








论文链接: https://arxiv.org/pdf/2402.10426
目录
2.1 Diverse Reaction Generation
摘要
大型语言模型受到事实性和幻觉方面的挑战的限制,无法直接使用现成的方法来判断新闻文章的真实性,而事实准确性是至关重要的。
在这项工作中,作者提出DELL,它确定了错误信息检测的三个关键阶段,其中LLM可以作为管道的一部分纳入其中:1)LLM可以生成新闻反应来代表不同的观点并模拟用户新闻交互网络;
2)LLM可以为代理任务(例如情绪、立场)生成解释,以丰富新闻文章的上下文,并培养专门从事新闻理解各个方面的专家;
3)LLM可以合并特定任务的专家,并通过合并不同专家的预测和置信度得分来提供总体预测。
对三个LLM 的七个数据集进行的广泛实验表明,DELL 在宏观 f1 分数方面比最先进的基线高出 16.8%。
进一步的分析表明,生成的反应和解释对于错误信息检测非常有帮助,而作者提出的LLM引导的专家合并有助于产生更好校准的预测。
1 Introduction
背景:
大型语言模型(LLM)已经表现出令人印象深刻的能力,可以遵循指令(Ouyang et al., 2022)、执行知识密集型任务(Rubin et al., 2022; Shi et al., 2023)和应对社会挑战。然而,LLM也受到幻觉的阻碍(Krysci ́nski et al., 2020; Pagnoni et al., 2021; Dong et al., 2022)、缺乏事实性(Kandpal et al., 2023; Mallen et al., 2022),以及适应新知识的挑战(De Cao 等,2021;Hase 等,2021)。
LLM处理虚假信息的局限性:
尽管做了初步努力,LLM尚不能现成地用于分析新闻文章的真实性,因为事实准确性至关重要(Leite et al., 2023; Hu et al., 2023)。加上大规模产生错误信息的新风险(Chen 和 Shu,2023;Wu 和 Hooi,2023b),这些限制需要新的解决方案来利用LLM来应对在线虚假新闻和错误信息活动。
虽然LLM在直接检测错误信息方面并不可靠,但作者建议 DELL,采用三个关键阶段,其中LLM可以整合起来,为新闻真实性的可靠评估提供更多背景和解释(图 1):

(概述。首先利用LLM从不同的角度产生新闻反应并形成用户新闻互动网络。然后,设计了六个可解释的代理任务,以使用 LLM 生成的解释来细化特征嵌入。最终提出了三种基于 LLM 的策略来选择性地合并特定任务专家的预测并增强校准)
新闻上下文转变为用户新闻交互网络:
社区对新闻文章的反应和评论已被证明可以改善错误信息检测系统(Grover 等人,2022)。然而,收集足够数量的实时用户交互并不总是可行的(He et al., 2023a)。以LLM在模拟人类样本和人群方面的潜力为指导(Argyle et al., 2023),作者利用LLM从不同角度对新闻文章生成综合反应和评论,将新闻上下文转变为丰富的用户新闻交互网络。
LLM来执行代理任务
先前的研究表明,情绪和立场等额外的语用情境以及外部知识有助于错误信息检测(Zhang et al., 2021;Hu et al., 2021;Sengan et al., 2023)。为此,采用LLM来执行代理任务,即预测和解释有助于更好地理解新闻文章的任务。例如,LLM评估新闻文章的情绪并生成预测和解释:然后将这些附加上下文编码为用户新闻交互网络中的初始嵌入,以便基于图神经网络进行分类。通过采用六个专注于新闻文章和产生的反应的代理任务,作者获得了一套专门研究新闻理解各个方面的专门预测器。
合并特定任务的专家并预测新闻的真实性:
最后,使用LLM作为评委,合并特定任务的专家并预测新闻的真实性。由于并非所有专家对给定的新闻文章都同样有帮助/有信心,因此向LLM提供专门从事每个代理任务的专家的预测和置信度分数:然后指示LLM有选择地结合专家的预测以做出总体决策。
通过三个LLM在七个数据集上进行了广泛的实验来评估 DELL 和最先进的基线,这些数据集涵盖与新闻真实性相关的三个任务,包括人工编写和机器生成的错误信息。 DELL 的表现超越了所有数据集的最强基线,宏观 f1 分数提高了高达 16.8%。进一步的分析表明,LLM成的新闻反应和对代理任务的解释对模型性能有很大贡献,而LLM指导的专家合并可以为人类和机器生成的新闻提供更好校准的错误信息检测器。
2 Methodology
提出了三种整合LLM评估新闻真实性的策略:
(i)多样化反应生成,利用LLM从不同角度生成综合新闻反应,形成用户与新闻互动的网络;
(ii)可解释的代理任务,通过LLM生成的任务解释丰富新闻上下文并细化用户新闻交互网络中的节点嵌入;
(iii)基于LLM的专家集成,采用LLM有选择地合并特定任务专家的预测并增强校准。
2.1 Diverse Reaction Generation
前人研究得到的信息:
整合公共话语来评估新闻真实性被广泛应用于更好地报道新闻文章并提供更多背景(Grover et al., 2022; Shen et al., 2022; Wu and Hooi, 2023a; Shovon and Shin, 2023)。
现实数据不足:
然而,现实世界的评论和反应很难收集,而旨在支持错误信息的恶意评论可能会从社交媒体平台上删除,并阻碍可重复的研究(Jung 等人,2020;Grover 等人,2022;He 等人)等,2023a)
LLM优势:
受LLM在模拟人类样本方面的成功(Argyle et al., 2023)和反映不同观点(Sorensen et al., 2023)的启发,建议LLM生成综合评论和反应,模拟来自不同群体的人群如何观点可能会对新闻文章做出反应
多样化的用户属性
首先定义社交媒体用户属性的空间来模拟。
具体来说,每个合成用户都代表七个类别的交集:性别、年龄、种族、教育、家庭收入、政治倾向和选民登记。
形式上,对于用户属性 P i (1 ≤ i ≤ n,n = 7),其候选集为,其中
表示给定属性类别的可能性数量。
对每个用户属性进行统一采样以代表社交媒体用户。然后用语言表达这些属性并将它们连接起来作为合成用户的提示 u
生成用户新闻网络
除了新闻内容之外,新闻评论的非顺序传播结构也有助于评估新闻真实性(Ma et al., 2018;Lu and Li, 2020;Ma et al., 2023a)。形式上,给定一篇新闻文章 s,目标是生成一个用户新闻交互网络 G(V, E),其中 V 和 E 表示节点和边集。为LLM 开发了三种策略来模拟评论传播过程:
(i)生成对新闻文章的评论;
(ii) 生成对给定评论的评论;
(iii) 选择要参与的评论
评论新闻。
首先生成一个综合用户描述 u (§2.1) 并附加以下提示:“您查看了一条包含以下内容的新闻。新闻:s”。然后,LLM 被指示生成代表用户观点的评论,特别是提示“请在社交媒体上对此新闻发表评论”。
评论一条评论。
同样,首先向 LLM 提供用户描述 u 和新闻文章 s。附加一条注释链 ,其中 ci 是对 ci−1 的注释。然后,LLM 被指示对最后一条评论生成一条评论,其中包含“请回复最后一条评论”。
选择一条评论进行评论。
社交媒体用户会选择性地参与某些特定的活动根据他们的观点发表评论。使用LLM通过附加u、s和多个评论链C来模拟这个过程,同时指示LLM“请选择您最想回复的评论链”。
迭代地采用这些提示来为给定的新闻文章生成用户新闻交互网络。附录 A.2 中的算法 1 详细介绍了用户新闻网络生成过程

2.2 Explainable Proxy Tasks
对代理任务使用LLM生成的解释:
事实证明,整合 LLM 生成的有关给定文档的上下文对于分析学术网络等文本属性图是有效的(He 等人,2023b;Chen 等人,2023c;Li 等人,2023a)。
在错误信息检测领域,通常存在许多超出新闻文本本身的隐含上下文,例如作者立场、情绪、外部知识等。
建议对代理任务使用LLM生成的解释,即帮助评估新闻准确性、丰富新闻上下文并使用生成的解释细化用户新闻交互网络的特征嵌入的任务。
具体来说,作者提出了四个代理任务来增强新闻文章:
情绪分析:新闻文章通常具有表明其真实性的情绪信号(Zhang et al., 2021)。采用六种基本情绪(Ekman et al., 1999)(例如愤怒和惊讶)并提示LLM选择三种最可能的情绪并提供解释。
框架检测 框架是政治传播中的一种战略手段(Entman,1993),并且一直是评估新闻真实性的一个组成部分(Kwak 等,2020;Mendelsohn 等,2021)。同样,遵循 14 个媒体框架的分类(Card et al., 2015a)(例如经济),并提示LLM选择五个最有可能的媒体框架并提供解释
宣传策略检测: 宣传策略用于影响人们的心态以推进特定议程(Glowacki 等人)。遵循 19 种宣传策略的分类(Piskorski 等人,2023)(例如,怀疑和转移注意力),并使用LLM来识别新闻文章中的潜在策略并进行解释
知识检索: 检索增强语言模型(Borgeaud et al., 2022; Shi et al., 2023; Asai et al., 2023; Chen et al., 2023b)已经证明了扩大LLM知识获取的巨大潜力。利用LLM通过提示和检索有关这些实体的维基百科段落来识别新闻文章中的关键实体。作者在新闻文章中添加检索到的外部知识,以促进更好的上下文理解
除了新闻内容之外,还提出了两个代理任务来增强生成的评论:
立场检测:给定两个连接的文本节点 s1 和 s2(新闻或评论)在用户新闻交互网络G中,使用LLM来评估s1和s2是支持、中立还是反对,并给出解释。
响应表征:给定 G 中的两个文本节点 s1 和 s2(新闻或评论),使用 LLM 来分析一个文本节点是否响应另一个文本节点。生成的解释将有助于更好地理解新闻和评论的传播结构。
通过使用六个代理任务中的任何一个,获得了LLM生成的解释段落文本,该文本从一个专门的方面分析了新闻文章。
利用LLM生成的解释来细化用户新闻交互网络的特征嵌入。具体来说,首先采用一个单独的基于编码器的 LM enc(·) 对新闻文章 和解释
进行编码,即
,其中使用 DeBERTa (He et al.,2021)在实践中。然后,连接
和
并将其输入线性层以获得初始节点特征
。
采用图神经网络作为下游任务的模型,它在用户新闻网络上进行消息传递。形式上,假设 是节点 vi 在第ℓ GNN 层的表示,特征更新过程为:
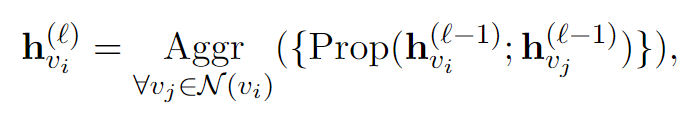
其中N(vi)表示节点vi的邻居集合,Aggr(·)和Prop(·)是聚合和传播函数,其中GIN(Xu等人,2019)在实践中被使用。为了获得 G 的图级表示,采用均值池运算符作为 Readout(·) 函数,即

给定用户新闻网络 G 和标签 y,计算 y 为正确预测的概率为 ,其中 MLP(·) 表示 MLP 层。对于二元分类,使用交叉熵损失优化模型,并预测最合理的标签为 arg max p(y | G)。对于多标签分类,使用 ZLPR (Su et al., 2022) 损失优化模型,并将标签集预测为 {y : p(y | G) > λ},其中 λ 是超参数。
2.3 LLM-Based Expert Ensemble
通过采用不同的代理任务和LLM生成的解释,获得了一组专家,其中每个专家专门研究一个代理任务和新闻文章的各个方面。
为了获得总体预测,提出了一个基于LLM的专家集成,以选择性地利用专家、他们的预测和置信度得分。
首先用一句话来描述每位专家,例如“这位专家关注新闻的情感”。然后提出了LLM合并专家的三种模式
A.4 LLM-Based Expert Ensemble Details
提出了三种基于LLM的方法来选择性地整合每位专家的预测。每个专家
的描述
如下:
W/O专家:这位专家很全面。
情绪:该专家关注此新闻的情绪。
框架:这位专家重点关注该新闻的框架。
宣传策略:该专家重点关注该新闻的宣传策略。
检索:该专家重点关注该新闻的外部知识。
立场:专家重点关注相关评论对此新闻的立场。
关系:该专家重点关注该新闻相关评论的关系。
为了获得置信度得分,采用软最大算子得分进行二元分类,使用绝对值算子进行多标签分类。在表 9 中提供了提示模板。
| Sentiment Analysis | 新闻: s 任务:新闻包含哪些情感?请选择三种最可能的:愤怒、厌恶、恐惧、快乐、悲伤和惊讶。请给出你的推理。 回答: |
| Framing Detection | 新闻:s 任务:框架是政治传播中的一种战略手段和核心概念,用于代表不同的突出方面和观点,以传达问题的潜在含义。该新闻包含哪些框架?请选择最有可能的五个:经济;能力和资源;道德;公平、平等;合法性、合宪性和判例;政策制定和评估;犯罪与惩罚;安全与国防;健康和安全;生活质量;文化认同;在舆论中;政治的;外部监管和声誉。请给出你的推理。 回答: |
| Propaganda Tactics Detection | 新闻:s 任务:宣传策略是宣传中用来说服受众相信宣传者希望他们相信的事情的方法。新闻中包含哪些宣传技巧?请选择五个最有可能的: 对话杀手;主义怎么样?怀疑;稻草人;红鲱鱼;加载语言;诉诸恐惧-偏见;协会有罪;旗帜飘扬;虚假困境——别无选择;重复;吸引人气;向当局提出上诉;名字称呼-标签;口号;诉诸虚伪;夸张-最小化;混淆-模糊-混乱;因果过于简单化。请给出你的推理。 回答: |
| Knowledge Retrieval | 新闻:s 任务:找出上述新闻中的五个命名实体,需要对其进行说明,以便公众全面理解新闻。确保实体的多样化选择。答案应该以Python列表的形式出现。 回答: |
| Stance Detection | 任务:确定句子 2 对句子 1 的立场。是支持、中立还是反对?给出你的推理。 句子 1:s1 句子 2:s2 答案: |
| Response Characterization | 句子 1:s1 句子 2:s2 任务:句子 1 和句子 2 是社交网络上的两个帖子。请判断句子2是否对应句子1。回答是或否并给出理由。 回答: |
首先向普通LLM 新闻内容和说明,即“一些专家对新闻做出预测”。
然后,附加每个专家的描述和预测:对于具有预测 ℓi 及其描述 di 的专家 ei,专家提示为“专家 i:di。专家预测这条新闻的标签是ℓi。”
最后,LLM 根据专家的反馈进行推理并生成最终预测
置信度:
在 Vanilla 中,假设所有专家都应该同等重要。然而,专家可能有不同程度的置信度,通过额外提供置信度分数来考虑这一点。置信度分数是从基于 GNN 的模型的分类层获得的(第 2.2 节)。目标是通过结合个别专家的置信度分数来改进基于LLM的专家集合的校准
选择性
在Vanilla和confidence中,假设每一篇新闻文章都会受益于所有专家的输入。然而,这可能会在LLM推理过程中引入噪音(Zhao et al., 2023; Feng et al., 2023d)。为此,提出选择性方法,由LLM负责选择性激活专家。
具体来说,提供新闻内容和专家描述,然后向LLM提示“要理解这条新闻,你需要哪些专家知识?”将选定的专家与置信策略结合起来以获得最终的预测。
3 Experiment Settings
模型和设置利用 Mistral-7B (Jiang et al., 2023a)、LLaMA2-70B (Touvron et al., 2023) 和 ChatGPT 作为基础 LLM。
主要使用 Mistral-7B 来生成评论并执行代理任务,并使用 ChatGPT 来集成专家,为 Mistral-7B 设置温度 τ = 0.6,为 ChatGPT 设置温度 τ = 0.1。在附录 C 中展示了其他LLM的更多结果。

将 DELL 与三种最先进的基线进行比较:
1) 仅LLM:ZERO-SHOT、FEW-SHOT、检索增强生成、TAPE W/O GRAPH(He 等人,2023b) )和 DEBERTA(He 等人,2021);
2) LLM+Graph:K-HOPS (Huang et al., 2023a) 和 K-ATTENTION (Huang et al., 2023a),以及 TAPE W/ GRAPH (He et al., 2023b);
3)基于图的:GCN(Kipf和Welling,2017)、RVNN(Ma等人,2018)、HYPEHN(Grover等人,2022)、GET(Xu等人,2022)和WSDMS(Yang等人)等,2023b)。
在附录 B.2 中提供了有关基线的更多详细信息。
B.2 Bseline Details
ZERO-SHOT 要求LLM进行检测。
FEW-SHOT 首先向LLM 提供一些新闻实例和标签对,然后要求LLM 进行检测。
检索增强生成首先为LLM提供从维基百科检索到的外部知识,这与知识检索代理任务相同。然后要求LLM进行检测
TAPE W/O GRAPH(He et al., 2023b)专注于利用 LLM 捕获文本信息作为特征,从而增强 GNN 在下游任务上的性能。在这里,仅利用LLM生成的文本信息来增强新闻内容。 DEBERTA(He et al., 2021)利用预先训练的语言模型 DeBERTa 对新闻内容进行编码,然后将其输入 MLP 分类器
K-HOPS(Huang et al., 2023a)将随机选择的邻居合并到提示中,其背后的想法是遵循 GCN 聚合来自邻居节点的信息。 •
K-ATTENTION(Huang et al., 2023a)旨在遵循 GAT,在预测过程中权衡相邻节点的影响。
TAPE W/ GRAPH(He et al., 2023b)将增强的新闻内容放入用户新闻网络中,并利用图神经网络进行检测
GCN(Kipf 和 Welling,2017)采用多个 GNN 层和意义池来获取用户新闻网络表示。
RVNN(Ma et al., 2018)提出了两种递归神经模型策略:自下而上和自上而下的树结构神经网络。作者采用自上而下的结构。
HYPEHN(Grover et al., 2022)是一个话语感知的双曲谱共同关注网络。它是双曲图表示学习与新颖的傅里叶共同注意机制的融合的尝试。
GET(Xu 等人,2022)将主张和相关证据建模为图结构数据,并通过邻域传播捕获分散的相关片段之间的长距离语义依赖性。
WSDMS(Yang et al., 2023b)需要包级标签进行训练,但具有推断句子级错误信息和文章级真实性的能力,这得益于精心与新闻句子语境相关的社交媒体对话。
对于基于 LLM 的基线,提供表 10 中的提示模板。每个基线提示模板包含一个用于描述任务的任务相关提示和一个与基线相关的提示。
| Fake News Detection | 任务:请判断该消息是真是假 |
| Framing Detection | 任务:框架是政治传播中的一种战略手段和核心概念,用于代表不同的突出方面和观点,以传达问题的潜在含义。该新闻包含哪些框架?请选择:特定数据集的候选标签集 |
| Propaganda Tactic Detection | 任务:宣传技巧是宣传中用来说服受众相信宣传者希望他们相信的内容的方法。新闻中包含哪些宣传技巧?请选择:特定数据集的候选标签集 |
| ZERO-SHOT | 任务相关提示 新闻:s 答案: |
| FEW-SHOT | 新闻和标签对示例 任务相关提示 新闻: s 答案: |
| RETRIEVAL | 知识:从维基百科检索到的外部知识 任务相关提示 新闻:s 答案: |
| TAPE | 新闻: s 任务相关提示 提供你的推理。 回答 |
| K-HOPS | 新闻: s 有以下评论: 与新闻相关的评论 任务相关提示 回答 |
| K-ATTENTION | 新闻: s 有以下评论:与该新闻相关的评论 任务:请返回最有助于理解该新闻的评论索引。 回答: |
| 新闻: s 有以下评论: 所选评论 任务相关提示 回答: |
任务和数据集
评估了 DELL 和与描述错误信息相关的三个任务的基线,即
1)假新闻检测:Pheme(Buntain 和 Golbeck,2017)和 LLM-mis(Chen 和 Shu,2023),其特征是二进制分类设置;
2) 框架检测:MFC (Card et al., 2015b) 和 SemEval-23F (Piskorski et al., 2023),具有多标签分类设置;
3)宣传策略检测:由ChatGPT、SemEval-20(Martino et al., 2020)和SemEval-23P(Piskorski et al., 2023)生成,具有多标签分类设置。
在附录 B.1 中提供了更多数据集详细信息:
B.1 Dataset Details
评估 DELL 和与假新闻检测相关的三项任务的基线。
1) 假新闻检测: • Pheme(Buntain 和 Golbeck,2017)是 Twitter 上潜在谣言及其准确性的新闻评估的数据集。
LLM-mis(Chen 和 Shu,2023)是由 LLM 生成的错误信息数据集,具有不同的 LLM 生成器和生成方法。
2)框架检测:
MFC(Card et al., 2015b)包含 1990-2014 年 14 家报纸的 6 期的带标签和未标签文章,尽管有些问题的覆盖范围更广。这些问题包括气候;死刑;枪支控制;移民;同性性行为;和烟草。对标记的文章进行抽样作为基准。
SemEval-23F(Piskorski 等人,2023)旨在从 14 个通用框架池中识别文章中使用的一个或多个框架:安全和防御;公平、平等;政治的;能力和资源;经济的;道德;政策制定和评估;合法性 合宪性和法理;外部监管和声誉;生活质量;健康和安全;文化认同;犯罪与惩罚;及舆论
3)宣传策略检测:
生成: 是 Chat-GPT 生成的基准。首先确定4个主题:俄罗斯和乌克兰;巴勒斯坦和以色列;共和党;和民主党。围绕这些主题,为每个策略生成了 5 个段落.
SemEval-20(Martino 等人,2020)包含 14 种可能的宣传策略:诉诸恐惧-偏见;非黑即白的谬论;辱骂、贴标签;口号;怎么样主义、稻草人、红鲱鱼;夸张、最小化;加载语言;重复;因果过于简单化;追随潮流,希特勒还原论;旗帜飘扬;终结思想的陈词滥调;向当局上诉;和怀疑。该基准将一些策略合并为一类。
SemEval-23F(Piskorski 等人,2023)包含 6 个主要类别: 声誉攻击;理由;简化;分散注意力;称呼;和操纵性措辞。它包含19个宣传策略:对话杀手;虚假困境——别无选择;吸引人气;怀疑;旗帜飘扬;口号;主义怎么样?稻草人;加载语言;名字称呼-标签;混淆-模糊-混乱;诉诸恐惧偏见;因果过于简单化;红鲱鱼;重复;夸张-最小化;向当局提出上诉;协会有罪;以及诉诸虚伪
从每个 benchmark 中随机抽取 1,000 个实例(如果实例少于 1,000 个,则选择全部),并按照 7:2:1 的比例划分训练集、验证集和测试集
4 Results
表 1 列出了 DELL 的性能和最先进的基准。

DELL 实现了最先进的性能。DELL在宏观 f1 分数上比所有七个基准的最强基线高出 1.46% 至 16.80%,这表明将LLM 融入新闻真实性评估的多个阶段是成功的。发现,仅限LLM的情境学习方法在表现上表现不佳,这表明LLM受到事实挑战和评估新闻文章准确性的幻觉的限制。
生成的新闻反应有助于奠定新闻文章的基础。与纯新闻方法相比,通过生成的评论(DELL的和基于图形的基线)增强的模型可以获得更好的性能。注释增强模型在 MFC 上的平均性能比 MaF 上高 15.2%。它表明LLM产生的多样化评论有利于描述错误信息.
代理任务提高了新闻理解能力。 DELL single 表示专注于一项代理任务的最佳单个专家的表现。发现,一个专家就已经可以实现在大多数情况下都有显着的改进:例如,在基准生成上,它的宏观 f1 分数比最强基准提高了 6.16%。这表明可解释代理任务是结合LLM来评估新闻真实性的有效策略.
LLM可以整合专家的预测。与单个专家相比,所提出的LLM集成策略在七个数据集中的六个上取得了改进。除了简单的聚合(Vanilla)之外,“置信度”和“选择性”还通过访问置信度分数并选择性地纳入某些专家来改进集成,这表明LLM具有理解语言化置信度分数的初步能力(Tian等人,2023;Feng)等人,2024)。进一步研究基于 LLM 的集成是否可以导致更好校准的错误信息检测器。
5 Analysis
生成评论的质量验证LLM生成的评论的质量,是否与用户属性匹配以及是否与新闻文章相关。使用四个注释器以五点李克特量表手动评估两个数据集生成的 50 条评论,其中分数越高意味着质量越好。平均得分为 4.52,标准差为 0.69,Fleiss Kappa 中的注释者一致性为 0.216,这表明注释者普遍认为 LLM 生成的评论与用户属性相关且符合品牌。
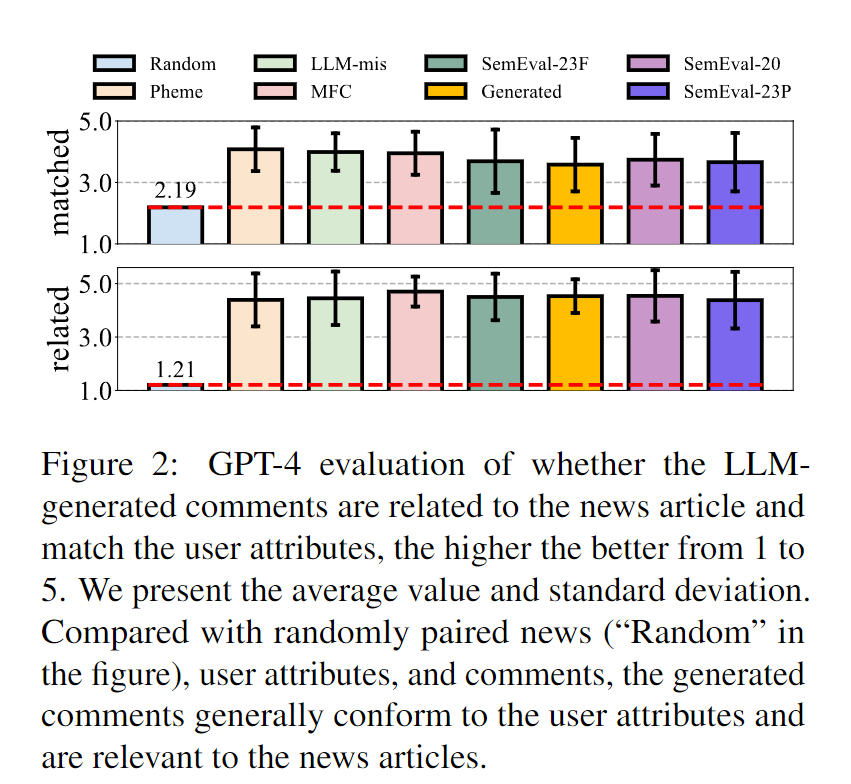
还采用 GPT-4 评估(Chiang and Lee,2023;Kim et al.,2023b)进行定量评估,其中随机抽取 700 条生成的评论,并提示 GPT-4“用户对新闻的评论吗?”与个人资料相符吗?”以及“该评论与新闻相关吗?”征求李克特五点量表的答复。图2表明,自动评估还发现生成的评论与用户属性一致且与新闻相关
模型对评论的鲁棒性由于评论通常很难收集,并且使用 LLM 生成评论的计算成本可能很高,因此检测器应该对评论量具有鲁棒性。在测试集上评估方法,其中LLM生成的注释逐渐被删除。如图 3 所示,由于评论减少,DELL 的性能下降最少,而在数据集 LLM-mis 上,性能几乎没有变化。这表明 DELL 从 10% 的新闻评论中获益匪浅

评论多样性:建议通过使用LLM来模拟不同的用户属性来生成不同的评论。为了验证这种设计选择,仅与合成的共和党或民主党用户重新生成新闻评论,并根据假新闻检测基准评估模型性能。图 4 表明,仅从单一党派观点考虑反应一般来说情况更糟,支持在假新闻检测中整合不同评论的建议。

专家消融:专家专门从事两种类型的代理任务,专注于新闻内容或评论。进行消融研究来检查不同类型代理任务的影响。表2表明:1)整合两类专家会带来更好的绩效,其中单一类别的绩效下降高达15.8%; 2)专注于新闻内容代理任务的专家通常优于仅关注评论的专家,而两种类型的代理任务是互补的

(专家集合的消融研究,仅保留专注于新闻内容或评论的代理任务的专家。展示了每个变体的宏 f1 分数以及与原始设置相比的性能变化。多元化的专家通常优于单一类型的专家,而关注新闻内容的专家通常优于关注评论的专家)















 3308
3308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









