327-1-2-20220628.pdf」,可复制链接后用石墨文档 App 或小程序打开
目录
2.2 Heterogeneous Information Networks
3.2 Relational Graph Transformers
3.3 Semantic Attention Networks
4.8 Representation Learning Study
1 绪论
Twitter机器人是由自动程序或Twitter API控制的Twitter账户。机器人运营商经常发起机器人运动,以追求恶意的目标,这损害了在线话语的完整性。在过去的十年中,推特机器人积极参与了选举干扰(Deb等人,2019年;Ferrara,2017年),传播错误信息(Cresci,2020年)和宣传极端意识形态(Berger和Morgan,2015年)。由于恶意的Twitter机器人对在线社区构成了威胁,并诱发了不良的社会效应,因此迫切需要有效的Twitter机器人检测措施。
早期的Twitter机器人检测工作通常依赖于特征工程,其中提出并评估了大量的用户特征。从推文(Cresci等人,2016)和用户元数据(Yang等人,2020;Lee和Kim,2013;Miller等人,2014)中提取的特征与传统分类器相结合,用于机器人检测。随着深度学习的出现,基于神经网络的Twitter机器人检测器越来越普遍。采用循环神经网络对推文进行编码并根据其语义内容检测机器人(Kudugunta 和 Ferrara 2018;Wei 和 Nguyen 2019)。自监督学习技术被引入以对抗机器人的改进(Feng等人,2021b)。图形神经网络(Ali Alhosseini等人,2019年;Feng等人,2021年d)后来被用来利用Twitter领域的图形结构,而最先进的方法是以某种方式感知拓扑结构的。
尽管早期在利用Twittersphere的拓扑结构方面取得了成功,但这些方法未能认识到Twitter内在的异质性,并利用它来识别真正的用户和新的Twitter机器人之间的微妙差别。图1说明了现实世界中Twitter领域普遍存在的两个层次的异质性:
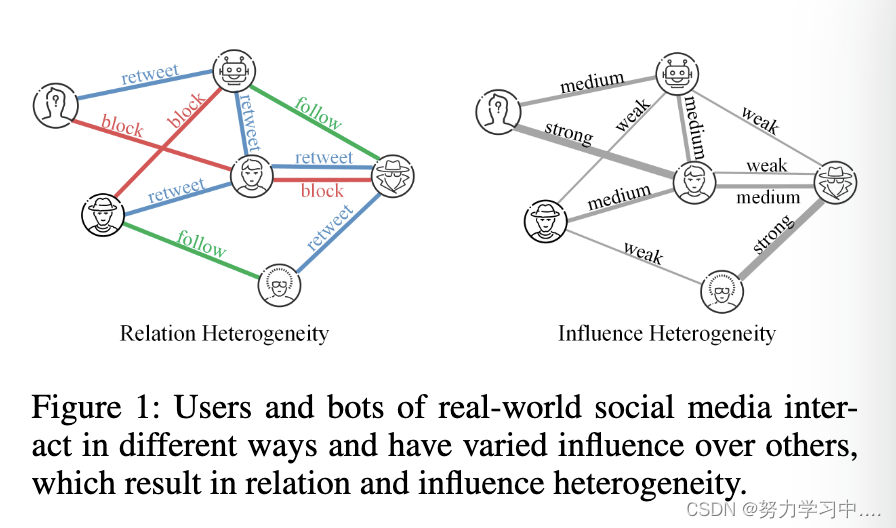
关系的异质性。推特用户是以不同类型的关系连接的。例如,一个用户可能会喜欢、评论、转发或阻止另一个用户,而这些活动表明他们之间有不同的关系。
影响的异质性。推特上的用户对他们的邻居有不同的影响范围和强度。例如,著名的新闻机构可能会对许多人的思想产生巨大的影响,而普通用户一般会将他们最近的活动告知周围的人。
在本文中,我们提出了一个新的Twitter机器人检测框架,该框架利用了现实世界Twittersphere的拓扑结构,并在此基础上建立了关系和影响的渗透性异质性模型,以提高任务绩效。具体来说,我们构建了以用户为节点、以多样化关系为边的异构信息网络。
然后,我们提出了关系图transformers,用注意力机制建立影响强度模型,并学习节点表征。最后,我们采用语义注意力网络来聚合用户和关系中的信息,并进行机器人检测。我们的主要贡献总结如下:
(1)我们建议利用现实世界 Twittersphere 的关系和影响异质性,这使我们的机器人检测模型能够识别真正用户和机器人之间的细微差异,并进行强大的机器人检测;
(2)我们提出了一个新颖的Twitter机器人检测框架,它是基于图形和异质性感知的。它是一个端到端的机器人检测器,采用关系图transformers来利用现实世界中Twitter的拓扑结构和异质性;
(3)我们进行了广泛的实验,在一个全面的机器人检测基准上评估我们的模型和最先进的方法。结果表明,我们的建议一直优于所有的基准方法。更多的实验也证明了我们基于图和异质性感知的方法的有效性。
2 相关工作
2.1 Twitter Bot Detection
早期的Twitter机器人检测模型专注于手动设计的特征,并将其与传统的分类器相结合。这些特征从推文(Cresci等人,2016)、用户元数据(Yang等人,2020;Lee和Kim,2013)或两者(Miller等人,2014)提取。随着深度学习后来显示出巨大的前景并得到普及,越来越多的基于神经网络的机器人检测器被提出。全连接网络(Kudugunta 和 Ferrara 2018)、循环神经网络(Wei 和 Nguyen 2019)和生成对抗网络(Stanton 和 Irissappane 2019)在有效的机器人检测模型中被采用,以利用用户信息的不同方面。
SATAR(Feng等人,2021b),一个最近提出的框架,联合利用多模式的用户信息和不同的深度架构来改进这些方法。尽管SATAR(Feng等人,2021b)提议利用Twittersphere的图结构进行机器人检测,但它是以特征工程的方式进行的,而不是采用最先进的图神经网络架构。基于图的机器人检测器被提出来以填补空白。(Ali Alhosseini等人(2019)将Twitter视为用户网络,并采用图卷积网络进行机器人检测。(Feng等人,2021d)进一步构建了一个异质信息网络来代表Twitter,并使用关系型GNN进行机器人检测,这达到了最先进的性能。然而,这些基于图的方法未能纳入现实世界中Twitter领域的内在异质性关系和影响。在本文中,我们在这些工作的基础上,提出了一个异质性感知的机器人检测器,它动态地纳入并利用了用户之间的异质关系和影响模式。
2.2 Heterogeneous Information Networks
现实世界的网络数据往往由大量的多样化和互动的实体组成,这些实体可以被称为异质信息网络(HINs)。HINs被广泛用于社会网络建模(Wasserman和Faust 1994;Otte和Rousseau 2002;Nguyen等人2020)、链接和图形挖掘(Getoor和Diehl 2005;Cook和Holder 2000)和自然语言处理系统(De Cao, Aziz, and Titov 2018;Feng等人2021a)。为了有效地分析HIN,(Schlichtkrull等人2018)提出了关系图卷积网络,将GCN(Kipf and Welling 2016)扩展到异质图。(Wang等人2019)提出了异质图注意网络,将GAT扩展到异质图。我们基于这些工作提出关系图transformers并利用Twitter的异质性网络。
3 方法
图2展示了我们提出的基于图形和异质性感知的Twitter机器人检测器的概况。具体来说,我们首先构建了一个具有多样化关系的异质信息网络来代表Twitter领域。然后,我们用我们提出的关系图transformers学习每个关系下的节点表示。之后,我们从图形的全局出发,用语义关注网络动态地聚合各关系的代表。最后,我们将Twitter用户分为机器人和真实用户,并学习模型参数。
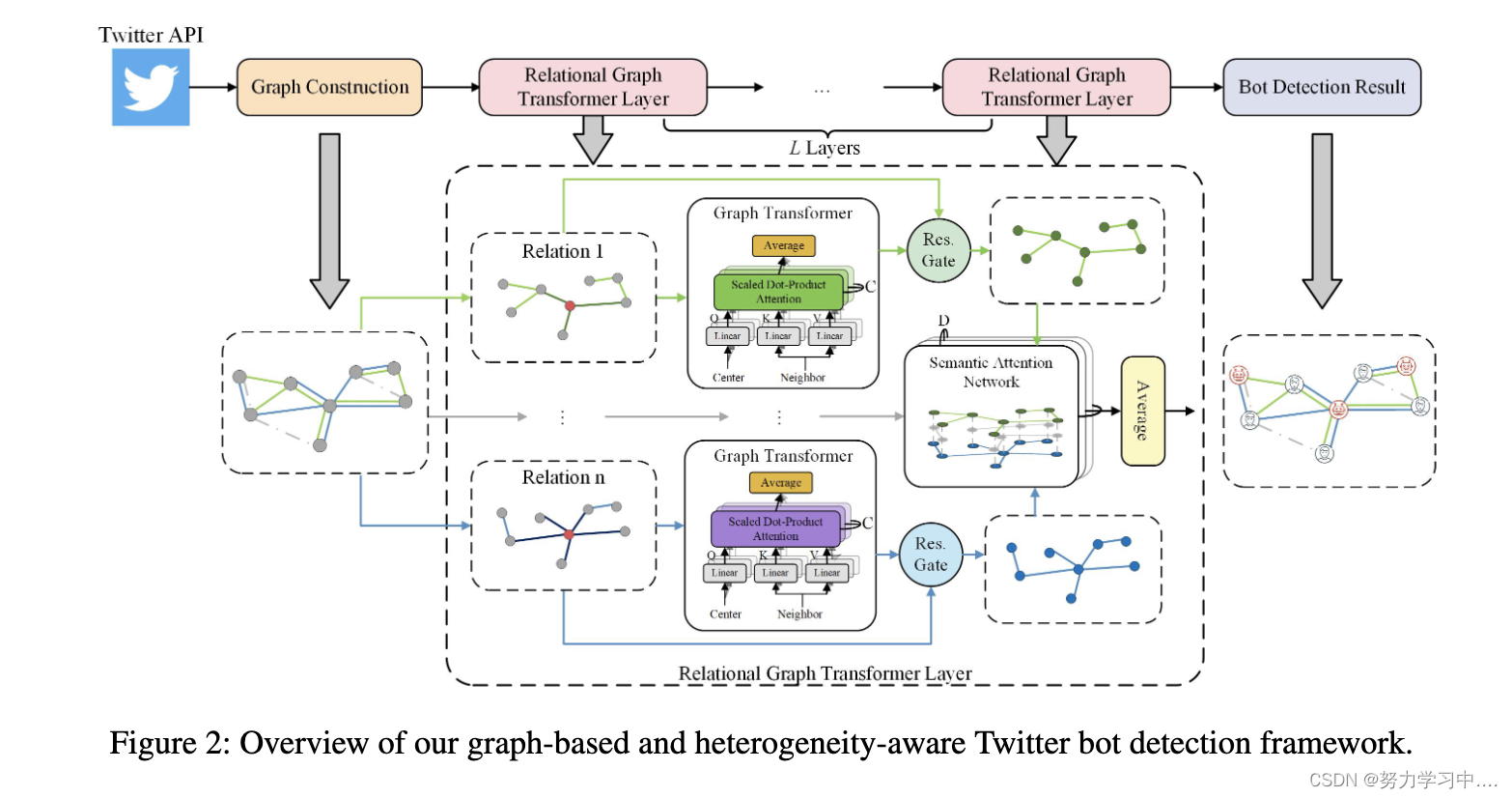
3.1 Graph Construction
我们构建了一个异质信息网络(HIN)来代表Twittersphere,它考虑到了关系的异质性,并利用了用户之间多样化的互动。具体来说,我们把Twitter用户作为图中的节点,用不同类型的边连接他们,代表Twitter上的多样化关系。我们把HIN中的关系集记为R,而我们的框架支持任何关系设置。
由于本文的重点是利用关系和影响的异质性来改善机器人检测,为了公平起见,我们采用了最先进的方法(Feng等人,2021d)中相同的用户信息编码程序。我们将用户i的特征向量表示为,并用全连接层对其进行转换,作为GNN的初始特征:
![]()
其中和
是可学习的参数,σ表示非线性激活函数,我们用leaky-relu作为σ,不再赘述。
3.2 Relational Graph Transformers
受Transformers(Vaswani等人,2017)及其在自然语言处理中的成功经验的启发,我们提出了关系图Transformers,一个包含Transformers并在HIN上操作的GNN架构。我们首先获得关于关系r和节点i的第c个注意头的查询、键和值,表述为
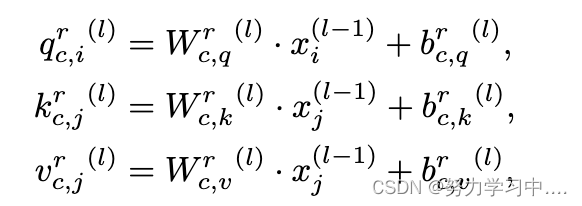
其中,q、k和v是查询、钥匙和注意力机制的值,(l)表示GNN的第l层,所有W和b是关于不同关系和注意力头的可学习参数。
然后,我们通过计算不同节点之间的注意权重来模拟影响的异质性,具体方法是
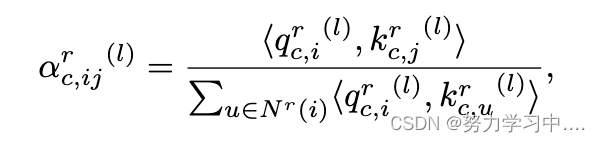
其中,表示节点i和j之间的注意权重,
是指数规模的点乘函数,其中d是每个注意头的隐藏大小,
表示节点i关于关系r的邻域。然后我们聚合节点邻域和注意力头以获得关系 r 下的节点表示,即
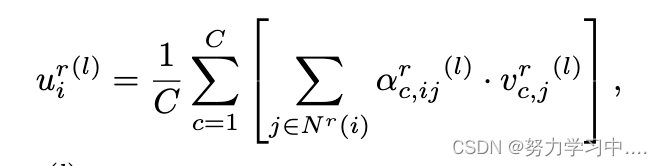
其中是第l层中节点i对关系r的隐藏表示,C是注意头的数量。
然后,我们将门机制应用于所获得的结果,以确保顺利的表示学习。我们首先得到门级,如下所示
![]()
其中 [·,·] 是连接操作,和
是可学习的参数。
然后,我们将门机制应用于学习到的表征和输入
,即
![]()
其中,⊙表示Hadamard乘积运算,是第l层中节点i对关系r的学习表示。
3.3 Semantic Attention Networks
在对HIN进行分析的同时,将不同的关系分开,我们使用语义关注网络来汇总各关系的节点代表,同时保留Twitter HIN中所包含的关系的异质性。首先,我们通过对HIN中所有节点的全局观察,即获得每个关系的重要性。
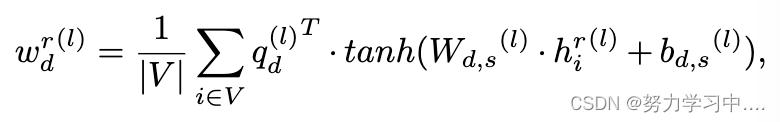
其中表示关系r在第d个注意头的权重,V表示HIN中的节点集合,
是l层中第d个注意头的语义注意向量,
、
和
是语义注意网络的可学参数。我们用softmax对每个关系的重要性进行归一化,公式为
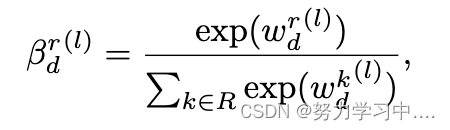
其中表示关系r的权重。 然后我们用这些权重融合不同关系下的节点表示,如下所示
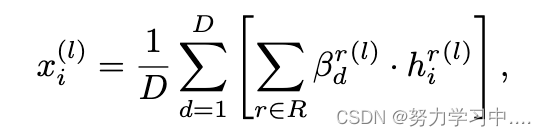
其中表示第l层的输出,
表示关系图transformers的结果,D是语义注意力网络中注意头的数量。
3.4 Learning and Optimization
在我们的模型中,每一层GNN都包含一个关系图transformers和一个语义注意网络。在GNN的L层之后,我们得到最终的节点表示x(L)。我们用一个输出层和一个softmax层对它们进行转换,用于Twitter机器人检测,即
![]()
其中是我们的模型对用户i的预测,所有W和b都是可学习的参数。然后,我们用监督下的标签和正则化项来训练我们的机器人检测器,正则化项表述为
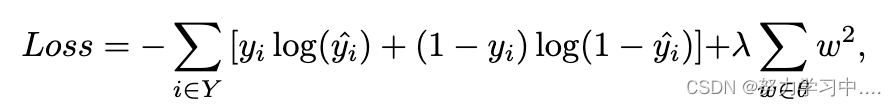
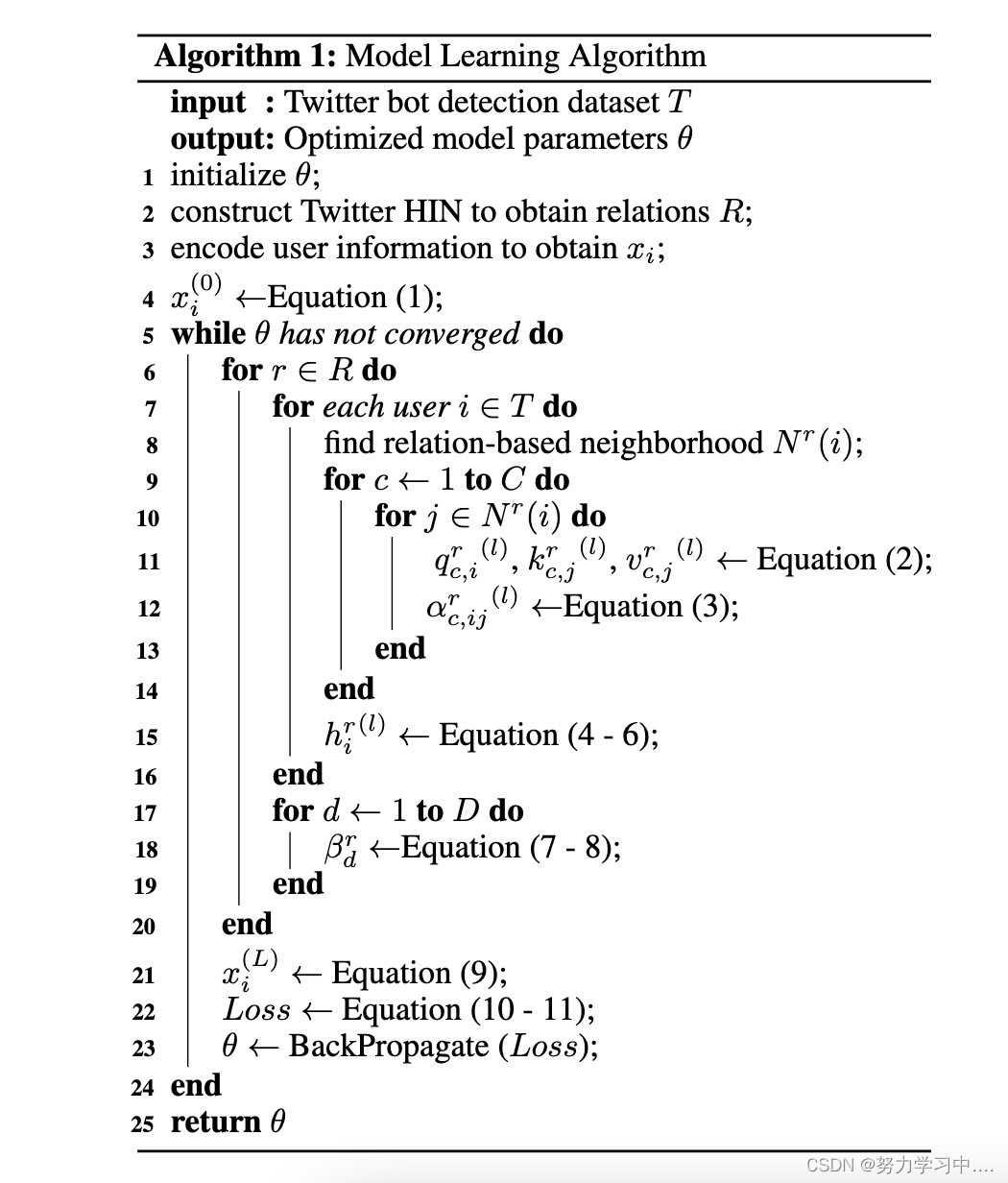
其中,Y是标注的用户集,是groundtruth标签,θ表示模型中所有可训练的参数,λ是一个超参数。综上所述,算法1展示了我们提出的基于图和异质性感知的机器人检测框架的整体训练模式,每层的时间复杂度为O(|E|),其中E表示边缘集,假设嵌入维度和关系数为常数。
4 实验
4.1 Dataset
我们的机器人检测模型是基于图和异质性的,它需要提供某种类型图结构的数据集。 TwiBot-20 (Feng et al. 2021c) 是一个全面的 Twitter 机器人检测基准,也是唯一公开可用的机器人检测数据集,可提供用户关注关系以支持基于图的方法。在本文中,我们使用了 TwiBot-20,其中包括 229,573 个 Twitter 用户、33,488,192 个推文、8,723,736 个用户属性项和 455,958 个关注关系。我们遵循基准中提供的相同拆分,以便结果可以直接与以前的工作进行比较。
4.2 Baselines
我们将我们基于图形和异质性的应用与以下方法进行比较。
Lee等人(Lee, Eoff, and Caverlee 2011)从Twitter用户中提取特征,如账户的寿命,并与随机森林分类器相结合。
Yang等人(Yang et al. 2020)使用随机森林分类器,使用最小的用户元数据和衍生特征。
Cresci等人(Cresci et al. 2016)用字符串对用户活动序列进行编码,并确定最长的共同子字符串,以识别机器人群体。
Kudugunta等人(Kudugunta and Ferrara 2018)提出要联合利用用户推文语义和用户元数据。
Wei等人(Wei and Nguyen 2019)使用递归神经网络对推文进行编码,并根据用户的推文进行分类。
米勒等人(Miller et al. 2014)从用户推文和元数据中提取了107个特征,并将机器人检测的任务框定为异常检测。
Botometer(Davis等人,2016)是一个机器人检测服务,利用了1000多个用户特征。
SATAR(Feng等人,2021b)是一个自我监督的Twitter用户代表学习框架,它共同利用了用户的推文、元数据和邻里信息。SATAR通过对特定的机器人检测数据集进行微调来进行机器人检测。
Alhosseini等人(Ali Alhosseini et al. 2019)使用图卷积网络来学习用户表征并进行机器人检测。
BotRGCN(Feng等人,2021d)构建了一个异质图来代表Twittersphere,并采用关系图卷积网络进行代表学习和机器人检测。BotRGCN在全面的TwiBot-20基准测试中取得了最先进的性能。
4.3 Implementation
我们使用pytorch(Paszke等人,2019)、pytorch lightning(Falcon,2019)、torch geometric(Fey和Lenssen,2019)和transformers库(Wolf等人,2020)来有效实现我们提出的Twitter机器人检测框架。
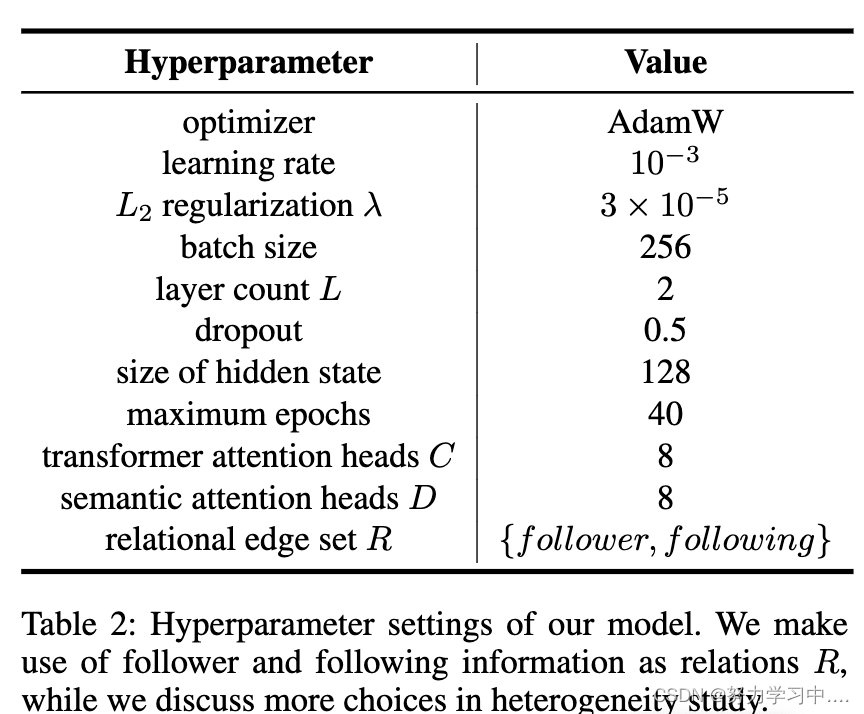
我们在表2中介绍了我们的超参数设置,以方便复制。我们的实现是在拥有12GB内存的Titan X GPU上训练的。我们的实现在GitHub上是公开的。https://github.com/BunsenFeng/BotHeterogeneity https://github.com/BunsenFeng/BotHeterogeneity
https://github.com/BunsenFeng/BotHeterogeneity
4.4 Experiment Results
我们首先评估这些方法是否涉及深度学习、利用用户互动、学习用户表示、涉及图和图神经网络或利用Twitter异质性。然后,我们在TwiBot-20(Feng等人,2021c)上对这些机器人检测模型进行了基准测试,并在表1中列出结果。结果表明

我们的建议始终优于所有基线,包括最先进的BotRGCN(Feng等人,2021d)。
成功的使用基于图的方法,如BotRGCN(Feng等人,2021d)和我们的方法,一般都比不把Twitter圈视为图和网络的传统方法要好。这些结果证明了对Twitter的拓扑结构进行建模对于机器人检测的重要性。
我们提出了第一个异质性感知的机器人检测框架,该框架在一个综合基准上取得了最佳性能。这些结果证明了利用Twitter异质性的必要性和我们提出的方法的有效性。
在下文中,我们首先研究图和异质性在我们提出的方法中的作用。然后,我们研究了我们的机器人检测方法的数据效率和表示学习能力。
4.5 Graph Learning Study
我们提出了一个基于图形的机器人检测模型,它利用Twitter的拓扑结构来捕捉微妙的模式,并更好地识别机器人。具体来说,我们将用户的追随者和关注者关系作为两种类型的边,将用户作为节点连接起来,形成一个HIN。
为了证明我们提出的图构建的有效性,我们删除了不同类型的边,并在图3中报告了这些消减设置下的重新结果。图中显示,完整的图结构,包括追随者和被追随者的边,优于任何减少的设置。这些结果证明了我们构建的HIN对Twitter上关系异质性建模的有效性。
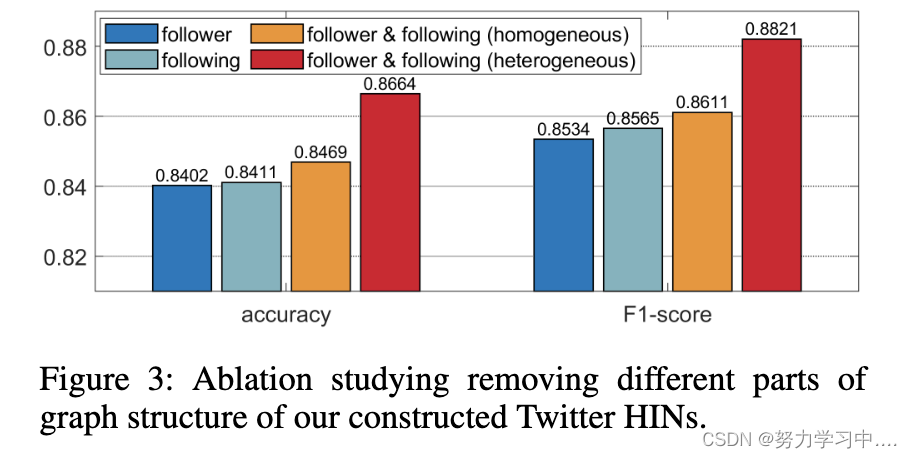
消融研究删除我们构建的Twitter HINs的不同部分的图结构。
在获得HIN后,我们提出了关系图transformers来传播节点信息和学习代表。为了证明我们提出的GNN架构的有效性,我们对关系图transformers进行了消融研究,并在表3中报告了不同设置下的结果。结果表明,转换器、门机制和语义注意网络都是我们提出的GNN结构的重要组成部分。
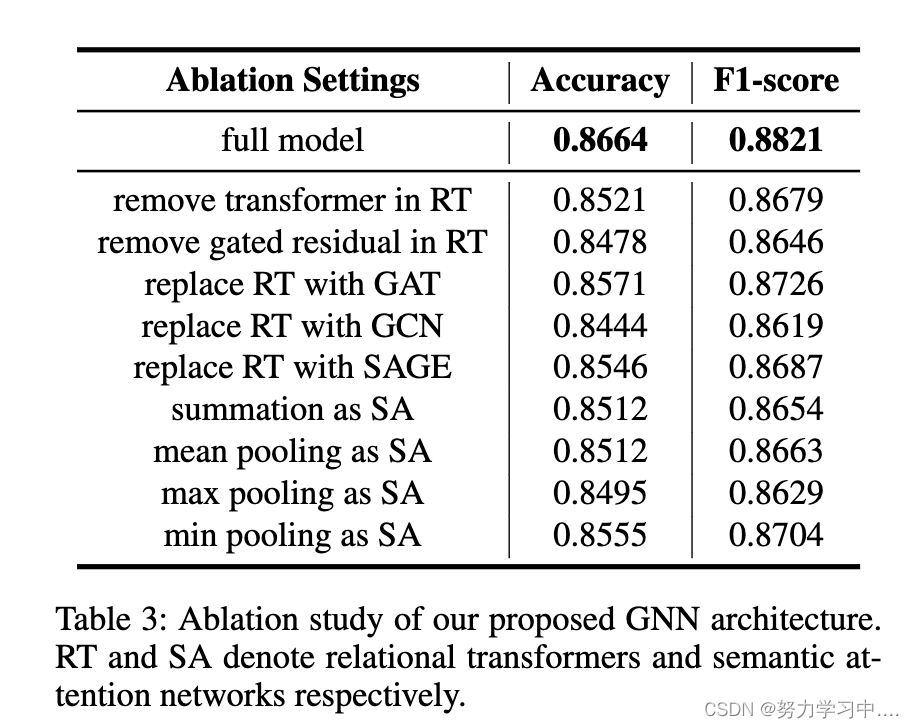
总而言之,我们构建的HIN和我们提出的GNN架构都为我们的模型提供了出色的性能,这证明了我们基于图的方法的有效性。
4.6 Heterogeneity Study
我们的机器人检测建议对Twitter的内在异质性进行建模,以识别机器人的微妙异常,并对机器人进行强有力的检测。我们研究了内在异质性的影响并提出了我们的发现。
关系异质性:关系异质性是指在现实世界的Twitter空间中,用户之间存在多样化的关系。我们的机器人检测模型通过构建HINs并利用它们与关系型GNNs来实现关系异质性。不同的HINs可以用不同的关系集R来构建,因此我们提出了不同的关系异质性设置,并在图4中展示了其结果。图中显示,大多数异质性关系设置都优于其同质性设置,这证明了为Twitter机器人检测建立关系异质性模型的必要性。
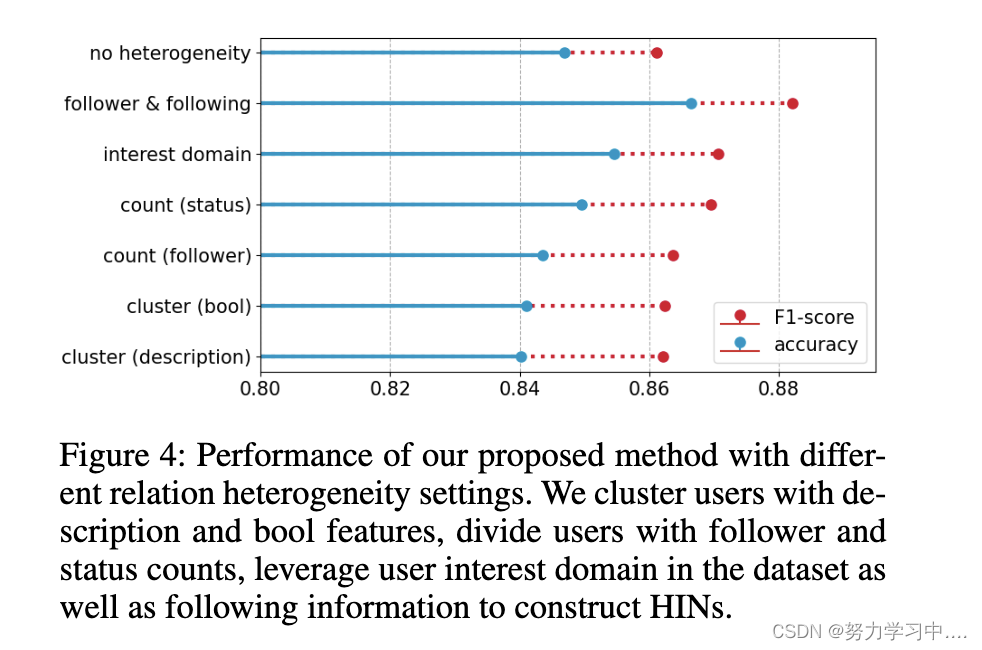
(我们提出的方法在不同关系异质性设置下的表现。我们用描述和bool特征对用户进行聚类,用关注者和状态计数对用户进行划分,利用数据集中的用户兴趣域以及以下信息来构建HINs)
为了识别在 Twitter 机器人检测中至关重要的关系类型,我们将所有关系组合成一个综合图,并使用语义注意力网络中的权重来识别重要关系。图5表明大多数异质关系对我们方法的性能有同样的贡献,而数据集中的用户兴趣领域信息则没有那么有效。
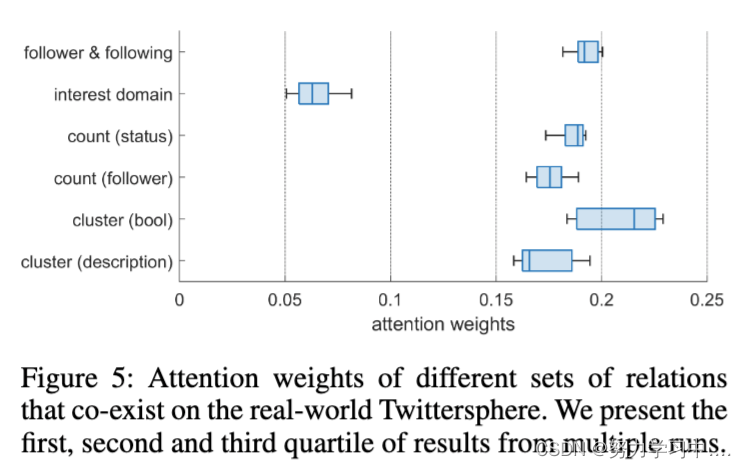
(在现实世界的Twitter上共存的不同关系集的注意权重。我们展示了多次运行的第一、第二和第三四分之一的结果)
总而言之,我们通过结合关系异质性来提高机器人检测性能,并且大多数关系在我们的方法的决策中都很重要。
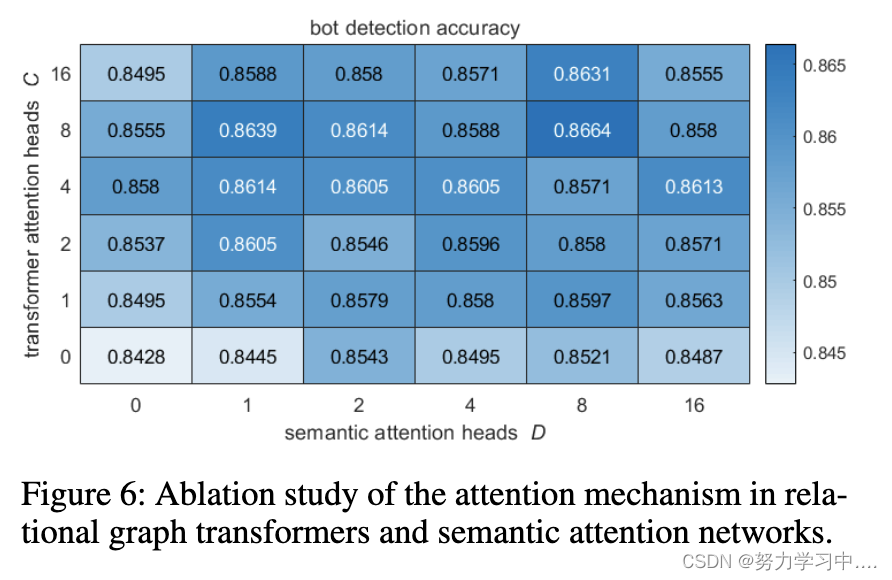
影响异质性 影响异质性是指 Twitter 用户在社交媒体上对他人的影响模式和强度不同。我们利用关系图transformers中的多头注意力机制来利用影响异质性。为了验证这种方法的有效性,我们对注意力机制进行了消融研究,并在图 6 中给出了结果。说明结合注意力机制 (C > 0, D > 0) 优于没有它的方法 (C = 0 , D = 0)。此外,采用多头注意力网络(C > 1,D > 1)通常优于单头注意力网络(C = 1,D = 1),证明了我们设计选择的有效性
在证明了利用影响力的必要性之后,我们研究了一个特定的Twitter用户群,并在图7中展示了他们的注意力权重。图中显示,机器人之间的影响力权重通常较大。通过对影响力异质性的建模,我们的方法可以识别出那些在群体中行动并对彼此产生重大影响的机器人。
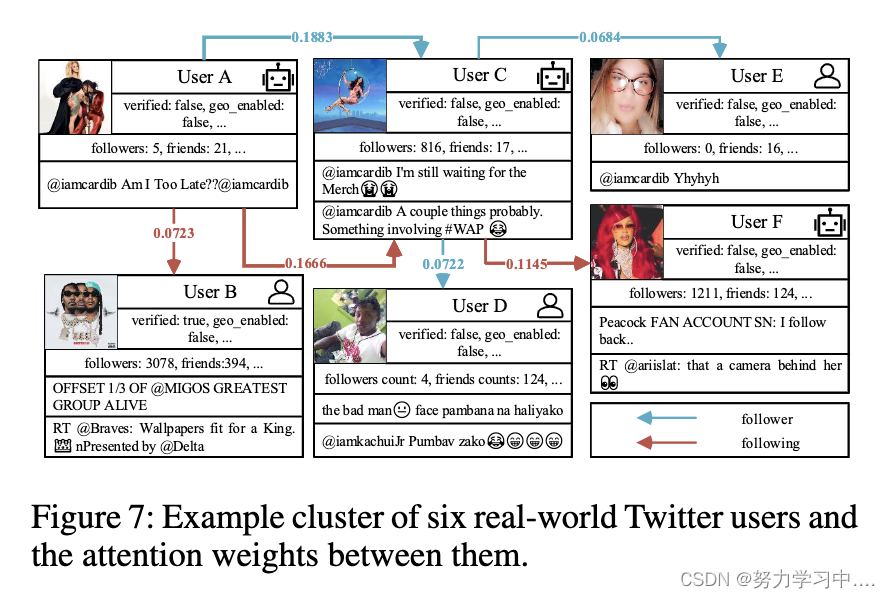
总而言之,我们通过利用影响异质性来提高机器人检测性能,而网络中用户之间的注意力权重为我们的模型决策提供了有价值的见解。
4.7 Data Efficiency Study
现有的机器人检测模型通常是有监督的并且依赖于大量的数据注释,而机器人检测数据集通常在大小和标签上受到限制。为了检查我们的机器人检测模型的数据效率,我们在图 8 中展示了部分训练集、随机移除边缘和屏蔽用户特征的性能。说明我们的方法仍然会优于 state-the-of- art BotRGCN (Feng et al. 2021d) 只有 40% 的训练数据,并且对用户交互的变化也很稳健。随着用户特征的减少,模型性能显着下降,这表明除了图结构之外,Twitter 机器人检测仍然依赖于对用户信息的全面分析。
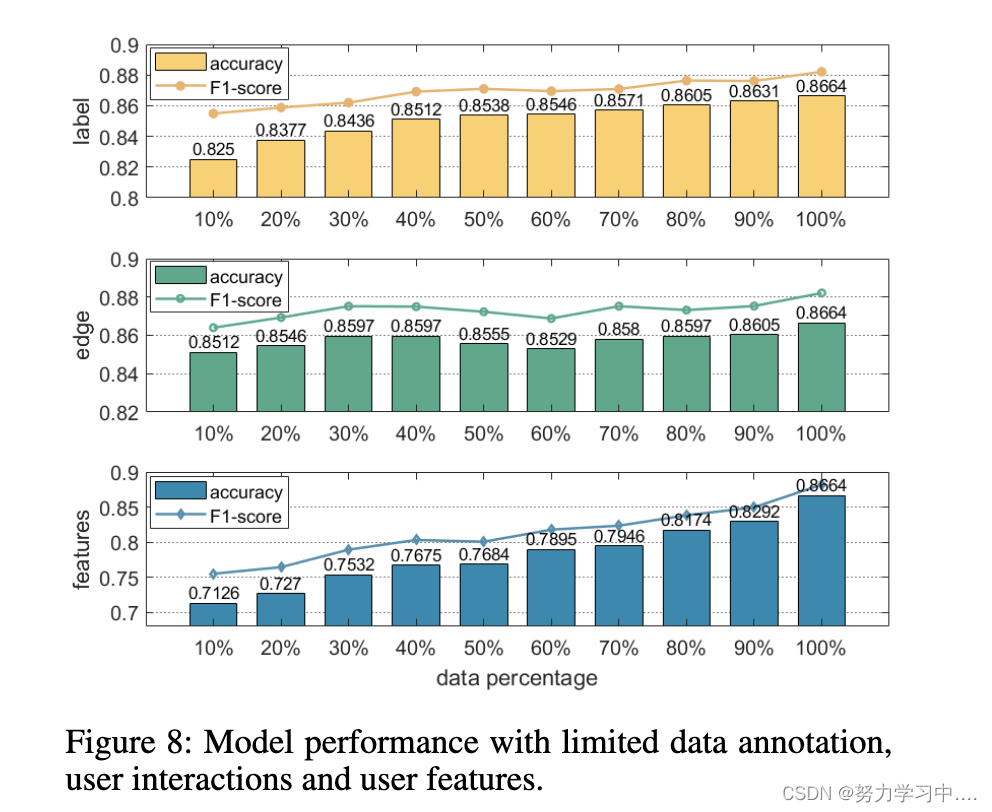
(在有限的数据注释、用户互动和用户特征下的模型性能)
4.8 Representation Learning Study
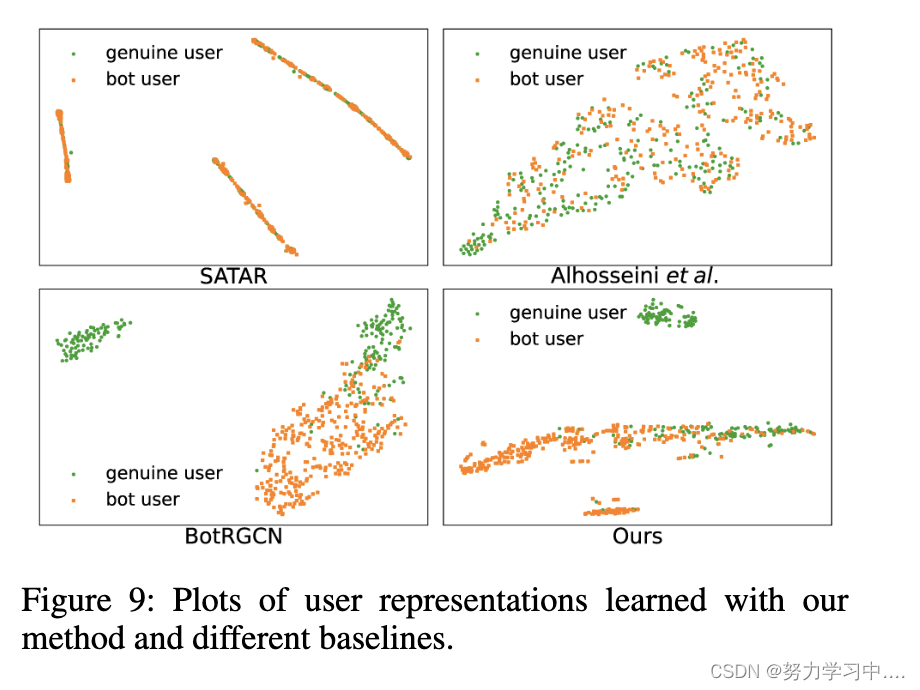
我们的模型和少数基线一样,为Twitter用户学习表征,并通过它们识别机器人。为了检验我们模型的表征学习的质量,我们在图9中展示了我们的方法和基线的用户表征的t-sne图。说明我们的结果显示了真正用户组和 Twitter 机器人的更高水平的搭配,这表明我们的方法学习了高质量的用户表示。
5 Conclusion and Future Work
推特机器人检测是一项重要且具有挑战性的任务。我们提出了一个基于图和异质性感知的机器人检测框架,该框架构建了HIN来表示Twittersphere,采用关系图transformer和语义注意网络进行表示学习和机器人检测。我们在一个综合基准上进行了广泛的实验,这表明我们的方法一直优于最先进的基准。
进一步的探索证明了我们的方法的图学习策略和对Twitter异质性的包含是真正有效的,同时也在有限的数据下表现良好,为Twitter用户学习了高质量的表示。我们计划在未来尝试用更多的方式将Twitter领域建模为图,并扩展我们基于图的机器人检测方法。

















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









