









论文链接:https://arxiv.org/pdf/2206.04564.pdf https://arxiv.org/pdf/2206.04564.pdf
https://arxiv.org/pdf/2206.04564.pdf
目录
2.2 Graph-based Social Network Analysis
4.3 Removing Graphs from Baselines
摘要
推特机器人检测已经成为一项日益重要的任务,以打击错误信息,促进社会媒体的调节,并保持在线话语的完整性。最先进的机器人检测方法通常利用Twitter网络的图结构,在面对传统方法无法检测到的新型Twitter机器人时,这些方法表现出良好的性能。然而,现有的Twitter机器人检测数据集很少是基于图的,即使这些少数基于图的数据集也存在数据集规模有限、图结构不完整以及注释质量低等问题。事实上,缺乏一个大规模的基于图的Twitter机器人检测基准来解决这些问题,严重阻碍了基于图的新型机器人检测方法的发展和评估。在本文中,我们提出了TwiBot-22,一个全面的基于图的Twitter机器人检测基准,它提出了迄今为止最大的数据集,提供了Twitter网络上多样化的实体和关系,并且具有比现有数据集更好的注释质量。此外,我们重新实现了35个有代表性的Twitter机器人检测基准,并在包括TwiBot-22在内的9个数据集上对其进行了评估,以促进对模型性能的公平比较和对研究进展的整体理解。为了促进进一步的研究,我们将所有实现的代码和数据集整合到TwiBot-22评估框架中,研究人员可以一致地评估新模型和数据集。TwiBot-22 Twitter机器人检测基准和评估框架可在以下网站公开获取。
1 绪论
推特上的自动用户,也被称为推特机器人,已经成为一个广为人知且有据可查的现象。在过去的十年中,恶意的Twitter机器人对一系列的问题负责,如网上虚假信息[Cui等人,2020,Wang等人,2020,Lu和Li,2020],选举干扰[Howard等人。2016,Neudert等人,2017,Rossi等人,2020,Ferrara,2017],极端主义运动[Ferrara等人,2016,Marcellino等人,2020],甚至阴谋论的传播[Ferrara,2020,Ahmed等人,2020,Anwar等人,2021]。这些社会挑战要求建立Twitter机器人自动检测模型,以减轻其负面影响。
现有的Twitter机器人检测模型通常是基于特征的,研究人员建议从元数据等用户信息中提取数字特征[Yang et al., 2020, Lee et al., ]用户时间线[Mazza等人,2019,Chavoshi等人,2016],以及关注关系[Beskow和Carley,2020,Chu等人,2012]。然而,基于特征的方法容易受到对抗性操纵的影响,即当机器人操作者试图通过篡改这些手工制作的特征来避免检测[Cresci等人,2017a,Cresci,2020]。研究人员还提出了基于文本的方法,其中文本分析技术,如单词嵌入[Wei and Nguyen, 2019]、循环神经网络[Kudugunta and Ferrara, 2018, Feng et al., 2021a]和预训练的语言模型[Duki ́c et al., 2020]被利用来分析推文内容并识别恶意的意图。然而,新一代的Twitter机器人经常将恶意内容与从真实用户那里窃取的正常推文穿插在一起[Cresci, 2020, Feng et al., 2021b],因此它们的机器人性质对基于文本的方法来说变得更加微妙。随着图神经网络的出现,最近的进展集中在开发基于图的Twitter机器人检测模型。这些方法[Ali Alhosseini等人,2019,Feng等人,2021b]将用户解释为节点,将关注关系解释为边,以利用图挖掘技术,如GCN[Kipf和Welling,2016]、R-GCN[Schlichtkrull等人,2018]和RGT[Feng等人,2021c]进行基于图的机器人检测。事实上,最近的研究表明,基于图的方法取得了最先进的性能,能够检测出新颖的Twitter机器人,并能更好地解决Twitter机器人检测面临的各种挑战[Feng等人,2021b,c] 。
然而,现有的数据集对基于图形的Twitter机器人检测模型的开发和评估支持不足。Bot Repository提供了一个现有数据集的综合集合。在列出的18个数据集中,只有两个,TwiBot-20 [Feng等人,2021d]和cresci- 2015 [Cresci等人,2015],明确提供了Twitter用户之间的图结构。此外,这两个基于图的数据集还存在以下问题,如图1所示
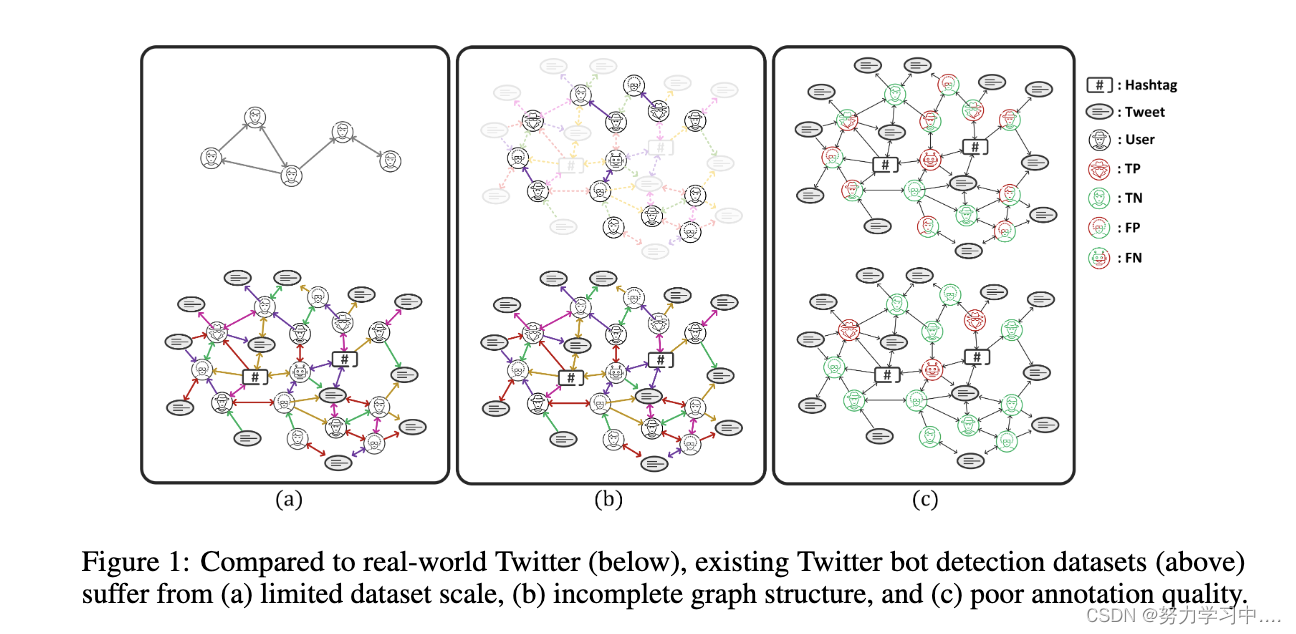
(与现实世界的 Twitter(下图)相比,现有的 Twitter 机器人检测数据集(上图)存在以下问题:(a)数据集规模有限,(b)图结构不完整,以及(c)注释质量差。)
(a) 数据集规模有限。Twibot-20[Feng等人,2021d]包含11,826个标记的用户,Cresci- 15[Cresci等人,2015]包含7,251个标记的用户,而在线对话和关于激烈话题的讨论往往涉及数十万用户[Banda等人,2021]。
(b) 不完整的图结构。真实世界的Twitter是一个异质的信息网络,包含多种类型的实体和关系[Feng等人,2021c],而TwiBot-20和cresci-15只提供用户和关注关系。
(c) 注释质量低。TwiBot-20求助于众包进行用户注解,而众包会导致显著的噪音[Graells-Garrido and Baeza-Yates, 2022],并且容易出现假阳性问题[Rauchfleisch and Kaiser, 2020]
鉴于这些挑战,我们提出了TwiBot-22,一个基于图形的Twitter机器人检测基准,以解决这些问题。具体来说,TwiBot-22采用了两阶段的控制性扩展来对Twitter网络进行采样,这使得数据集的规模是现有最大数据集的5倍。TwiBot-22提供了Twitter网络中的4种实体和14种关系,这为Twitter机器人检测提供了第一个(真正的)异质图。TwiBot-22适用于数据注释的弱监督学习策略可显着提高注释质量。
为了将TwiBot-22与现有的数据集进行比较,我们重新实现了35个Twitter机器人检测基线,并在包括TwiBot-22在内的9个数据集上进行了评估,以提供一个研究进展的整体视图,并突出TwiBot-22的优势。我们将所有数据集和实现的代码整合到TwiBot-22评估框架中,以促进进一步的研究。我们的主要贡献总结如下:
(1)我们提出了TwiBot-22,一个基于图的Twitter机器人检测数据集,它建立了迄今为止最大的基准,提供了Twitter网络中多样化的实体和关系,并大大改善了注释质量。
(2)我们在包括TwiBot-22在内的9个数据集上重新实现了35个现有的Twitter机器人检测模型,以公平地比较不同的方法,并促进对Twitter机器人检测研究进展的整体理解。
(3)我们提出了TwiBot-22评估框架,研究人员可以很容易地复制我们的结果,检查现有的数据集和方法,对未见过的Twitter数据进行推断,并为该框架贡献新的数据集和模型。
2 相关工作
2.1 Twitter Bot Detection
现有的Twitter机器人检测方法主要分为三类:基于特征的方法、基于文本的方法和基于图形的方法。
基于特征的方法利用用户信息进行特征工程,并应用传统的分类算法进行机器人检测。从用户元数据[Kudugunta和Ferrara,2018]、推文[Miller等人,2014]、描述[Hayawi等人,2022]、时间模式[Mazza等人,2019]和关注关系[Feng等人,2021a]中提取各种特征。后来的研究工作提高了基于特征的方法的可扩展性[Yang et al., 2020],自动发现新的机器人[Chavoshi et al., 2016],并在精度和召回率之间取得平衡[Morstatter et al., 2016]。然而,随着机器人操作者越来越了解这些手工制作的特征,新的机器人经常试图篡改这些特征以逃避检测[Cresci, 2020]。因此,基于特征的方法很难跟上机器人进化的军备竞赛[Feng等人,2021a]。
基于文本的方法使用自然语言处理中的技术来检测基于推文和用户描述的Twitter机器人。字词嵌入[Wei and Nguyen, 2019]、递归神经网络[Kudugunta and Ferrara, 2018]、注意力机制[Feng et al., 2021a]和预训练的语言模型[Duki ́c et al., 2020]被采用来对推文进行编码以进行机器人检测。后来的研究将推文表征与用户特征相结合[Cai等人,2017],学习无监督的用户表征[Feng等人,2021a],并试图解决推文内容的多语言问题[Knauth,2019]。然而,新颖的机器人开始对抗基于文本的方法,用从真正的用户那里偷来的真实内容稀释恶意的推文[Cresci, 2020]。此外,Feng等人[2021b]表明,仅分析推文内容可能对机器人检测不具有鲁棒性和准确性。
基于图的方法将Twitter解释为图,并利用网络科学和几何深度学习的概念进行Twitter机器人检测。节点中心度[Dehghan等人,2022]、节点表示学习[Pham等人,2022]、图神经网络(GNN)[Ali Alhosseini等人,2019]和异质GNN[Feng等人,2021b]被采用来进行基于图的Twitter机器人检测。后来的研究试图结合基于图的方法和基于文本的方法[Guo et al., 2021a]或提出新的GNN架构,以利用Twitter网络的异质性[Feng et al., 2021c]。基于图的方法在解决Twitter机器人检测所面临的各种挑战方面显示出巨大的前景,例如机器人社区和机器人伪装[Feng等人,2021b]。
如果没有过去十年来提出的许多有价值的Twitter机器人检测数据集,这些模型的开发和评估是不可能的。这些数据集主要集中在美国的政治和选举[Yang等人,2020]和欧洲国家[Cresci等人,2017a]。Cresci-17 [Cresci et al., 2017a]提出了 "社会垃圾机器人 "的概念,并提出了一个广泛使用的数据集,其中有不止一种类型的机器人。TwiBot-20 [Feng et al., 2021d]是最新、最全面的Twitter机器人检测数据集,解决了以前数据集的用户多样性问题。然而,在Bot Repository(Twitter机器人检测研究的首选之地)提供的18个数据集中,只有2个明确提供了Twitter网络的图结构。此外,这些数据集存在数据集规模有限、图结构不完整和注释质量低的问题,它们越来越不能充分和持续地对基于图的新方法进行基准测试。鉴于这些挑战,我们提出TwiBot-22,以缓解这些问题,促进对研究进展的重新思考,并促进Twitter机器人检测的进一步研究。
2.2 Graph-based Social Network Analysis
在线社交网络中的用户相互作用,成为网络结构的一部分,而网络结构对于理解社交媒体的模式至关重要[Carrington等人, 2005]。随着几何深度学习的出现,图神经网络(GNNs)在社交网络分析研究中越来越受欢迎。Qian等人[2021]提出用异质图对社交媒体进行建模,并利用关系型GNNs进行非法毒品贩运者的检测。Guo等人[2021b]提出双图增强嵌入神经网络,以改善图表示的学习,并解决点击率预测的挑战。图和GNN也被用于检测在线欺诈[Liu等人,2021,Li等人,2021,Wang等人,2021,Dou等人,2020],打击错误信息[Cui等人,2020,Wang等人,2020,Lu和Li,2020,Varlamis等人,2022],并改进推荐系统[Ying等人,2018,Wu等人,2020]。推特机器人检测的任务也不例外,其中新的和最先进的方法越来越多地基于图形[Ali Alhosseini等人,2019,Magelinski等人,2020,Feng等人,2021b,c]。在本文中,我们提出了TwiBot-22基准,以更好地支持基于图的Twitter机器人检测模型的开发和评估。
3 TwiBot-22 Dataset
3.1 Data Collection
TwiBot-22旨在提出一个大规模和基于图形的Twitter机器人检测基准。为此,我们采用了一个两阶段的数据收集过程。首先,我们采用多样性感知的广度优先搜索(BFS)来获得TwiBot-22的用户网络。然后,我们在Twitter网络上收集额外的实体和关系,以充实TwiBot-22网络的异质性。
用户网络收集。现有的Twitter机器人检测数据集的一个共同缺点是,它们只具有少数类型的机器人和真正的用户,而现实世界的Twitter是多样化的用户和机器人的家园[Feng等人,2021d]。因此,TwiBot-20提议使用广度优先搜索(BFS)来收集用户,从 "种子用户 "开始,并通过用户关注关系来扩展。为了确保TwiBot-22包括不同类型的机器人和真正的用户,我们用两种感知多样性的抽样策略增强了BFS:
分布多样性。考虑到用户元数据,如追随者数量,不同类型的用户在元数据分布中的位置不同。分布多样性旨在对分布的顶部、中部和底部的用户进行采样。对于数字元数据,在一个用户的邻居和他们的元数据值中,我们选择价值最高的k个用户,最低的k个,以及从其他用户中随机选择的k个。对于真或假的元数据,我们选择k个为真,k个为假。
价值多样性。给定一个用户和它的元数据,采用价值多样性,这样具有明显不同的元数据值的邻居更有可能被包括在内,确保收集的用户的多样性。对于数字元数据,在扩大的用户u的邻居X和他们的元数据值中,用户x∈X被采样的概率被表示为
。对于真或假的元数据,我们从相反的类别中选择k个用户。
基于这些抽样策略,TwiBot-22从@NeurIP- SConf开始进行多样性感知的BFS。对于每个邻域的扩展,一个元数据和一个抽样策略被随机地采用。BFS过程停止,直到用户网络包含一个理想的Twitter用户数量。关于用户收集过程的更多信息在附录A.2中介绍。
异质图的构建。用户网络收集过程构建了一个以用户为节点、以关注关系为边的同质图。除此之外,Twitter网络还包含多样化的实体和关系,如列表和转发。基于用户网络,我们收集这些用户的推文、相关列表和提及的标签,以及用户和这些新实体之间的12种其他关系。因此,TwiBot-22呈现了一个具有4种实体和14种关系的异质性Twitter网络。关于异质推特网络的更多信息,见附录A.4。
因此,我们得到了TwiBot-22异质图,它包含92,932,326个节点和170,185,937条边。我们在附录中的表7中介绍了更多的数据集统计数据。
3.2 Data Annotation
现有的机器人检测数据集通常依赖于人工标注或众包,而这是劳动密集型的,因此对于大规模的TwiBot-22来说是不可行的。因此,我们采用弱监督学习策略来生成高质量的标签。我们首先邀请机器人检测专家为TwiBot-22中的1000个Twitter用户进行注释。然后,我们在机器人检测模型的帮助下生成噪音标签。最后,我们用Snorkel[Ratner等人,2017]为TwiBot-22生成高质量注释。
专家注解。我们在TwiBot-22中随机选择1000个用户,并将每个用户分配给5个Twitter机器人检测专家,以识别它是否是一个机器人。然后,我们为这些专家的注释创建一个8:2的分割,作为训练和测试集。关于这些专家的更多细节,见附录A.3。
生成噪声标签。我们采用了8个手工制作的标签函数和7个基于特征和神经网络的竞争性机器人检测模型来生成噪声标签。对于手工制作的标签函数,我们采用了推文和用户描述中的垃圾关键词,以及用户的分类特征,如已验证和敏感的推文。对于特征工程模型,我们根据用户的元数据选择特征,如创建时间、关注者数量和名字长度。然后,我们采用Adaboost、随机森林和MLP来产生三个基于特征的分类器。对于基于神经网络的模型,我们遵循Feng等人[2021b]对用户信息进行编码,并采用MLP、GAT[Veliˇckovi ́c等人,2017]、GCN[Kipf和Welling,2016]和R-GCN[Schlichtkrull等人,2018]作为四个分类器。我们在专家注释的训练集上训练这些分类器,并在每个分类器下计算TwiBot-22中所有用户的不确定性分数为,其中
和
表示是真实用户或机器人的概率。对于每个分类器,我们会删除不确定性分数最高的40%的模型预测,以减轻标签噪音。
多数人投票。在获得噪声标签后,我们用Snorkel[Ratner等人,2017]评估其可信度,并同时清理标签。Snorkel系统的输出是概率性标签,因此我们用这些标签来训练MLP分类器,以获得TwiBot-22的最终注释。我们在专家注释的测试集上进一步评估注释质量,我们获得了90.5%的准确率。与TwiBot-20[Feng等人,2021d]中80%的准确率标准相比,TwiBot-22的注释质量有了很大的提高。
3.3 Data Analysis
现有的基于图形的Twitter机器人检测数据集存在数据集规模有限、图形结构不完整和注释质量低等问题。因此,我们研究了TwiBot-22是否已经充分解决了这些挑战,并在图2中展示了我们的发现。
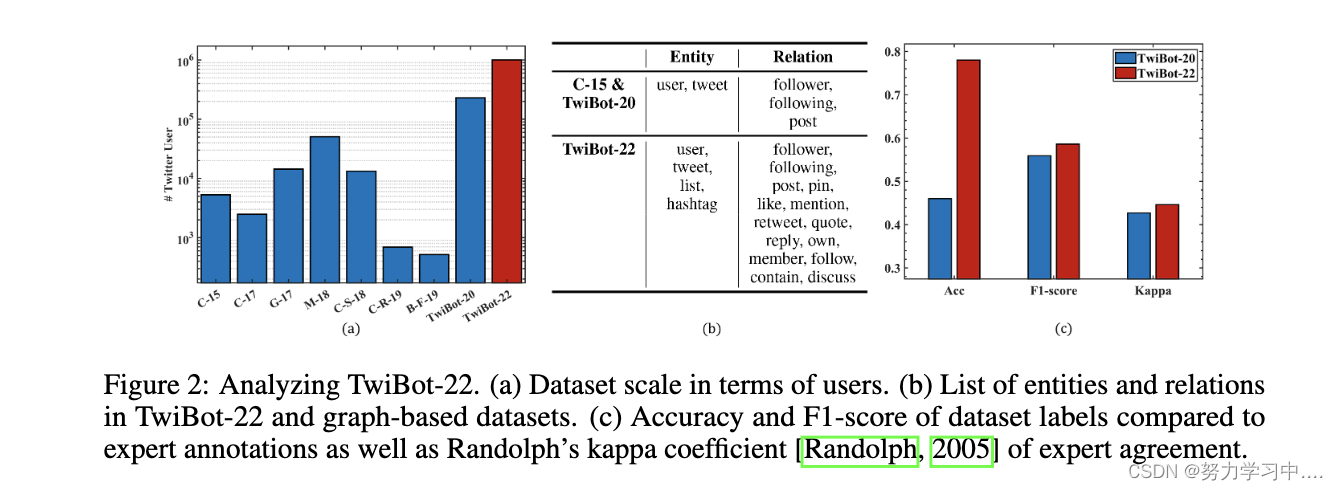
(分析TwiBot-22。(a) 以用户为单位的数据集规模。(b) TwiBot-22和基于图的数据集中的实体和关系列表。(c) 数据集标签的准确性和F1分数与专家注释以及专家协议的Randolph's kappa系数[Randolph, 2005]相比。)
数据集规模。图2(a)说明了TwiBot-22和现有数据集的Twitter用户数量。TwiBot-22建立了迄今为止最大的Twitter机器人检测基准,其用户数大约是第二大的TwiBot-20的5倍。
图结构。图2(b)表明TwiBot-22网络包含4种实体类型和14种关系类型,与现有的基于图的数据集cresci-15和TwiBot-20相比,图结构明显丰富,后者只包含2种实体类型和3种关系类型。
注释质量。TwiBot-20是迄今为止最大的基于图形的Twitter机器人检测基准,利用众包进行数据注释。为了提高标签质量,TwiBot-22使用弱监督学习策略,并利用1,000名专家的注释来指导这一过程。为了考察TwiBot-22是否比TwiBot-20有更好的注释质量,我们请Twitter机器人检测专家参与 "专家研究",让他们评估TwiBot- 20和TwiBot-22中的用户,以考察专家对数据集标签的认同程度。图2(c)说明了结果,这表明这些专家认为TwiBot-22提供了更一致、更准确、更值得信赖的数据注释。关于专家研究的更多细节,可在附录中找到。
4 实验
4.1 Experiment Settings
数据集。我们在Bot Reporistory中包含机器人和真实用户的所有9个数据集上评估Twitter机器人检测模型:Cresci-2015 [Cresci et al., 2015], gilani-2017 [Gilani et al., 2017], cresci-2017 [Cresci et al, 2017a,b],midterm-18 [Yang et al., 2020],cresci-stock-2018 [Cresci et al., 2018, 2019],cresci-rtbust-2019 [Mazza et al., 2019],botometer-feedback-2019 [Yang et al., 2019],TwiBot-20 [Feng et al., 2021d] 和 TwiBot-22。我们在表1中介绍了数据集的细节。我们创建了一个7:2:1的随机分割作为训练、验证和测试集,以确保公平比较。
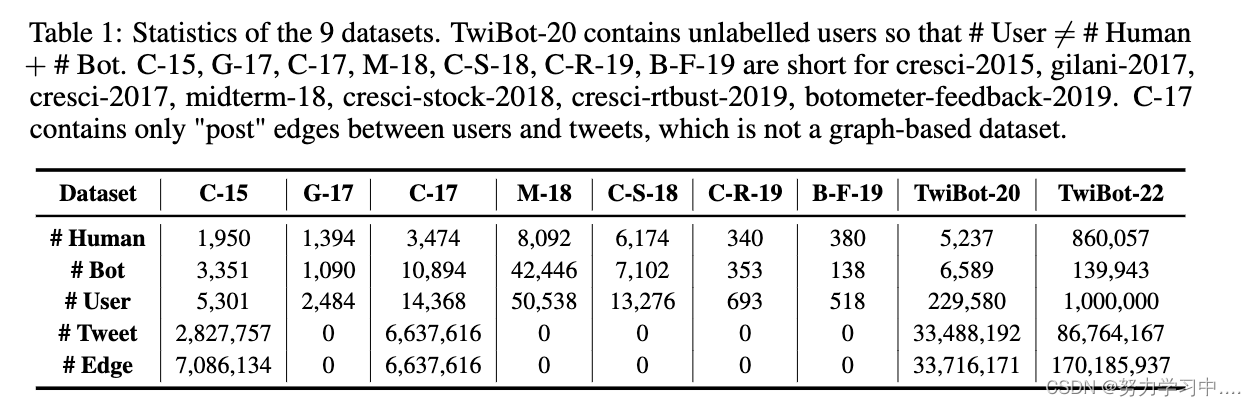
(9个数据集的统计数字。TwiBot-20包含未标记的用户,因此。C-15、G-17、C-17、M-18、C-S-18、C-R-19、B-F-19是cresci-2015、gilani-2017、cresci-2017、midterm-18、cresci-stock-2018、cresci-rtbust-2019、botometer-feedback-2019的简称。C-17只包含用户和推文之间的 "帖子 "边,这不是一个基于图的数据集。)
基线。我们重新实施并评估了35个Twitter机器人检测基线SGBot [Yang et al., 2020], Kudugunta and Ferrara [2018], Hayawi et al. [2022], BotHunter [Beskow and Carley, 2018], NameBot [Beskow and Carley, 2019], Abreu et al. [2020], Cresci et al. [2016], Wei and Nguyen [2019], BGSRD [Guo et al, 2021a], RoBERTa [Liu et al., 2019], T5 [Raffel et al., 2019], Efthimion et al. [2018], Kantepe and Ganiz [2017], Miller et al. [2014], Varol et al. [2017], Kouvela et al. [2020], Ferreira Dos Santos et al. [2019], Lee et al. [2011], LOBO [Echeverr? 2018], Moghaddam and Abbaspour [2022], Ali Alhosseini et al. [2019], Knauth [2019], FriendBot [Beskow and Carley, 2020], SATAR [Feng et al., 2021a], Botometer [Yang et al., 2022], Rodríguez-Ruiz et al. [2020], GraphHist [Magelinski et al, 2020], EvolveBot [Yang et al., 2013], Dehghan et al. [2022], GCN [Kipf and Welling, 2016], GAT [Veliˇckovi ́c et al., 2017], HGT [Hu et al., 2020], SimpleHGN [Lv et al., 2021], BotRGCN [Feng et al., 2021b], RGT [Feng et al.] 这些方法利用用户信息的不同方面,代表机器人检测研究的不同阶段。关于这些基线方法的更多细节,请见附录B.1。
4.2 Experiment Results
我们重新实现了35种基线方法,并在9个Twitter机器人检测数据集上对它们进行了评估。每个基线都进行了5次,我们报告了平均性能和标准偏差。表2列出了基准测试的结果。我们的主要发现总结如下。
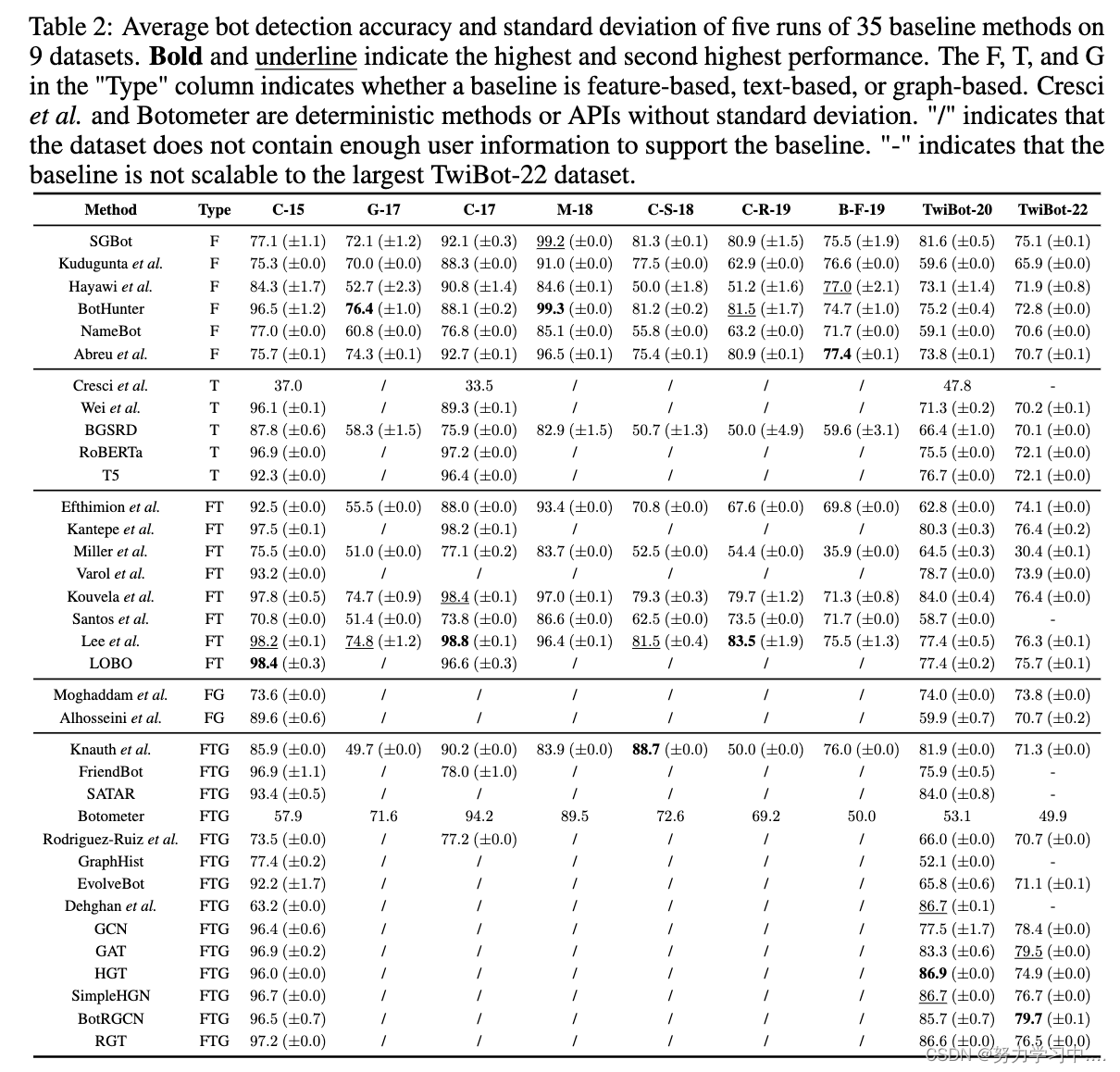
(35种基线方法在9个数据集上运行5次的平均机器人检测精度和标准偏差。粗体和下划线表示最高和次高的性能。类型 "一栏中的F、T和G表示基线是基于特征、基于文本还是基于图形。Cresci等人和Botometer是没有标准偏差的确定性方法或API。"/"表示数据集不包含足够的用户信息来支持基线。"-"表示基线不能扩展到最大的TwiBot-22数据集)
基于图的方法通常比基于特征或文本的方法更有效。事实上,TwiBot-20和TwiBot-22的所有前5个模型都是基于图形的。平均来说,在TwiBot-20和TwiBot-22上,这些基于图的前5名方法比所有基线的平均水平要好17.3%和9.4%。这一趋势表明,未来的Twitter机器人检测研究应该进一步研究用户和机器人在Twitter上如何互动以及由此形成的图结构。
大多数现有的数据集没有提供Twitter用户的图结构来支持基于图的方法,而TwiBot-22支持所有的基线方法并作为一个全面的评估基准。由于新的和最先进的模型越来越基于图形,未来的Twitter机器人检测数据集应该提供真实世界Twitter的图形结构。
TwiBot-22建立了最大的基准,同时暴露了基线方法的可扩展性问题。例如,Dehghan等人[2022]在TwiBot-20上实现了近乎完美的性能,而在TwiBot-22上却无法扩展,因为我们的实现遇到了内存不足的问题。
在所有基线方法中,TwiBot-22的性能平均比TwiBot-20低4.8%,这表明Twitter机器人检测仍然是一个开放的问题,需要进一步研究。这可能是由于Twitter机器人在不断进化,以改进其伪装和逃避检测,因此机器人检测方法也应该适应和发展。
4.3 Removing Graphs from Baselines
表2中的基准测试结果表明,基于图的方法通常能取得更好的性能。为了考察图在基于图的方法中的作用,我们在有竞争力的基于图的方法[Ali Alhosseini et al., 2019, Moghaddam and Abbaspour, 2022, Knauth, 2019, Yang et al., 2013, Feng et al., 2021b,c]中去除图的成分,并在表3中报告模型性能。证明了这一点。
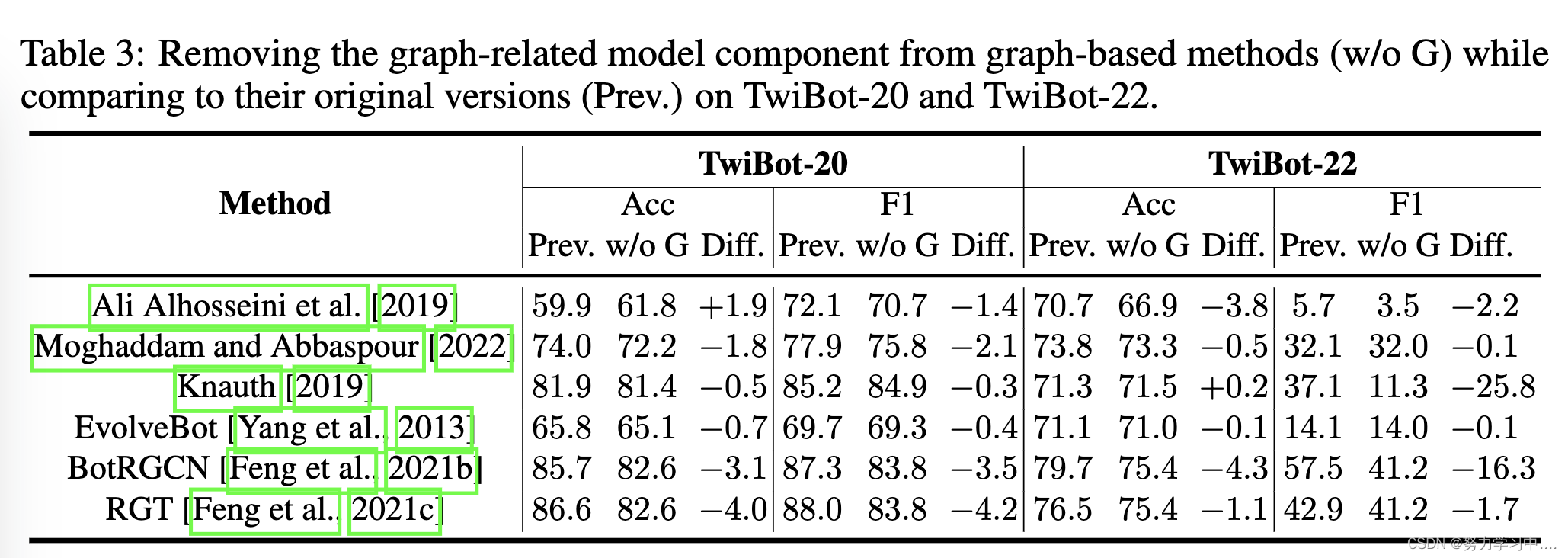
(在TwiBot-20和TwiBot-22上,从基于图的方法(w/o G)中去掉与图有关的模型成分,同时与它们的原始版本(Prev)相比较。)
所有的基线方法在两个数据集上都表现出不同程度的性能下降,当图形组件被移除时。这表明,基于图形的方法中与图形有关的部分对机器人检测性能有贡献。
对于基于图神经网络的方法BotRGCN[Feng等人,2021b]和RGT[Feng等人,2021c],性能下降一般比较严重。这表明图神经网络在提升模型性能和推进机器人检测研究方面发挥了重要作用。
关于如何从基线方法中删除图形的更多细节,见附录B.4。
4.4 Generalization Study
泛化的挑战[Yang等人,2020,Feng等人,2021a],即Twitter机器人检测模型是否在未见过的数据上表现良好,对于确保机器人检测研究转化为有效的适合社交媒体和现实世界影响至关重要。为了评估现有Twitter机器人检测方法的泛化能力,我们在TwiBot-22网络中确定了10个子社区。然后,我们将这些子社区作为折,在折i上训练并在折j上评估时,考察几个代表性模型的性能。
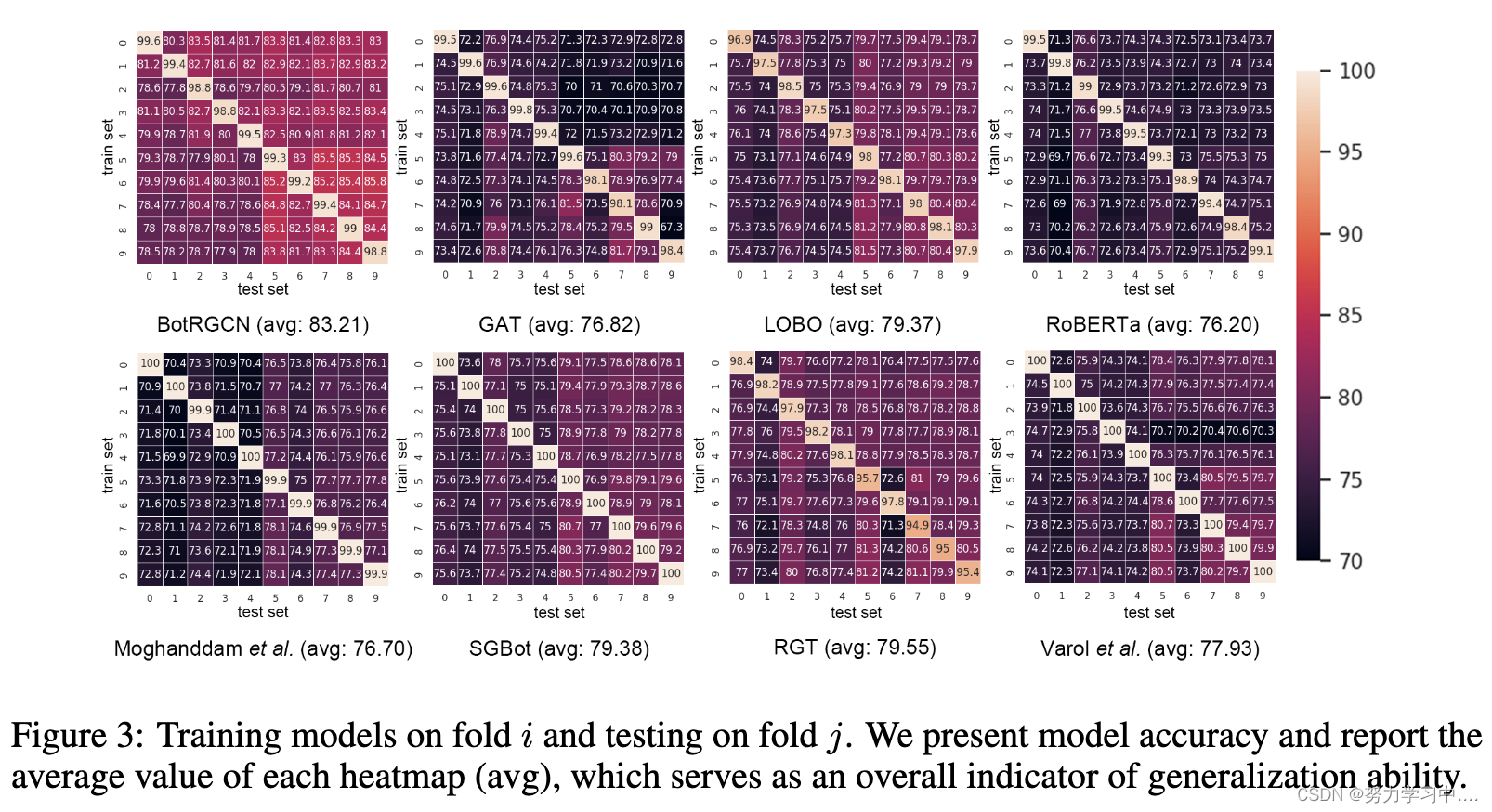
(我们提出模型的准确性,并报告每个热图的平均值(avg),作为概括能力的总体指标。)
基于图的方法更善于对未见过的数据进行归纳。例如,BotRGCN[Feng等人,2021b]在所有基线方法中取得了最好的平均分,比第二高的RGT高出3.66分。这表明,利用Twitter的网络结构可能是解决泛化挑战的一个办法。
良好的模型性能不一定能转化为良好的泛化能力。例如,GAT在TwiBot-20和TwiBot-22上的准确率分别比LOBO高出5.9%和3.8%。然而,与LOBO相比,GAT的平均分(-2.55)较低。这表明,未来的机器人检测研究除了模型性能外,还应该关注泛化问题。
附录 B.5 提供了有关 10 个子社区的更多详细信息。
5 评估框架
我们将Twitter机器人检测数据集、数据预处理代码和所有35个已实现的基线整合到TwiBot-22评估框架中,并将其公开。我们希望通过我们的努力,促进Twitter机器人检测的进一步研究。
为不同类型的Twitter机器人检测数据集建立统一的接口;
提供35个有代表性的基线和有据可查的实施方案;
用未来研究中提出的新数据集和方法充实评估框架;
TwiBot-22: Towards Graph-Based Twitter Bot Detectionhttps://twibot22.github.io/
6 结论和未来工作
在本文中,我们提出了TwiBot-22,一个基于图的Twitter机器人检测基准。TwiBot-22成功地缓解了现有数据集规模有限、图结构不完整和注释质量差等挑战。具体来说,我们采用了一个两阶段的数据收集过程,并采用弱监督学习策略进行数据注释。然后,我们重新实现了35个有代表性的Twitter机器人检测模型,并在包括TwiBot-22在内的9个数据集上进行评估,以促进对研究进展的整体理解。我们进一步研究了图在基于图的方法中的作用以及竞争性机器人检测基线的泛化能力。最后,我们将所有实现的代码整合到TwiBot-22评估框架中,研究人员可以很容易地复制我们的实验,并快速测试出新的数据集和模型。

















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









