









TwiBot-20 —— 一个全面的Twitter机器人检测基准
论文链接:https://arxiv.org/pdf/2106.13088.pdf https://arxiv.org/pdf/2106.13088.pdf
https://arxiv.org/pdf/2106.13088.pdf
目录
2.1 Social Media Bot Detection
2.2 Twitter Bot Detection Datasets
4.3 User Information Selection
5.4 Annotation Quality Analysis
摘要
推特已经成为一个重要的社交媒体平台,同时存在大量的恶意推特机器人,并引发了不良的社会影响。成功的Twitter机器人检测方案通常是有监督的,这在很大程度上依赖于大规模数据集。然而,现有的基准通常存在用户多样性水平低、用户信息有限和数据稀缺的问题。因此,这些数据集不足以训练和稳定的基准机器人检测措施。为了缓解这些问题,我们提出了TwiBot-20,一个大规模的Twitter机器人检测基准,其中包含229,573个用户,33,488,192条推文,8,723,736个用户属性项目和455,958个关注关系。TwiBot-20涵盖了多样化的机器人和真正的用户,以更好地代表现实世界的Twitter领域。TwiBot-20还包括用户信息的三种模式,以支持单一用户的二元分类和社区感知的方法。就我们所知,TwiBot-20是迄今为止最大的Twitter机器人检测基准。我们重现了有竞争力的机器人检测方法,并对TwiBot-20和其他两个公共数据集进行了全面评估。实验结果表明,现有的机器人检测方法在TwiBot-20上的表现与他们之前宣称的表现不符,这表明Twitter机器人检测仍然是一项具有挑战性的任务,需要进一步的研究努力。
1 绪论
推特是最受欢迎的社交媒体平台之一,根据Statista的报告,每天有数百万活跃的推特用户使用该平台。推特也是免费使用和容易访问的,这鼓励了个人和组织查看和发布感兴趣的内容。除了被真正的用户使用之外,Twitter也有大量的自动程序,也就是所谓的Twitter机器人。一些Twitter机器人利用Twitter的功能来追求恶意的目标,如干扰选举和极端宣传。Twitter机器人与Twitter上的人类用户共存,它们通过模仿真正的用户来掩盖其自动化的本质。由于识别社交媒体中的机器人对于维护在线话语的完整性至关重要,而且这些方法一般都是有监督的,因此许多研究工作都致力于创建相关的数据集。
在过去的十年中,已经提出并使用了许多机器人检测数据集。 关于数据集的用户组成,pronbots 数据集仅包含 Twitter 机器人,其中机器人检测被视为异常值检测任务,而大多数数据集,例如 varol-icwsm 和 cresci-17 , 包含人类和机器人用户,形成一个二元分类问题。在用户信息方面,caverlee提供了Twitter用户的语义和属性信息,而gilani-17等只包括属性信息,它们在用户信息的完整性方面有很大的不同。关于数据集的大小,每个数据集所包含的用户数量也从cresci- rtbust的693个用户到midterm-18的50538个用户不等,其中使用最广泛的数据集cresci-17包含2764个人类用户和7049个机器人。
虽然以前的研究工作为训练和评估提供了大量的机器人检测数据集,但它们普遍存在以下问题,未能提供一个稳定的基准:
用户多样性。现有的机器人检测数据集通常专注于特定类型或用户群,未能捕捉到在现实世界 Twittersphere 中共存的多样化机器人。例如,数据集 midterm-18 仅包含积极参与 2018 年美国中期选举的用户。因此,它无法评估现有方法识别政治之外的机器人的能力。
有限的用户信息。推特用户拥有语义、属性和邻里信息,而现有的基准只包括一小部分多模式的用户信息,不够全面。例如,被广泛采用的cresci-17只包含语义和属性信息,没有纳入用户邻里信息来支持基于社区的机器人检测方法。
数据的稀缺性。以前的小规模数据集不足以训练和稳定地衡量新的机器人检测措施,阻碍了新方法的发展。据我们所知,现有最大的机器人检测数据集midterm- 18 包含50,538个用户,使得越来越复杂的机器人检测器对数据非常渴望。
针对以往机器人检测数据集的不足,我们收集并标注了一个综合的 Twitter 机器人检测基准 TwiBot-20,它可以缓解用户多样性不足、用户信息有限和数据稀缺的问题:
我们通过关注关系进行基于BFS的遍历,从不同主题的大量种子用户开始。因此,TwiBot-20中的用户在地理位置和兴趣领域上是多样化的,这使得TwiBot-20更能代表当前的Twitter领域。
我们从 Twitter API 中检索所有三种用户信息模式,即语义、属性和邻域信息,以促进利用多模式用户信息。据我们所知,TwiBot-20 是第一个公开可用的包含用户关注关系的机器人检测数据集。
据我们所知,TwiBot-20建立了迄今为止最大的Twitter机器人检测基准,其中包含229,573个Twitter用户,8,723,736个用户属性项目,33,488,192条推文和455,958个关注链接。
在下文中,我们首先在第2节中回顾相关工作,然后在第3节中定义Twitter机器人检测的任务。我们在第四节中详细介绍了TwiBot-20的收集和注释过程,并在第五节中进行了深入的数据分析。我们在第6节中进行了广泛的实验,以评估现有的TwiBot-20的机器人检测措施,并在第7节中总结了本文。
2 相关工作
在本节中,我们简要回顾了社交媒体机器人检测和Twitter机器人检测数据集的相关文献。
2.1 Social Media Bot Detection
第一代关于Twitter机器人检测的基准中在用户信息的特征工程上。Lee等人提出了验证推文中的URL重定向。Thomas等人专注于对提到的网站进行分类。Gao等人将垃圾推文合并到活动中进行机器人检测。Yang等人设计了新的特征来对抗Twitter机器人的演变。其他特征也被采用,如用户主页的信息,社交网络,以及账户的时间线。随着深度学习的出现,神经网络越来越多地被用于Twitter机器人检测。Stanton等人利用生成式对抗网络进行Twitter机器人检测。Wei等人使用递归神经网络来识别带有推文语义的机器人。Kudugunta等人联合利用用户特征和推文语义,提出了一个基于LSTM的机器人检测器。Alhos- seini等人提出采用图卷积网络来利用用户特征和Twittersphere结构。
2.2 Twitter Bot Detection Datasets
大量的数据集被提出来用于训练和评估机器人检测方法。最早的机器人检测数据集之一是caverlee-2011,它从2009年12月30日至2010年8月2日在Twitter上收集了22223个内容污染者和19276个合法用户。
另一个早期的数据集是cresci-2015,它提供了一个真实账户和虚假粉丝的数据集。自2017年以来,越来越多的机器人检测基准被提出。
varol-2017包含2,573个Twitter账户的人工注释。
vendor-purchased-2019由网上购买的假关注者账户组成。据我们所知,迄今为止最大的Twitter机器人检测数据集是midterm-18,提供了50,538个注释的用户。
除此之外,verified-2019, botwiki-2019 , cresci-rtbust-2019 , Astroturf 也是较新的机器人检测数据集,具有不同的规模和信息完整性。
3 问题定义
Twitter机器人是一种通过自动程序和Twitter API控制Twitter账户的机器人软件。
在本文中,我们研究了Twitter机器人的检测问题,以识别追求恶意目标的Twitter机器人,因为它们对在线话语构成了威胁。假设是一个Twitter用户,由用户形成的三个方面组成:语义、属性和邻居。
推特用户的语义信息是用户生成的自然语言帖子和文本,如推文和回复。
推特用户的属性信息是数字和分类的用户特征,如关注者数量和用户是否被验证。
推特用户的邻域信息是他们的追随者和关注者,它们构成了Twittersphere的图结构。
与之前的研究类似,我们将Twitter机器人检测视为一个二元分类问题,每个用户可能是人类(=0)或机器人(=1)。
从形式上看,我们可以将Twitter机器人检测任务定义如下。
给定一个Twitter用户和它的信息,和,学习一个机器人检测函数f:,使
近似于地面真相,使预测精度最大化。
4 数据采集
在本节中,我们将介绍如何从 Twittersphere 中选择 Twitter 用户、检索多模态用户信息并得出可信赖的注释来构建基准。 TwiBot-20 是在 2020 年 7 月至 2020 年 9 月以这种方式收集的。
4.1 User Selection Strategy
为了使用户采样多样化,以便更好地接近当前的Twittersphere,TwiBot-20采用了广度优先搜索,从不同的根节点开始,这在我们的算法中称为种子用户。
具体来说,我们把Twittersphere上的用户视为节点,把他们的关注关系视为边,形成一个有向图。
对于每个种子用户,它被放在该用户集群的第0层;
第1层的用户是由第1层的用户沿其关注边扩展而来;
这样的扩展过程在第3层结束,形成一个用户集群。
TwiBot-20将从不同种子用户开始的用户集群合并起来,形成完整的数据集。TwiBot-20的用户选择策略在算法1中提出,遵循第3节中定义的符号。TwiBot-20的用户选择策略与之前的基准不同,它不要求被选中的用户遵循任何给定的模式,也不限制他们参与任何特定的话题。这种约束的放松对于TwiBot-20更好地代表多样化的Twitter领域和评估机器人探测器捕捉在线社交媒体上共存的多种类型的机器人的能力至关重要。
4.2 Seed User Selection
正如第4.1节所详述的,TwiBot-20是通过受控的广度优先搜索从不同的种子用户中扩展得到的。TwiBot-20的目标是准确地代表多样化的Twitter领域,以作为通用的机器人检测的基准,因此搜索算法应该被设计为涵盖不同的用户群体和社区。
政治、商业、娱乐和体育是四个兴趣领域,与每个人的在线参与都有重叠。因此,与之前仅限于特定话题或标签的机器人检测数据集不同,TwiBot-20从这些领域选择了不同的种子用户,以形成当前Twitter领域的代表性集合。具体来说,40个种子用户来自这四个不同的学科。
政治方面。我们选择来自不同意识形态的国家和地方政治家、主要媒体机构和有影响力的政治评论家作为种子用户,例如@SpeakerPelosi
商业。我们选择企业、金融媒体和有影响力的商业评论家作为种子用户,例如:@amazon
娱乐。我们选择知名的艺术家、喜剧演员和视频游戏流媒体作为种子用户,例如:@samsmith
体育。我们从各种类型的体育项目中选择运动员、运动队和体育新闻机构作为种子用户,例如:@StephenCurry30
除了每个领域的大人物外,我们还对在相关推文下发表评论的用户和相关标签的活跃用户进行抽样,作为种子用户,以提供另一种对社区的看法并确保详尽性。所有种子用户的完整列表可在TwiBot-20完整数据集中找到。通过使用大量来自不同兴趣领域的种子用户,我们确保TwiBot-20涵盖多样化的用户,以更好地代表当前的Twitter领域。
4.3 User Information Selection
在确定了TwiBot-20的用户名单后,我们使用Twitter API来检索第3节中定义的所有三个方面的用户信息。具体来说:
为了获得语义信息,我们检索了每个Twitter用户最近的200条推文,以捕捉其最近的活动。我们保留了多语言推文内容的原始形式,保留了表情符号、URL和转发,以便机器人检测器以他们认为合适的方式处理推文文本。
对于属性信息,我们合并了 Twitter API 为每个用户提供的所有属性项。结果,每个用户在 TwiBot-20 中记录了 38 个属性项。
对于邻居信息,我们检索 Twitter 用户的关注和关注者,并在 TwiBot-20 中记录用户之间的关注关系。
现有的机器人检测数据集大多遗漏了邻居信息,仅包含一小部分属性项或用户推文。相比之下,TwiBot-20 包含可直接从 Twitter API 检索的所有用户信息,因此未来的机器人检测器可以利用他们认为合适的任何用户信息,而不受数据集范围的限制。
4.4 Data Annotation Strategy
推特机器人检测中的数据注释特别困难,而且容易产生偏差,因此我们采用了专门的数据注释策略,借鉴以往研究工作的结论,强调可信度。首先,我们总结了以前的文献,并提出了识别机器人用户的一般标准,具体列举如下:
推文中缺乏针对性和原创性;
高度自动化的活动和API使用;
含有外部链接的推文,宣传钓鱼网站或商业活动;
内容相同的重复推文;
含有不相关URL的推文。
在这些标准的指导下,我们在Appen发起了一个众包活动。根据我们的合同,注释者应该是活跃的Twitter用户,并被要求阅读一份指导文件,其中我们解释了机器人的五个特征以及代表性的例子。
然后,TwiBot-20的每个用户被分配到五个注释者,以确定它是否由机器人操作。
为了识别潜在的模棱两可的情况,允许注释者对一个特定的用户报告 "未决定"。
我们还设计了标准问题,其中用户显然是机器人或人类。
我们将这些标准问题与注释中的问题混合起来,以评估注释者的表现。在标准问题上正确率超过80%的注释者被认为是值得信赖的,他们的注释被采纳。结果,众包活动提供了63,816条注释记录,大约需要33天。
尽管我们提供了注释指南,为每个用户分配了五个注释者,并为性能评估设计了标准问题,但众包结果本身并不可靠。我们进一步采取以下步骤来达到 TwiBot-20 中用户的最终注释:
首先,如果一个用户被Twitter验证了,我们认为它是一个真正的用户;
对于剩余的用户,如果五分之四的注释者认为它是机器人或人类,我们会相应地注释用户。
对于其他从众包中得到的相互同意较少的用户,我们使用Twitter的直接信息功能,用自然语言发出简单的问题,从回应的用户那里收集答案,并手动确定他们的注释。
最后,剩下的未决定的用户在我们的研究团队中进行人工审查。为了确保这些不确定的用户的可信度,我们放弃了有争议的案例,只在我们对一个Twitter用户达成共识时才进行注释。
推特机器人检测中的数据注释受到基本假设的严重影响,并受到偏见的影响。我们综合了以前的文献,发起了一个精心设计的众包活动,并遵循一个细致的过程,以达到对一个特定用户的最终注释。第5.4节的进一步分析将进一步证明TwiBot-20注释的可信度。
4.5 Data Release
TwiBot-20 中的用户在第 4.1 节和第 4.2 节中确定。如第 4.3 节所述,从 Twitter API 检索多模式用户信息,第 4.4 节详细介绍了我们如何为 TwiBot-20 创建值得信赖的注释。我们按照以下流程发布这些数据:
我们对标记的用户进行7:2:1的随机划分,以获得TwiBot-20基准的训练、验证和测试集。为了保留密集的图结构和关系形式,我们还提供无监督的用户作为TwiBot-20的支持集;
我们将每个集合中的用户组织成JSON格式,得到四个数据文件:train.json、dev.json、test.json和support.json。对于每个用户,我们提供用户ID来识别用户,以及在第4.3节中收集的他们所有的语义、属性和邻里信息;
我们在 https://github.com/BunsenFeng/TwiBot-20 发布了带有简洁文档的 TwiBot-20。 TwiBot-20 的小样本可直接在 github 存储库中获得,同时也鼓励研究人员下载并使用完整的 TwiBot-20 以促进机器人检测研究。
5 数据分析
在本节中,我们首先对比了不同机器人检测数据集的大小。然后,我们将TwiBot-20的信息完整性和用户多样性与其他基准进行比较。最后我们进行注释分析,以证明TwiBot-20注释的可信度。
5.1 Dataset Size Analysis
社交媒体上的机器人检测专注于解决在线机器人存在的现实问题。为了很好地代表groundtruth的真实用户和 Twitter 机器人,机器人检测数据集的大小应该相当大才能实现这一目的。我们在表 1 中对比了 TwiBot-20 和主要机器人检测数据集的数据集大小。表 1 表明 TwiBot-20 以总共 229,573 名用户领先,大大超过了以前的机器人检测数据集。 TwiBot-20 还提供了一个支持集,其中包括大量无监督用户。该支持集使半监督学习等新趋势能够与机器人检测研究相结合。据我们所知,TwiBot-20 建立了迄今为止最大的机器人检测基准,并且是第一个在机器人检测数据集中提供无监督用户的。
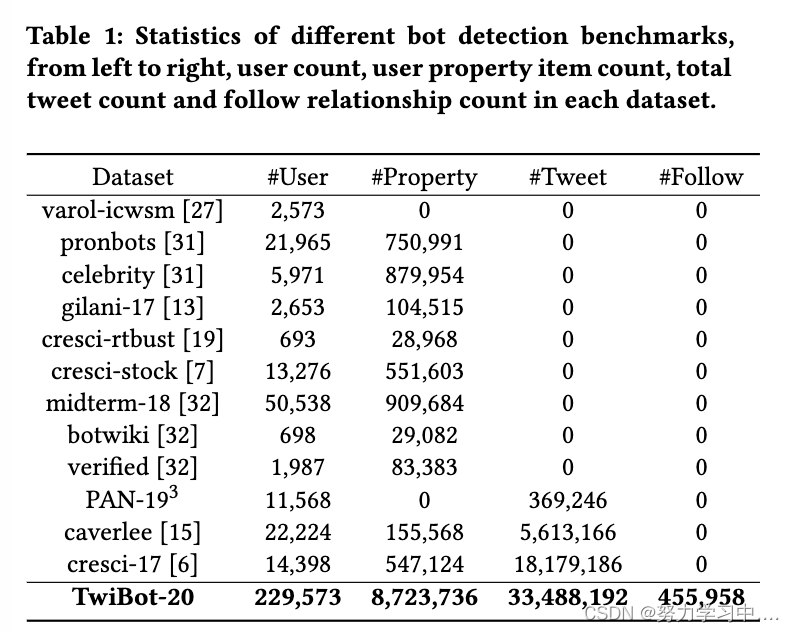
(不同机器人检测基准的统计,从左到右,每个数据集中的用户数、用户属性项数、总推文数和关注关系数。)
5.2 User Information Analysis
在线社交媒体变得越来越复杂,用户每天都会产生大量的多模式数据。 Twitter 机器人也在利用这种信息复杂性来逃避以前的机器人检测措施。Twitter 用户通常会生成大量的多模态数据,因此机器人检测数据集应包含所有三种用户信息模态,以便对用户行为进行全面分析,这可能会提高机器人检测性能和鲁棒性。
我们研究了主要的机器人检测数据集,并在表 2 中描述了它们的用户信息完整性。
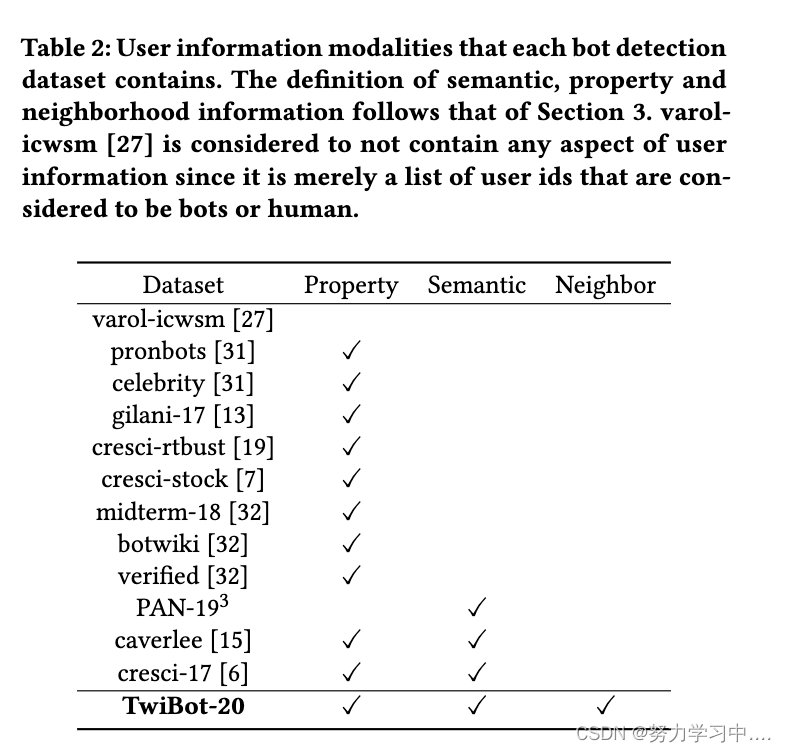
(每个机器人检测数据集包含的用户信息模式。语义、属性和邻域信息的定义遵循第 3 节的定义。 varolicwsm 被认为不包含用户信息的任何方面,因为它只是被认为是机器人或人类的用户 ID 列表.)
表 2 表明 TwiBot-20 包含用户信息的所有三个方面。数据集 cresci-17和 caverlee包含语义和属性信息,而所有其他现有基线仅包括用户语义或属性信息。进一步的探索表明,只有属性信息的数据集通常会遗漏某些属性项,从而在此过程中引入不可避免的偏差。据我们所知,TwiBot-20 是第一个公开可用的包含用户邻域信息的 Twitter 机器人检测基准。 TwiBot-20 的信息完整性使新颖的机器人检测器能够利用尽可能多的用户信息,因为它可以被明确地检索到。
为了进一步探索 TwiBot-20 的用户邻域信息,我们在图 1 中说明了 TwiBot-20 中的一组用户及其关注关系。证明了 TwiBot-20 中的关注关系形成了一个密集的图结构,以实现基于社区的机器人检测措施,例如图神经网络。
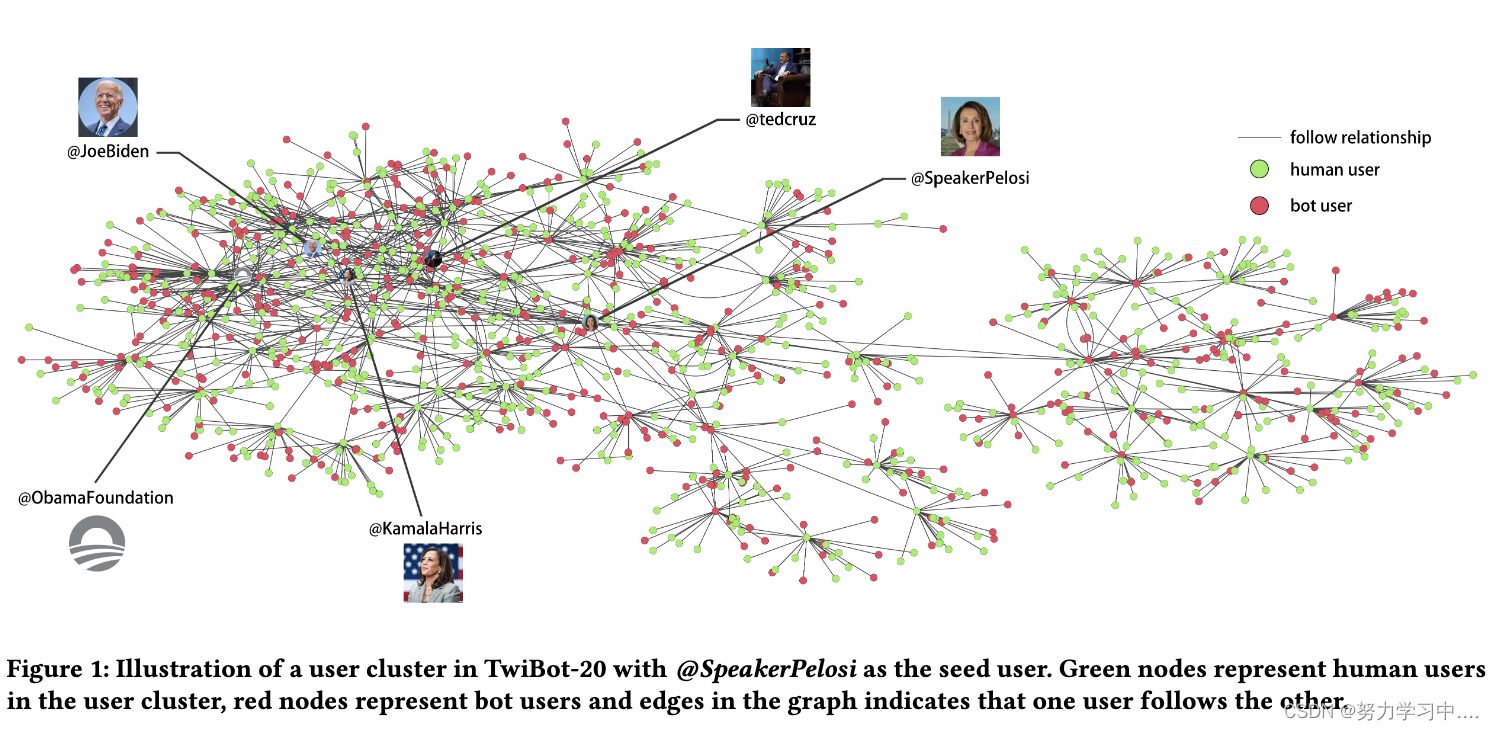
(TwiBot-20 中用户集群的图示,@SpeakerPelosi 作为种子用户。绿色节点代表用户集群中的人类用户,红色节点代表机器人用户,图中的边表示一个用户关注另一个用户。)
5.3 User Diversity Analysis
TwiBot-20 的一个重要目标是准确表示多样化的 Twittersphere 并捕获在社交媒体上共存的不同类型的机器人。我们研究了个人资料和用户兴趣的分布,以检验 TwiBot-20 是否实现了用户多样性的目标。
地理多样性。图 2 说明了 TwiBot-20 中用户的地理位置。虽然使用频率最高的两个国家是印度和美国,但也有相当数量的用户来自欧洲和非洲。
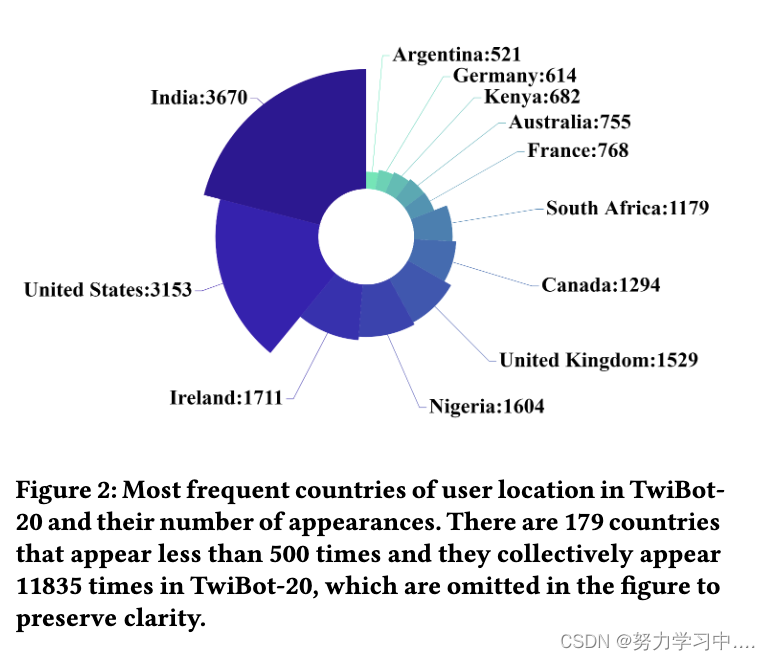
(TwiBot-20 中用户位置最频繁的国家及其出现次数。出现少于 500 次的国家有 179 个,它们在 TwiBot-20 中总共出现了 11835 次,为了清楚起见,图中省略了这些国家)
用户兴趣多样性。 图 3 展示了最常提及的主题标签及其频率。 由于数据收集时的全球健康危机,#COVID-19 标签排名第一。 事实证明,TwiBot-20 捕获了经常使用#Trump 和#RNC2020 发推文的政治用户、使用#SaintsFC 发推文的体育爱好者、使用#business 和#marketing 发推文的商务人士,以及使用#love 和#travel 发推文的普通用户。
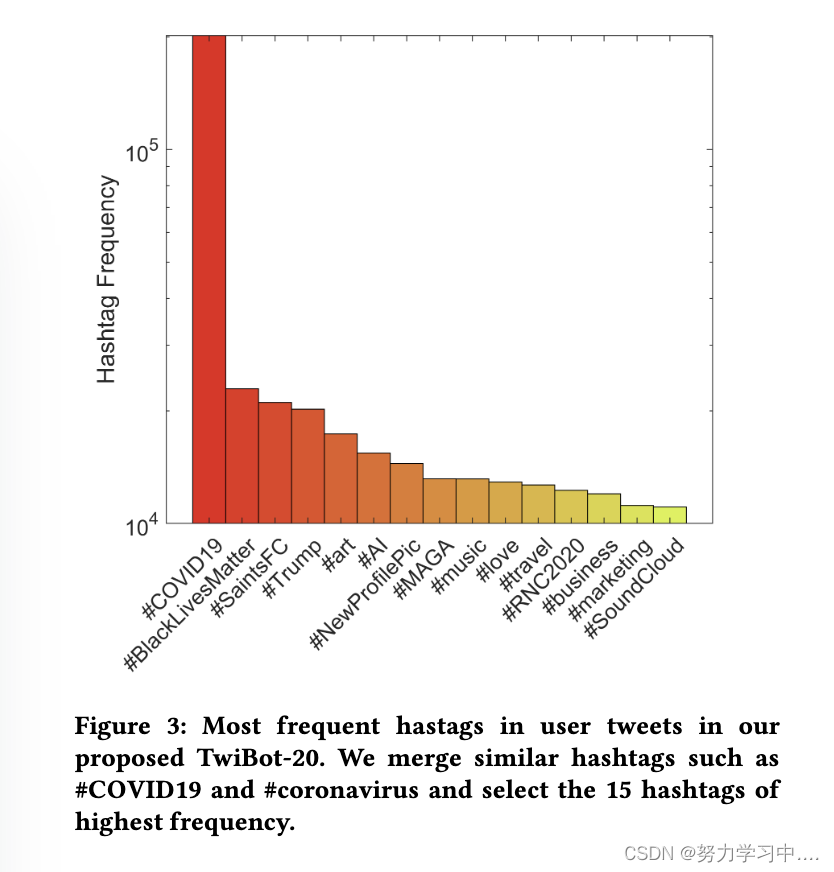
(我们提议的 TwiBot-20 中用户推文中最常见的标签。我们合并类似的标签,例如#COVID19 和#coronavirus,并选择频率最高的 15 个标签)
因此,TwiBot-20 中的 Twitter 用户被证明在地理位置和兴趣领域是多样化的。 TwiBot-20 包含多样化的用户,以更好地代表多样化的 Twitter 圈,而不是特定场景的示例。
5.4 Annotation Quality Analysis
为了证明我们的标注程序能够带来高质量的标注,我们考察了标注结果是否与之前文献中提出的bot特征一致。
帐户信誉。我们探讨了 TwiBot-20 中机器人和真实用户的声誉得分之间的差异。声誉是衡量一个用户的关注者数量和关注数量的系数,定义如下
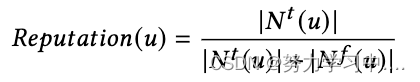
其中 |·| 表示集合的基数,表示用户的follower集合,
表示用户的following集合。
Chu等人观察到,人类用户更倾向于关注 "著名 "或 "有信誉 "的用户。一个名人通常有很多追随者和很少的关注,他的声誉接近于1。相反,对于一个有很少追随者和很多关注的机器人,它的声誉接近于0。图中显示,TwiBot-20中的真实用户比机器人表现出相对较高的声誉得分。TwiBot-20中大约60%的机器人的关注者少于关注,导致他们的声誉低于0.5。TwiBot-20中用户的声誉得分与Chu等人的提议相吻合,这加强了TwiBot-20注释普遍可信的说法。
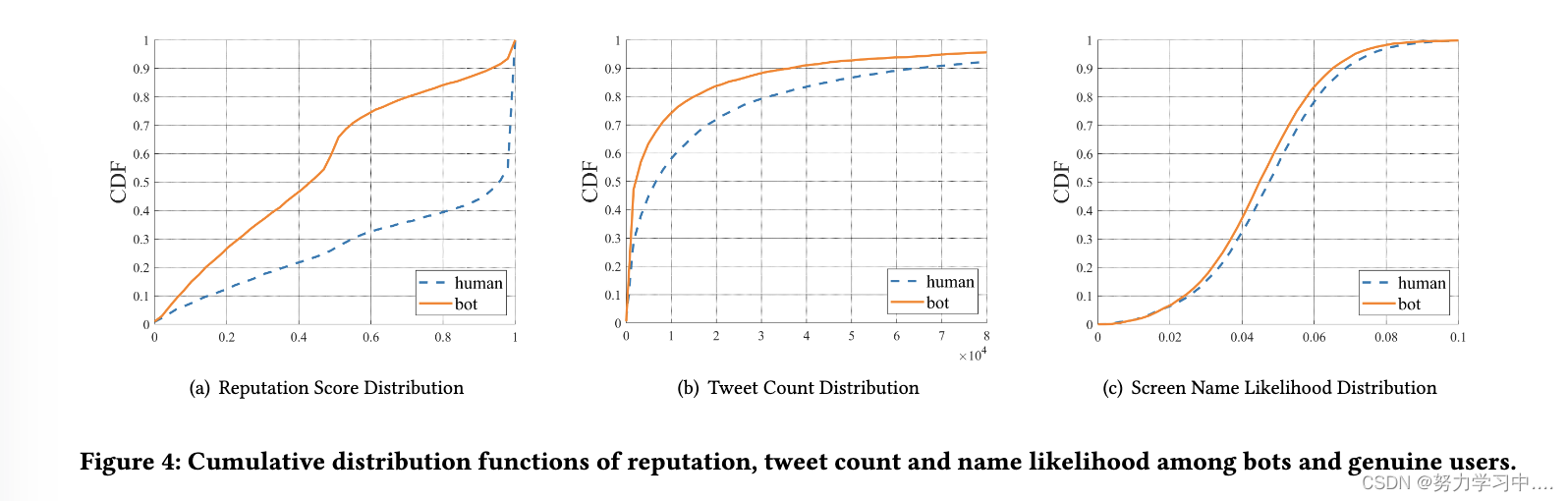
(机器人和真实用户之间的声誉、推文数量和名称可能性的累积分布函数。)
用户推文计数。Perdana等人观察到机器人用户会生成大量重复的推文,从而导致推文总数增加。我们在 TwiBot-20 中探索用户标注与其推文计数之间的关系。图 4(b) 显示了用户推文计数的 CDF。令人惊讶的是,机器人用户生成的推文比人类少。这种与之前工作的差异可能归因于机器人用户已经进化到逃避基于特征工程的机器人检测并且他们现在控制了推文的数量。
为了进一步探索这种差异,我们检查了数据集中的 bot 用户并发现以下事实:bot 用户在特定时间段内更频繁地发推文,并长期休眠以避免被 Twitter 检测到,这通常会导致推文较少。屏幕名称可能性杨等人观察到机器人用户有时会使用随机字符串作为他们的屏幕名称。为了衡量这一特征,他们建议评估用户的网名可能性。 Twitter 仅允许在屏幕名称字段中使用字母(大写和小写)、数字和下划线,限制为 15 个字符。我们使用 TwiBot-20 中的 229,573 个屏幕名称并构建所有 3,969 个可能的二元组的可能性。网名的可能性由其中所有二元组的几何平均可能性定义。对于长度为k的网名X,似然度L(x)定义如下:

其中表示第i个字符X,表示从用户网名中得到二元组
的可能性
图4(c)显示了机器人用户和人类用户在网民可能性方面的差异。结果表明,TwiBot-20中的机器人用户的网名可能性略低,这与Yang等人的研究结果一致。我们检查了一些机器人用户,发现他们确实有随机字符串作为他们的网名,如@Abolfaz54075615。TwiBot-20的数据注释也与Yang等人的观察相吻合,这使TwiBot-20的注释可信度得到了支持。
综上所述,TwiBot-20 的注释通常与之前提出的机器人特征相匹配。
6 实验
在本节中,我们对 TwiBot-20 和其他两个公共数据集进行了广泛的实验和深入分析,以证明所提出基准的新颖性和有效性。
6.1 Experiment Settings
数据集。除了我们提出的基准 TwiBot-20 之外,我们还利用另外两个公开可用的数据集 cresci-17 和 PAN-19 来比较不同基准上的基线性能。
cresci-17 分为真实用户、社交垃圾邮件机器人、传统垃圾邮件机器人和虚假关注。我们将cresci-17作为一个整体使用。就用户信息而言,cresci-17 包含 Twitter 用户的语义和属性信息。
PAN-19是CLEF 2019年PAN研讨会上的一个机器人和性别分析共享任务的数据集。它包含用户语义信息。
这三个数据集的摘要如表 3 所示。对于三个数据集,我们随机进行 7:2:1 分区作为训练、验证和测试集。这样的分区在第 6.2、6.3、6.4 和 6.5 节中的所有实验中共享。

(三个采用的机器人检测数据集的概述。 S、P 和 N 信息分别代表语义、属性和邻域信息)
基线。我们介绍了实验中采用的具有竞争力和最先进的机器人检测方法。
Lee等人。Lee等人使用随机森林分类器与特征工程;
Yang等人。Yang等人使用随机森林与用户元数据和衍生的二级特征;
Kudugunta等人。Kudugunta等人提出使用LSTM和全连接神经网络来共同利用推特语义和用户元数据;
Wei等人。Wei等人使用词嵌入和三层Bi-LSTM对推文进行编码并识别机器人;
Miller等人。Miller等人使用107个特征和改进的流聚类算法进行机器人检测;
Cresci等人。Cresci等人用字符串对用户活动进行编码,并计算出最长的公共子串,以捕获群体中的机器人;
Botometer: Botometer是一个公开的演示,利用一千多个特征来识别Twitter上的机器人;
Alhosseini 等人。 Alhosseini 等人采用图卷积网络进行机器人检测。
评估指标。我们采用准确性、F1-score 和 MCC作为评估指标。准确性是一个直接的指标,而 F1 分数和 MCC 是更平衡的选择。
6.2 Benchmark performance
表 4 报告了不同方法在两个公共数据集 cresci-17、PAN-193 和我们提出的 TwiBot-20 上的机器人检测性能。表 4 表明:
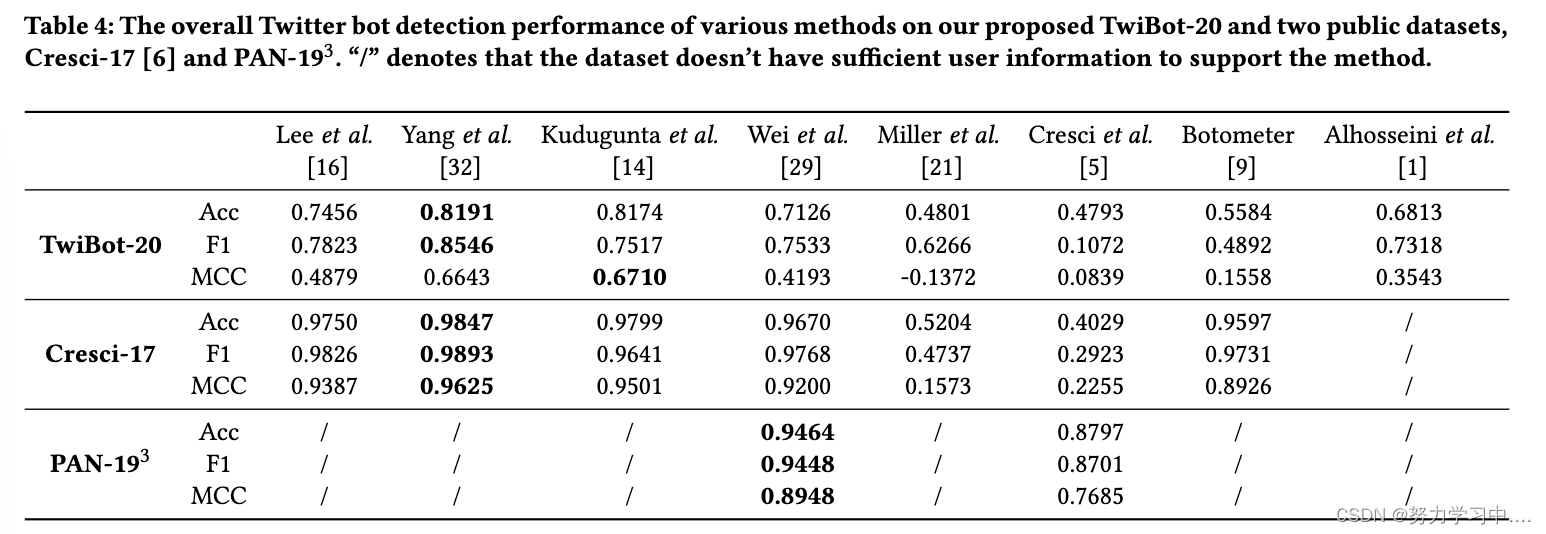
(在我们提出的 TwiBot-20 和两个公共数据集 Cresci-17 和 PAN-19上各种方法的整体 Twitter 机器人检测性能。 “/”表示数据集没有足够的用户信息来支持该方法)
所有机器人检测基线在 TwiBot-20 上的性能明显低于 cresci-17 或 PAN-193。这表明我们的 TwiBot-20 更具挑战性,社交媒体机器人检测仍然是一个悬而未决的问题。
Alhosseini 等人将图卷积网络应用于 Twitter 机器人检测任务,该任务要求机器人检测数据集包含用户邻域信息。正如 Cresci 等人指出,研究用户社区对于未来的机器人检测工作至关重要,其中 TwiBot-20 通过提供用户的邻域信息来实现它,而其他两个数据集则不足。
从 Wei 等人 的比较和 Kudugunta 等人其中两个基线都使用语义信息,但后一种方法也利用用户属性,证明在我们提出的 TwiBot-20 上,两个基线之间的性能差距明显大于在 cresci-17 上。这表明除了作为示例之外,TwiBot-20 相对更复杂,其中机器人检测器需要利用更多用户信息才能表现良好。
Botometer 是一个公开可用的机器人检测演示。尽管它成功地在 cresci-17 中捕获了机器人,数据集中的用户是在 2017 年收集的,但它无法与之前在 TwiBot-20(2020 年收集用户)上的表现相匹配。这表明现实世界的 Twittersphere已经发生了变化,Twitter 机器人已经进化为逃避以前的检测方法,这需要新的研究工作和更新的基准,如 TwiBot-20。
对于基于特征工程的方法,例如 Lee 等人和杨等人它们的性能从 cresci-17 到 TwiBot-20 显着下降。这一趋势表明,未能结合语义和邻域信息会导致在最近的数据集上表现更差。这可以再次归因于 Twitter 机器人的发展,因此未来的机器人检测方法应该利用日益多样化和多模式的用户信息来实现理想的性能。
6.3 Dataset Size Study
TwiBot-20 包含的 Twitter 用户比任何其他已知的机器人检测数据集都多,并且与现有的机器人检测基准相比,涵盖了更多类型的帐户。在本节中,我们分析了扩大规模的好处和更多样化用户的挑战。我们从 Twibot-20 训练集中随机选择不同比例的用户,并在图 5 中比较使用不同数据大小训练的模型性能。
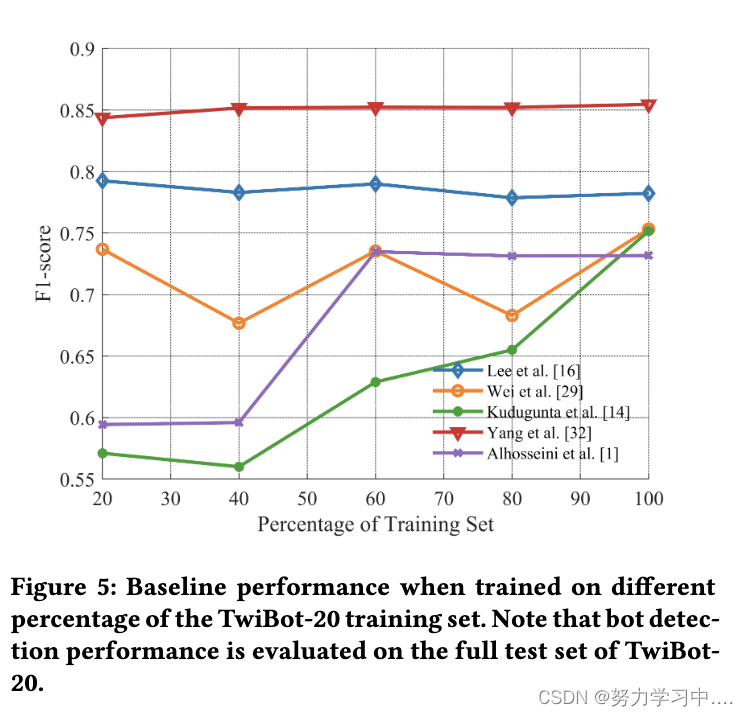
(在不同百分比的 TwiBot-20 训练集上训练时的基线性能。请注意,机器人检测性能是在 TwiBot-20 的完整测试集上评估的)
图 5 表明,即使是在我们提出的 TwiBot-20 的一小部分上进行了训练,也有像 Yang 等人这样的竞争性基线,仍然保持他们的表现。这表明 TwiBot-20 可以充分训练机器人检测器,而其他用户明显较少的数据集无法稳定地对机器人检测方法进行基准测试。
6.4 User Information Study
在计算机视觉和自然语言处理方面提出了要求,因为机器人检测器的输入彼此之间存在很大差异。以前的方法严重依赖推文语义分析或用户配置文件特征提取,而强调跟随行为及其形成的图结构的方法正在兴起。
我们在表 5 中总结了竞争性机器人检测基线及其对多模式用户信息的使用。连同表 4 中的实验结果,我们进行了以下观察:

(每种比较方法所使用的Twitter用户信息的模式在本表中进行了总结。语义、属性和邻域用户信息的定义遵循第三节的问题定义。)
据我们所知,TwiBot-20 是第一个公开可用的 Twitter 机器人检测数据集,提供用户之间的关注关系以允许基于社区的检测措施。通过提供多模态语义、属性和邻域用户信息,TwiBot-20 成功地支持了所有对用户信息有不同需求的基线 bot 检测器,而之前的基准无法支持新的研究工作,例如 Alhosseini 等人。
根据表 5,Kudugunta 等人利用语义和属性信息,而 Wei 等人只使用语义信息。表 4 证明了 Kudugunta 等人优于 Wei 等人, 关于我们提出的 TwiBot-20。在 Alhosseini 等人之间可以找到类似的对比和米勒等人这些性能差距表明,强大的机器人检测方法应尽可能多地利用用户信息。
因此,TwiBot-20 将是满足多模式用户信息需求并公平评估任何以前或未来的机器人检测器的理想数据集。
6.5 User Diversity Study
以前的数据集通常集中在几种特定类型的 Twitter 机器人上,缺乏全面性。我们提出的 TwiBot-20 的另一个重要目标是提供一个稳定的基准来评估机器人检测器识别在线社交媒体上共存的多样化机器人的能力。为了证明在一种类型的机器人上取得良好的性能并不一定表明能够识别多样化的机器人,我们训练了基于社区的机器人检测器 Alhosseini 等人仅在 TwiBot-20 的四个兴趣域之一上,并在完整的测试集上对其进行评估。我们在图 6 中展示了它的性能:
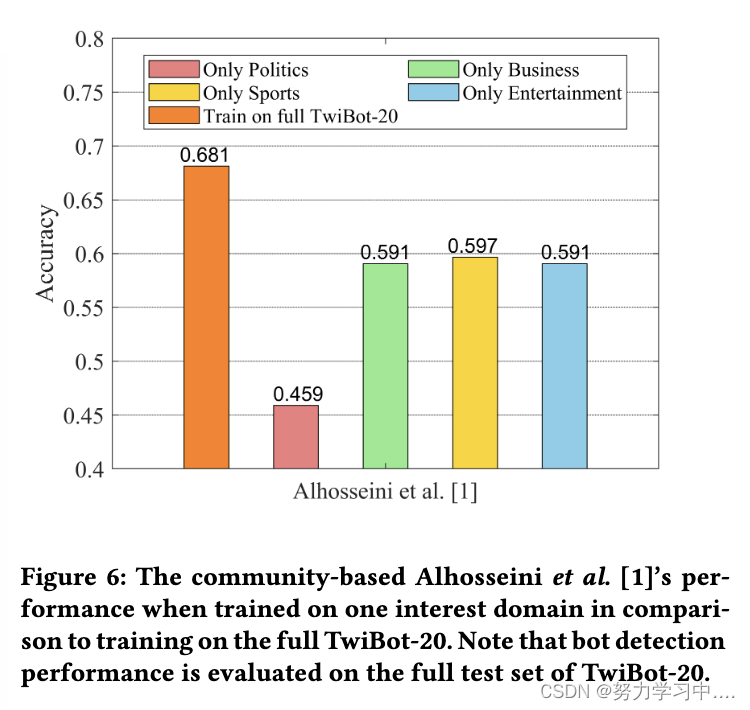
(基于社区的 Alhosseini 等人在一个兴趣领域训练时的表现与在完整 TwiBot-20 上的训练相比。请注意,机器人检测性能是在 TwiBot-20 的完整测试集上评估的。)
图 6 说明了当该方法在用户兴趣领域之一上进行训练时,Alhosseini 等人在完整的 TwiBot-20 上进行训练时,其性能无法匹配。因此,TwiBot-20 可以更好地评估机器人检测措施,因为它包含多样化的机器人和真实用户,这需要机器人检测器共同捕获不同类型的机器人,而不是局限于特定的机器人检测场景。
7 结论和未来的工作
近年来,社交媒体机器人检测吸引了越来越多的研究兴趣。我们收集并注释了 Twitter 数据,以呈现一个全面的 Twitter 机器人检测基准 TwiBot-20,它代表了多样化的 Twitter 领域,并捕获了在主要社交媒体平台上共存的不同类型的机器人。我们将 TwiBot-20 公开,希望它能缓解 Twitter 机器人检测中缺乏综合数据集的问题,并促进进一步的研究。
大量实验表明,最先进的机器人检测器无法与之前报告的 TwiBot-20 性能相匹配,这表明 Twitter 机器人检测仍然是一项具有挑战性的任务,需要不断努力。 未来,我们计划研究新颖的 Twitter 机器人并提出强大的机器人检测器。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









