






呵呵,已经七天过去了有种莫名的开心和悲伤。还是快点开始讲今天的内容吧。今天讲了动态规划,简称dp。动
态规划是运筹学的一个分支,是求解决策过程最优化的数学方法。然后我就开始讲dp了。
frist.dp
dp也有许多种类,在下面将一一分述。
1.序列dp:顾名思义,就是在一个给定的序列上进行dp。序列dp大多是线性dp。状态是可以是一维的,也可以是多
维的。本类的状态是基础的基础,大部分的动态规划都要用到它,是众多dp的基础。序列dp的状态有一定的共性一般
有面两点:
1. 状态[i ] 表示前i 个元素决策组成的一个状态。
2.状态[i ] 表示用到了第i 个元素,和其他在1 到i 1 间的元素,决策组成有的一个状态。
然后来补个例题来加深一下印象:
最长上升子序列:很快就能想到O(n平方)的算法:f [i] 表示长度为i 的上升子序列的最小末位元素。f [i] 单调递增,但
必须进行优化。优化的方法如下:f [i] 表示长度为i 的上升子序列的最小末位元素。f [i] 单调递增。利用二分查找优化到
O(nlogn)。
2.背包问题:
这也是dp的一大类,初次看题是非常容易把它看成是一道贪心。
1.01背包:
这类背包只有两个选择0或1,即选或不选。所以可以简单的列出状态转移方程:
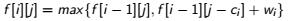
但还可以进行空间复杂度的优化,
第i次状态只与i-1 有关
f [j] 表示容量为j 的背包可以获得的最大值。
倒序求解,为保证状态f [i][j] 可以取到f [i-1][j-ci ]。
2.完全背包:
在这里如果使用01背包的做法,时间复杂度就会大的不可估量,所以我们要去找一个更简单的方法。
01背包倒叙计算是为保证每种物品只能取一次,而完全背包的特点恰是每种物品可选无限件。
顺序求解,在考虑“加选一件第i 种物品”这种策略时,正需要一个可能已选入第i 种物品的子结果f [i][j-ci ]。
这样的算法可以将时间复杂度降到O(NV)。
3.多重背包:
解法与完全背包类似。
略微调整,注意对于第i 种物品有mi + 1 种策略。枚举第i 件物品的件数k。
f [i][j] = max{f [i-1][j -k*ci ] + k*wi } (0<=k<=ni );
还可以做二进制优化,转化为01背包问题,代码如下:

4.乱七八糟背包问题
考虑到01背包和完全背包的代码只有一处不同,故如果只有两类物品:一类物品只能取一次,另一类物品
可以取无限次,那么只需在对每个物品应用转移方程时,根据物品的类别选用顺序或逆序的循环即可,复
杂度是O(NV )。
再加上多重背包,二进制拆分后转化为01背包即可。
背包问题就这样多,就不再多讲了
3.区间dp
区间包括数轴区间和多维区间,这里只讲前者。
区间dp也具有一定的共性:
f [l][r ] 表示一段连续区间[l; r ] 上的答案
1.序列: 区间[l; r ] 的最后一步处理的是k 元素/ 分割点是k / 受k控制的,常用四边形不等式优化。
2. 环: 复制一下粘到后面,枚举断点。
3.点集回路: 利用线段不交的性质按顺序dp。
题就不多说,自己去写吧。
4.状压dp
状压dp是二进制压位的方法把状态简化,用位运算加速dp。
数据特殊性: 给出的数据在某一个或几个维度上一般具有比较小的范围(可以枚举一类的状态),但是无法用
该范围的数值刻画全部状态。
状态: 选/不选。
这种dp有非常多的优化方法。多到我都有些不想讲。所以就只看看,不细讲了。
减少状态总数
跳过无用状态
变量相互制约
减少状态转移数
预处理/前缀和
部分和优化
四边形不等式
决策单调性
数据结构优化
内存优化
滚动数组
减少状态总数
dp到这里就结束了,有些难,还得好好思考。
END.















 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









