







摘要
Steemit是一个基于区块链的社交媒体平台,如果作者的帖子被投票,他们可以以加密货币的形式获得作者奖励,这些奖励被称为STEEM和SBD (Steem blockchain Dollars)。
(Sreemit: 您不仅可以通过发布内容获得报酬,还可以通过评论,甚至只是简单的点赞其他帖子获得收益。您在这里可以点赞和点踩,关注您感兴趣的主题,提交内容,并与其他用户讨论帖子。)
有趣的是,策展人 (或投票者) 也可以通过投票他人的帖子来获得奖励,这被称为管理奖励。奖励与策展人的奖金成正比。在整个过程中,Steemit希望 “好” 内容将被用户以分散的方式自动发现,这被称为脑证明 (PoB)。然而,有许多机器人账户被编程为自动发布并获得奖励,这阻碍了真正的人类用户创建好的内容。我们称这种类型的机器人为贴子机器人。
虽然有许多论文研究了传统集中式社交媒体平台 (如Facebook和Twitter) 上的机器人,但我们是第一个研究在基于区块链的社交媒体平台上发布机器人的人。
与通常的社交媒体平台上的机器人检测相比,我们创建的功能具有一个优势,即可以在不限制帖子数量或长度的情况下检测到发布机器人。
我们可以通过对博客数据或回复之间的距离进行聚类来提取帖子的特征。这些功能是从最小平均聚类中获得的,该聚类来自频繁单词和文章之间的聚类距离 (MAC-CDFA),在以前的任何社交媒体研究中都没有使用。基于丰富的功能,我们提高了分类任务的质量。
比较F1-scores,我们创建的功能优于Facebook和Twitter上用于机器人检测的功能。
1 简介
尽管人们对区块链技术感兴趣,但所谓的去中心化应用程序 (DApp) 的使用仍然受到限制。除了转移和交易加密货币外,使用最广泛的应用程序之一是Steemit,1基于区块链的社交媒体平台。根据DApp排名网站,2020年1月排名第2,Steemit长期以来在所有DApp中排名第一,但仍排名第六,大多数排名靠前的dapp都基于Steem区块链 (Steemit 2017),Steemit也在其上运行。
在Steemit上,如果作者的帖子被投票,作者将获得名为STEEM和SBD (Steem Blockchain美元) 的加密货币形式的作者奖励。有趣的是,策展人 (或投票者) 也通过投票他人的帖子获得奖励,这被称为策展奖励。如果用户撰写帖子,则为作者; 如果对帖子进行投票 (包括自己的帖子),则为策展人。奖励与策展人的stems数量成正比,这被称为STEEM POWER。也就是说,来自具有更高STEEM POWER的用户的投票具有更高的价值。每次投票都会消耗投票权,随着时间的流逝,投票权会重新产生。还有一个downvote会减少帖子的奖励,该帖子旨在防止垃圾邮件和任何恶意内容。在整个过程中,Steemit希望用户以分散的方式自动发现 “好” 内容,这被称为大脑证明 (PoB)。
但是,与其他传统社交媒体平台 (例如Facebook和Twitter) 一样,有许多机器人帐户会自动发布。我们称这种类型的机器人为张贴机器人。在Steemit上,对发布机器人的检测可能比其他平台更为关键,因为在Steemit上发布机器人也会获得奖励,这使真正的人类用户无法创建好的内容。由于投票减少,经常发送垃圾邮件的机器人无法在奖励方面生存。因此,posting机器人已经以一种可以编写更有意义的帖子的方式发展,因此看起来像人类帐户。
有许多论文研究了传统社交媒体平台上的机器人。特别是,一些研究发现在Twitter上发布了机器人。Twitter是一个微博网站,用户在该网站上发布名为tweet的消息。一条推文的字符限制为140 (或自2017年11月起为280)。因此,与其他社交媒体平台 (例如Facebook和Steemit) 相比,推文中的文本简短且相对容易进行分析。在Steemit上,对帖子的长度没有限制,但是受到块大小的限制,该块大小目前为64KB。对于大多数社交媒体帖子来说,这已经足够了。在Steemit上检测机器人的另一个复杂问题是,由于区块链的去中心化性质,它具有高度的匿名性。由于其经济回报,相对较长的文本,高度的匿名性,在Steemit上检测发布机器人既重要又具有挑战性。
据我们所知,这项研究是第一个在基于区块链的社交媒体平台上调查发布机器人的研究。与传统社交媒体平台上的机器人检测相比,我们创建的功能具有广告优势,可以在不限制帖子数量和长度的情况下获得它们。我们通过对博客数据或回复之间的距离进行聚类来提取特征。这些功能是从MAC-CDFA (来自频繁单词和文章之间的聚类距离的最小平均聚类) 获得的,以前的任何社交媒体研究中都没有使用过。此功能通过对博客数据之间的距离进行聚类来显示博客数据之间的相似性。基于丰富的特征,我们提高了分类质量。比较F1-scores,我们创建的功能超出了Facebook和Twitter上用于机器人检测的功能。
2 相关工作
随着社交媒体平台的发展,在社交媒体平台上检测机器人已成为一个重要问题 (Allcott和Gentzkow 2017; Ferrara等2016)。许多研究人员已经尝试用机器学习算法来检测机器人 (Abu-El-Rub和Mueen 2019; Chu等人。2012; Clark等人。2016; Dickerson,Kagan和Subrahma- nian 2014; Santia,Mujib和Williams 2019; Varol等人。2017;王2010)。他们专注于提取代表每个帐户行为模式的特征。特别是,代表规律性的特征发挥了重要作用。一些研究人员计算了每个用户发布的文本的相似性,而另一些研究人员则测量了时间间隔的熵以表达行为模式的规律性。在最近的一项研究中,(Li和Palanisamy 2019) 指出了一种不同类型的机器人的流行,用户从该机器人中购买Steemit的选票。这些机器人中的大多数都可以从自己的广告中或通过检查包含要投票的帖子URL的传输备忘录中轻松找到。相比之下,我们的重点是发布机器人。
已经有几次尝试提取文本的规律性,尤其是在Twitter圈(Abu-El-Rub和Mueen 2019; Clark等人。2016; 王2010)。他们使用了一种方法,通过定义两个推文之间的相似性来考虑所有推文对。两个推文之间的相似性在许多方面都被定义了。(王2010) 使用Levenshtein距离确定一条推文是否被另一条推文复制。(Abu- El-Rub和Mueen 2019) 使用每个文本中包含的主题标签的Jaccard索引定义了相似性。(Clark等人2016) 认为两个文本的最长公共序列。但是,Twitter在文本长度上与Steemit有所不同。在这方面,Facebook是与Steemit进行比较的一个很好的例子。Steemit和Facebook的用户都可以写长篇文章。(santiago, Mujib, and Williams 2019)试图用六种功能检测Facebook上的社交机器人,包括基于内容的功能。但是,他们没有提取代表成对文本相似性的特征。相反,他们计算了代表每个帐户词汇表的创新率,并且还用于Twitter数据集 (Clark等人2016)。此外,他们提出了在包含创新率的Facebook数据集上使用的六个功能。
与行为规律性相关的特征也提供了重要信息。(Chu等人2012) 提出了一种在Twitter上自动配合的帐户检测算法,该算法可确保推文时间间隔的熵。他们显示了每种类型帐户的熵分布的差异,他们强调熵度量对于检测自动帐户很重要。此外,(Chavoshi,hamoni和Mueen 2017) 强调,重要的是要考虑时间数据来检测twitter机器人。在这方面,我们根据包括帐户转移在内的各种活动的顺序计算熵。
其他研究试图提取各种类型的特征。(Dickerson,Kagan和Subrahmanian 2014) 使用情感分数通过应用随机森林算法 (使用包括sematic度量在内的多个特征) 来设计社交机器人分类器。从随机森林算法中提取的特征重要性表明,语义度量在检测Twitter上的社交机器人中起着重要作用。(Varol等2017) 提取了六种不同类型的特征: 用户和朋友的元数据,推文内容和情感,网络模式和活动时间序列。他们强调了人类和机器人帐户具有不同的行为模式这一事实,并得出结论,Twitter上的8%-15% 帐户都是社交机器人。
在社交媒体平台上有不同的方法来检测机器人。(Cresci等人2017; Feng等人2017; Lee和Kim 2014) 定义了用于检测社交机器人的不同类型的相似性。(Cresci等人2017) 定义了数字DNA,它是用户行为的序列,并计算了两个序列的相似性。(Lee和Kim 2014) 考虑了用户名的相似性。此外,(Feng等人2017) 定义了用户关系的相似性。两者都将每种相似性应用于分层分类方法。(Chavoshi,hamoni和Mueen 2016) 是一种基于聚类方法检测twitter bot的模型。他们使用了对滞后敏感的哈希技术,并计算了每个用户之间发布时间序列的Pearson相关性。
一些应用的异常检测方法 (Castellini,Poggioni和Sorbi 2017; Minnich等人2017)。(Castellini,Poggioni和Sorbi 2017) 提取特征并将其应用于去噪自动编码器,一种深度学习算法,并且 (Minnich等人2017) 采用了一种集成的异常检测方法。一些研究基于图结构 (Cao等人2012; Wang,Zhang和Gong 2017)。他们的方法是基于随机游走 (Cao等人2012) 或循环信念传播 (Wang,Zhang和Gong 2017)。(Boshmaf等人。2015; El-Mawass,Honeine和Ver- couter 2018; H ö oner等人。2017) 混合机器学习算法与基于图的方法。他们定义了用户 (El-Mawass,Honeine和Vercouter 2018) 之间的相似性,或者使用机器学习方法调整了每个边缘权重 (Boshmaf等人。2015; H ö oner等人。2017)。
3 特征生成
在特征生成部分,我们描述了分类中使用的特征。功能分为四类:
首先,我们开发了CDFA组,该组描述了常用单词和文章之间的距离。
其次,(Santia,Mujib和Williams 2019) 分析了Facebook上的社交机器人。与Twitter不同,人们可以在Facebook上撰写具有无限字符的博客文章,类似于Steemit。因此,我们对 (Santia,Mujib和Williams 2019) 中的功能进行基准测试,并将其称为Santia-2019组。
第三,(Chu等人2012) 使用熵率,垃圾邮件检测和帐户属性将Twitter中的帐户分为人类,机器人,半机器人。但是,某些功能对于检测Steemit上的后置机器人不可用或没有意义。例如,在Steemit上无法使用推特设备或帐户验证功能,并且垃圾邮件检测没有意义,因为在十四个的垃圾邮件发送者中,只有两个似乎是发布机器人,其余十二个是人类。
因此,我们对熵率和来自 (Chu等人2012) 的一些帐户属性进行基准测试,并将它们表示为Chu-2012组。最后,我们在order中添加了更多与区块链相关的功能,以观察区块链与发布机器人之间的关系。我们将它们表示为面向区块链的特征组。在本节中,我们生成四组特征。我们旨在研究我们创建的特征与先前研究 (Chu-2012,Santia-2019) 中的特征之间发布bot检测效果的差异。此外,我们还希望提供具有和不具有面向区块链的功能之间的性能差异。
3.1 CDFA Group
我们引入了称为CDFA组的新功能,以表示给定帐户的单词特征。首先,为了开发新功能,我们引入了一种考虑文章之间相似性的聚类方法。单词频率和文章之间的聚类距离 (CDFA) 是一种将单词数据转换为真实值的方法。我们考虑帐户使用的频繁单词,并确定频繁单词与帐户撰写的文章之间的距离。
对于一个账户写的M篇文章的给定数据,为了提取单词频率,我们将文章拆分为带有空格的单词。令为第j个文章中的单词集,
为文章中使用的所有单词的集合,而
,1 ≤ i ≤ n为W中的单词。此外,对于每篇文章,我们确定是否使用单词
。然后,我们获得出现向量
,1 ≤ j ≤ m,其长度为n,其中每个向量
中的元素表示第j篇文章中的单词出现。我们描述发生向量如下:
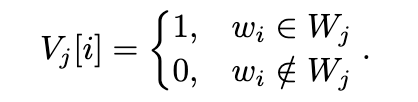
接下来,我们对出现向量进行求和,得到一个总出现向量T。更准确地说,对于T中的每个元素,该值表示出现该单词的文章数.在T中的值中,具有T中的最大值的10% 或更多的出现值的单词被定义为频繁单词F,并且我们获得长度为n的向量,其在频繁单词上的值为1,否则为0:
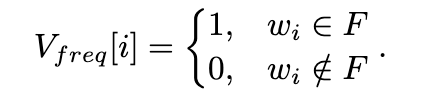















 2165
2165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









