







文章目录
一、安装 JDK(两种安装方式)
1、yum安装方式
1.1 查看JDK版本,找到你想要安装的JDK版本,这里以 JDK1.8 为例
yum -y list java*
1.2 安装JDK1.8
出现Complete!安装完成。
yum install -y java-1.8.0-openjdk.x86_64
1.3 查看JDK版本
java -version
默认安装到 usr/lib/jvm 目录下
2、手动安装
2.1 检查当前安装环境
java -version
2.2 检测系统JDK默认安装包:
rpm -qa | grep java
2.3 卸载OpenJDK
yum remove *openjdk*
2.4 安装jdk
官网下载:https://www.oracle.com/cn/java/technologies/downloads/#java8
下载完成后重命名文件名为 jdk-1.8.tar.gz
然后上传到linux
#查看当前文件夹下的所有文件
ls -l

#在当前文件夹创建一个目录 jdk-1.8
mkdir jdk-1.8
#解压tar包,到新创建的目录下
tar -zxvf jdk-1.8.tar.gz --strip-components 1 -C ./jdk-1.8
#在/usr/local创建java目录
mkdir /usr/local/java
#将解压后的文件移动到指定目录下存放
mv jdk-1.8 /usr/local/java/jdk-1.8
2.5 配置环境变量,方法(二选一)
2.5.1 未配置过jdk,自动追加
#如果在未配置过jdk的服务器上可使用该方法
tee -a /etc/profile <<-'EOF'
export JAVA_HOME=/usr/local/java/jdk-1.8
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
EOF
#修改完后, 重新载入配置文件
source /etc/profile
#检查新安装的jdk
java -version
2.5.2 已配置过jdk,手动修改
#如果已经配置过jdk的服务器,则使用该方法手动修改
vi /etc/profile
/export JAVA_HOME
#手动修改相关的内容,输入 i ,在文件末修改如下内容,如果无则可以使用上面的方法
export JAVA_HOME=/usr/local/java/jdk-1.8
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#修改完后,输入 :wq 保存并退出
#然后重新载入配置文件
source /etc/profile
#检查新安装的jdk
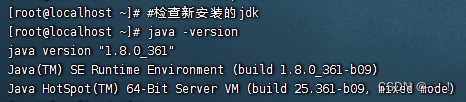
java -version
显示如下内容,恭喜你安装成功
二、安装 MySQL
1、 安装命令
① 执行如下命令,进行 MySQL 的安装。
## ① 安装 MySQL 5.7 版本的软件源 https://dev.mysql.com/downloads/repo/yum/
rpm -Uvh https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm
## ② 安装 MySQL Server 5.7 版本
yum install mysql-server --nogpgcheck
## ③ 查看 MySQL 的安装版本。结果是 mysqld Ver 5.7.37 for Linux on x86_64 (MySQL Community Server (GPL))
mysqld --version
② 修改 /etc/my.cnf 文件,在文末加上 lower_case_table_names=1 和 validate_password=off 配置,执行 systemctl restart mysqld 命令重启。
③ 执行 grep password /var/log/mysqld.log 命令,获得 MySQL 临时密码。
④ 执行如下命令,修改 MySQL 的密码,设置允许远程连接。
## ① 连接 MySQL Server 服务,并输入临时密码
mysql -uroot -p
## ② 修改密码,123456 可改成你想要的密码
alter user 'root'@'localhost' identified by '123456';
## ③ 设置允许远程连接
use mysql;
update user set host = '%' where user = 'root';
FLUSH PRIVILEGES;
三、安装 Redis
1、 安装命令
## ① 安装 remi 软件源
yum install http://rpms.famillecollet.com/enterprise/remi-release-7.rpm
## ② 安装最新 Redis 版本。如果想要安装指定版本,可使用 yum --enablerepo=remi install redis-6.0.6 -y 命令
yum --enablerepo=remi install redis
## ③ 查看 Redis 的安装版本。结果是 Redis server v=6.2.6 sha=00000000:0 malloc=jemalloc-5.1.0 bits=64 build=4ab9a06393930489
redis-server --version
## ④ 启动 Redis 服务
systemctl restart redis
2、 Redis重启数据丢失解决
安装的目录:/usr/local/redis
2.1 修改 redis.conf 配置文件
requirepass 123456
# 默认redis不是以后台进程的方式启动,如果需要在后台运行,需要将这个值设置成yes
# 默认no,改为yes意为以守护进程方式启动,可后台运行,除非kill进程,改为yes会使配置文件方式启动redis失败
# 以后台方式启动的时候,redis会写入默认的进程文件/var/run/redis.pid
daemonize no
# 默认yes,开启保护模式,限制为本地访问
protected-mode no
# redis启动的进程路径
pidfile /var/run/redis.pid
# 启动进程端口号,默认6379,可以改
port 6379
tcp-backlog 511
# 配置redis监听到的ip地址,可以是一个也可以多个
#bind 127.0.0.1 119.23.49.155
# redis的sock路径
unixsocket /tmp/redis.sock
unixsocketperm 755
# 超时时间
timeout 0
#指定TCP连接是否为长连接,"侦探"信号有server端维护。默认为0.表示禁用
tcp-keepalive 0
# 日志级别,log 等级分为4 级,debug,verbose,notice, 和warning。生产环境下一般开启notice
loglevel notice
# 日志文件地址
logfile "/usr/local/redis/logs/redis.log"
#logfile ""
# 设置数据库的个数,可以使用SELECT 命令来切换数据库。默认使用的数据库是0号库。默认16个库
databases 16
# RDB方式的持久化是通过快照(snapshotting)完成的,当符合一定条件时Redis会自动将内存中的所有数据进行快照并存储在硬盘上。进行快照的条件可以由用户在配置文件中自定义,由两个参数构成:时间和改动的键的个数。当在指定的时间内被更改的键的个数大于指定的数值时就会进行快照。RDB是Redis默认采用的持久化方式,在配置文件中已经预置了3个条件:
save 900 1 # 900秒内有至少1个键被更改则进行快照
save 300 10 # 300秒内有至少10个键被更改则进行快照
save 60 10000 # 60秒内有至少10000个键被更改则进行快照
# 持久化数据存储目录
dir /usr/local/redis/data
# 当持久化出现错误时,是否依然继续进行工作,是否终止所有的客户端write请求。默认设置"yes"表示终止,一旦snapshot数据保存故障,那么此server为只读服务。如果为"no",那么此次snapshot将失败,但下一次snapshot不会受到影响,不过如果出现故障,数据只能恢复到"最近一个成功点"
stop-writes-on-bgsave-error no
# 在进行数据镜像备份时,是否启用rdb文件压缩手段,默认为yes。压缩可能需要额外的cpu开支,不过这能够有效的减小rdb文件的大,有利于存储/备份/传输/数据恢复
rdbcompression yes
# checksum文件检测,读取写入的时候rdb文件checksum,会损失一些性能
rdbchecksum yes
#镜像备份文件的文件名,默认为dump.rdb
dbfilename dump.rdb
#当主master服务器挂机或主从复制在进行时,是否依然可以允许客户访问可能过期的数据。在"yes"情况下,slave继续向客户端提供只读服务,有可能此时的数据已经过期;在"no"情况下,任何向此server发送的数据请求服务(包括客户端和此server的slave)都将被告知"error"
slave-serve-stale-data yes
# 如果是slave库,只允许只读,不允许修改
slave-read-only yes
# slave与master的连接,是否禁用TCPnodelay选项。"yes"表示禁用,那么socket通讯中数据将会以packet方式发送(packet大小受到socket buffer限制)。可以提高socket通讯的效率(tcp交互次数),但是小数据将会被buffer,不会被立即发送,对于接受者可能存在延迟。"no"表示开启tcp nodelay选项,任何数据都会被立即发送,及时性较好,但是效率较低,建议设为no,在高并发或者主从有大量操作的情况下,设置为yes
repl-disable-tcp-nodelay no
# 适用Sentinel模块(unstable,M-S集群管理和监控),需要额外的配置文件支持。slave的权重值,默认100.当master失效后,Sentinel将会从slave列表中找到权重值最低(>0)的slave,并提升为master。如果权重值为0,表示此slave为"观察者",不参与master选举
slave-priority 100
# 限制同时连接的客户数量。当连接数超过这个值时,redis 将不再接收其他连接请求,客户端尝试连接时将收到error 信息。默认为10000,要考虑系统文件描述符限制,不宜过大,浪费文件描述符,具体多少根据具体情况而定
maxclients 10000
# redis-cache所能使用的最大内存(bytes),默认为0,表示"无限制",最终由OS物理内存大小决定(如果物理内存不足,有可能会使用swap)。此值尽量不要超过机器的物理内存尺寸,从性能和实施的角度考虑,可以为物理内存3/4。此配置需要和"maxmemory-policy"配合使用,当redis中内存数据达到maxmemory时,触发"清除策略"。在"内存不足"时,任何write操作(比如set,lpush等)都会触发"清除策略"的执行。在实际环境中,建议redis的所有物理机器的硬件配置保持一致(内存一致),同时确保master/slave中"maxmemory""policy"配置一致。
maxmemory 0
# 内存过期策略,内存不足"时,数据清除策略,默认为"volatile-lru"。
# volatile-lru ->对"过期集合"中的数据采取LRU(近期最少使用)算法.如果对key使用"expire"指令指定了过期时间,那么此key将会被添加到"过期集合"中。将已经过期/LRU的数据优先移除.如果"过期集合"中全部移除仍不能满足内存需求,将OOM.
# allkeys-lru ->对所有的数据,采用LRU算法
# volatile-random ->对"过期集合"中的数据采取"随即选取"算法,并移除选中的K-V,直到"内存足够"为止. 如果如果"过期集合"中全部移除全部移除仍不能满足,将OOM
# allkeys-random ->对所有的数据,采取"随机选取"算法,并移除选中的K-V,直到"内存足够"为止
# volatile-ttl ->对"过期集合"中的数据采取TTL算法(最小存活时间),移除即将过期的数据.
# noeviction ->不做任何干扰操作,直接返回OOM异常
# 另外,如果数据的过期不会对"应用系统"带来异常,且系统中write操作比较密集,建议采取"allkeys-lru"
maxmemory-policy volatile-lru
# 默认值5,上面LRU和最小TTL策略并非严谨的策略,而是大约估算的方式,因此可以选择取样值以便检查
maxmemory-samples 5
# 默认情况下,redis 会在后台异步的把数据库镜像备份到磁盘,但是该备份是非常耗时的,而且备份也不能很频繁。所以redis 提供了另外一种更加高效的数据库备份及灾难恢复方式。开启append only 模式之后,redis 会把所接收到的每一次写操作请求都追加到appendonly.aof 文件中,当redis 重新启动时,会从该文件恢复出之前的状态。但是这样会造成appendonly.aof 文件过大,所以redis 还支持了BGREWRITEAOF 指令,对appendonly.aof 进行重新整理。如果不经常进行数据迁移操作,推荐生产环境下的做法为关闭镜像,开启appendonly.aof,同时可以选择在访问较少的时间每天对appendonly.aof 进行重写一次。
# 另外,对master机器,主要负责写,建议使用AOF,对于slave,主要负责读,挑选出1-2台开启AOF,其余的建议关闭
appendonly yes
# aof文件名字,默认为appendonly.aof
appendfilename "appendonly.aof"
# 设置对appendonly.aof 文件进行同步的频率。always表示每次有写操作都进行同步,everysec 表示对写操作进行累积,每秒同步一次。no不主动fsync,由OS自己来完成。这个需要根据实际业务场景进行配置
appendfsync everysec
# 在aof rewrite期间,是否对aof新记录的append暂缓使用文件同步策略,主要考虑磁盘IO开支和请求阻塞时间。默认为no,表示"不暂缓",新的aof记录仍然会被立即同步
no-appendfsync-on-rewrite no
# 当Aof log增长超过指定比例时,重写logfile,设置为0表示不自动重写Aof 日志,重写是为了使aof体积保持最小,而确保保存最完整的数据。
auto-aof-rewrite-percentage 100
# 触发aof rewrite的最小文件尺寸
auto-aof-rewrite-min-size 64mb
# lua脚本执行的最大时间,单位毫秒
lua-time-limit 5000
# 慢日志记录,单位微妙,10000就是10毫秒值,如果操作时间超过此值,将会把command信息"记录"起来.(内存,非文件)。其中"操作时间"不包括网络IO开支,只包括请求达到server后进行"内存实施"的时间."0"表示记录全部操作
slowlog-log-slower-than 10000
# "慢操作日志"保留的最大条数,"记录"将会被队列化,如果超过了此长度,旧记录将会被移除。可以通过"SLOWLOG<subcommand> args"查看慢记录的信息(SLOWLOG get 10,SLOWLOG reset)
slowlog-max-len 128
notify-keyspace-events ""
# hash类型的数据结构在编码上可以使用ziplist和hashtable。ziplist的特点就是文件存储(以及内存存储)所需的空间较小,在内容较小时,性能和hashtable几乎一样.因此redis对hash类型默认采取ziplist。如果hash中条目的条目个数或者value长度达到阀值,将会被重构为hashtable。
# 这个参数指的是ziplist中允许存储的最大条目个数,,默认为512,建议为128
hash-max-ziplist-entries 512
# ziplist中允许条目value值最大字节数,默认为64,建议为1024
hash-max-ziplist-value 64
# 同上
list-max-ziplist-entries 512
list-max-ziplist-value 64
# intset中允许保存的最大条目个数,如果达到阀值,intset将会被重构为hashtable
set-max-intset-entries 512
# zset为有序集合,有2中编码类型:ziplist,skiplist。因为"排序"将会消耗额外的性能,当zset中数据较多时,将会被重构为skiplist。
zset-max-ziplist-entries 128
# zset中允许条目value值最大字节数,默认为64,建议为1024
zset-max-ziplist-value 64
# 是否开启顶层数据结构的rehash功能,如果内存允许,请开启。rehash能够很大程度上提高K-V存取的效率
activerehashing yes
# 客户端buffer控制。在客户端与server进行的交互中,每个连接都会与一个buffer关联,此buffer用来队列化等待被client接受的响应信息。如果client不能及时的消费响应信息,那么buffer将会被不断积压而给server带来内存压力.如果buffer中积压的数据达到阀值,将会导致连接被关闭,buffer被移除。
# buffer控制类型包括:normal -> 普通连接;slave->与slave之间的连接;pubsub ->pub/sub类型连接,此类型的连接,往往会产生此种问题;因为pub端会密集的发布消息,但是sub端可能消费不足.指令格式:client-output-buffer-limit <class> <hard><soft><seconds>",其中hard表示buffer最大值,一旦达到阀值将立即关闭连接;soft表示"容忍值",它和seconds配合,如果buffer值超过soft且持续时间达到了seconds,也将立即关闭连接,如果超过了soft但是在seconds之后,buffer数据小于了soft,连接将会被保留.其中hard和soft都设置为0,则表示禁用buffer控制.通常hard值大于soft.
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
# Redis server执行后台任务的频率,默认为10,此值越大表示redis对"间歇性task"的执行次数越频繁(次数/秒)。"间歇性task"包括"过期集合"检测、关闭"空闲超时"的连接等,此值必须大于0且小于500。此值过小就意味着更多的cpu周期消耗,后台task被轮询的次数更频繁。此值过大意味着"内存敏感"性较差。建议采用默认值。
hz 10
# 当一个child在重写AOF文件的时候,如果aof-rewrite-incremental-fsync值为yes生效,那么这个文件会以每次32M数据的来被同步,这大量新增提交到磁盘是有用的,并且能避免高峰延迟。
aof-rewrite-incremental-fsync yes
2.2 编辑 /etc/sysctl.conf 配置文件
添加 vm.overcommit_memory=1,然后 sysctl -p 使配置文件生效。
四、安装 Nginx
1、安装命令
# 添加 yum 源
yum install epel-release
yum update
## 安装 nginx
yum install nginx
## 启动 nginx
nginx
Nginx 默认配置文件是 /etc/nginx/nginx.conf
2、Nginx 配置(结合芋道SpringBoo反向代理)
2.1 方式一:服务器 IP 访问
① 修改 Nginx 配置,内容如下:
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/doc/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 4096;
include /etc/nginx/mime.types;
default_type application/octet-stream;
include /etc/nginx/conf.d/*.conf;
server {
listen 80;
listen [::]:80;
server_name _;
include /etc/nginx/default.d/*.conf;
location / { ## 前端项目
root /usr/share/nginx/html/yudao-ui-admin;
index index.html index.htm;
try_files $uri $uri/ /index.html;
}
location /admin-api/ { ## 后端项目 - 管理后台
proxy_pass http://localhost:48080/admin-api/; ## 重要!!!proxy_pass 需要设置为后端项目所在服务器的 IP
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
location /app-api/ { ## 后端项目 - 用户 App
proxy_pass http://localhost:48080/app-api/; ## 重要!!!proxy_pass 需要设置为后端项目所在服务器的 IP
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
error_page 404 /404.html;
location = /404.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
}
② 执行 nginx -s reload 命令,重新加载 Nginx 配置。
③ 结合芋道,前端项目修改地址:
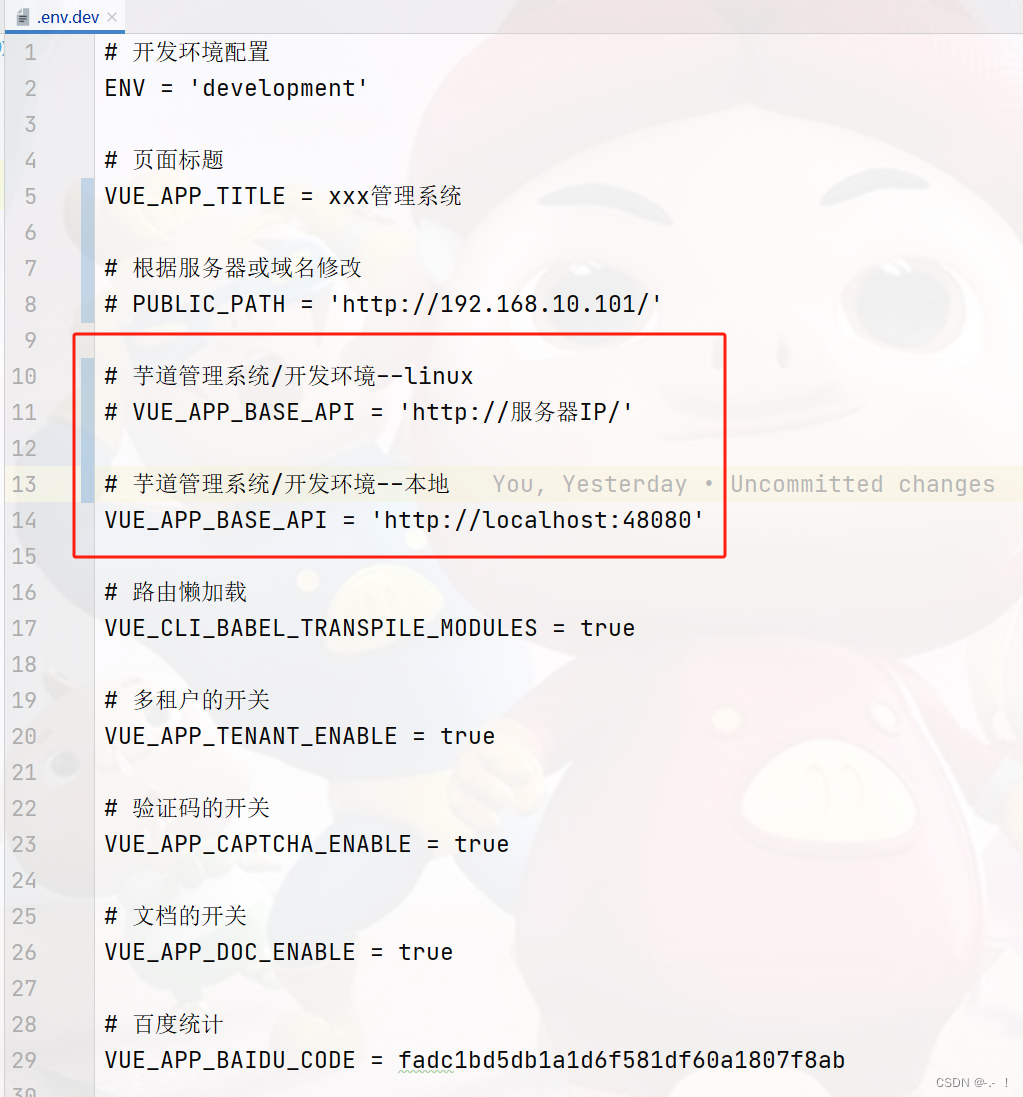
④ 执行 npm run build:dev 命令,编译前端项目,构建出它的 dist 文件
前端项目 dist 下的文件放在这 /usr/share/nginx/html/yudao-ui-admin 目录下
2.2 方式二:独立域名访问
暂无
2.3 Nginx 常用命令
# 开机自启动nginx
systemctl enable nginx.service
# 状态
systemctl status nginx
# 查看端口80占用情况
netstat -anp | grep 80
# 查看占用的程序
ps -ef|grep nginx
# 启动nginx
sudo systemctl start nginx
# 停止nginx
sudo systemctl stop nginx
# 重启nginx
sudo systemctl restart nginx
# 重载nginx配置文件
nginx -s reload
2.3 启动 yudao 后端服务命令
// yudao-server 目录下
cd /work/projects/yudao-server
// 前台运行,关闭xshell窗口程序就停止
java -jar yudao-server.jar
// 后台运行,关闭xshell窗口程序依然运行(推荐)
nohup java -jar yudao-server.jar &
// 修改后端项目的jar配置文件
vim yudao-server.jar
find / -name nohup.out
// nohup.out路径,日志路径
cd /work/projects/yudao-server/nohup.out
五、防火墙相关命令
// 状态
systemctl status firewalld
// 开启
systemctl start firewalld
// 关闭
systemctl stop firewald
// 重启防火墙
firewall-cmd --reload
// 查看所有端口
firewall-cmd --zone=public --list-ports
// 查看某个端口号
firewall-cmd --query-port=6379/tcp
// 开放防火墙6379端口
firewall-cmd --zone=public --add-port=6379/tcp --permanent
// 永久开启防火墙
systemctl enable firewald
// 永久关闭防火墙
systemctl disable firewald
六、端口占用解决
查看一下端口占用情况
netstat -anp | grep 6379
查redis进程
ps -ef|grep redis
杀进程
kill -9 xxx
七、nohup 启动 jar 包各种方式命令
1、nohup 启动 jar 包命令
1.1 nohup启动jar包命令
nohup是一个命令,用于在服务器后台运行进程。下面是nohup启动jar包的命令:
nohup java -jar /path/to/your/jar/file.jar &
其中,/path/to/your/jar/file.jar表示你的jar包路径,&表示让进程在后台运行。
这个命令的好处在于,当你退出终端或关闭SSH连接时,进程仍然在后台运行,不受终端的影响。
1.2 nohup命令启动jar
下面是nohup命令启动jar的完整示例代码:
nohup java -jar /path/to/your/jar/file.jar &
这个命令可以在后台运行你的jar包。
1.3 nohup启动jar包乱码
如果你在使用nohup启动jar包时遇到了乱码的问题,可以修改locale设置。下面是修改locale设置的命令:
export LC_CTYPE=en_US.UTF-8
将en_US.UTF-8替换成你的本地语言环境,这样就可以解决乱码问题。
1.4 nohup启动jar包与tomcat
如果你的jar包需要与tomcat一起运行,可以通过以下命令启动:
nohup java -jar /path/to/your/jar/file.jar --server.port=8080 &
–server.port=8080可以替换成你需要的端口号。
1.5 nohup启动jar
下面是nohup启动jar的代码示例:
nohup java -jar /path/to/your/jar/file.jar &
这样,你的jar包就会在后台运行。
1.6 nohup启动jar包设置不打印日志
如果你不想让nohup启动的jar包打印日志,可以通过以下命令启动:
nohup java -jar /path/to/your/jar/file.jar >/dev/null 2>&1 &
这个命令将标准输出和标准错误输出都定向到了/dev/null,这样就不会打印日志了。
1.7 nohup启动jar包不输出日志
如果你的jar包在启动时输出了太多的日志,可以通过以下命令不输出日志:
nohup java -jar /path/to/your/jar/file.jar >/dev/null 2>&1 &
这个命令将标准输出和标准错误输出都定向到了/dev/null,这样就不会输出日志了。
1.8 linux启动jar包
在Linux系统中,启动jar包也很简单。下面是启动jar包的命令:
java -jar /path/to/your/jar/file.jar &
将上面的命令添加nohup即可在后台运行:
nohup java -jar /path/to/your/jar/file.jar &
1.9 nohup命令启动jar包
nohup命令在启动jar包时也非常有用。下面是nohup命令启动jar包的代码:
nohup java -jar /path/to/your/jar/file.jar &
这个命令可以将你的jar包在后台运行,不受终端的影响。
2、关于 Linux 中 nohup.out 日志过大问题解决方法
2.1 编写删除脚
vi ClearNohup.sh
脚本:
#!/bin/bash
this_path=$(cd `dirname $0`;pwd) #根据脚本所在路径
current_date=`date -d "-1 day" "+%Y%m%d"` #列出时间
cd $this_path
echo $this_path
echo $current_date
do_split() {
[ ! -d logs ] && mkdir -p logs
split -b 10m -d -a 4 ./tbox.log ./logs/tbox-${current_date} #切分10兆每块至logs文件中,格式为:tbox-xxxxxxxxxx
if [ $? -eq 0 ];then
echo "Split is finished!"
else
echo "Split is Failed!"
exit 1
fi
}
do_del_log() {
find ./logs -type f -ctime +30 | xargs rm -rf #清理30天前创建的日志
cat /dev/null > tbox.log #清空当前目录的tbox.log文件
}
if do_split;then
do_del_log
echo "tbox.log is split Success"
else
echo "tbox.log is split Failure"
exit 2
fi
2.2 使用crontab管理清除任务
crontab -e 添加定时任务:每周第一天的1点执行一次
0 1 * * */1 /home/tbox/ClearNohup.sh &>/dev/null
八、 如果删了 yum 命令,需重装
1、下载如下 rpm 包
存放目录
cd /home
到下面这个网站去下载如下 rpm
http://mirrors.163.com/centos/7/os/x86_64/Packages/
要下载的 rpm 包:
python-iniparse-0.4-9.el7.noarch.rpm
yum-metadata-parser-1.1.4-10.el7.x86_64.rpm
yum-3.4.3-168.el7.centos.noarch.rpm
yum-plugin-fastestmirror-1.1.31-54.el7_8.noarch.rpm
2、安装 rpm 包
rpm -ivh --force --nodeps python-pycurl-7.19.0-19.el7.x86_64.rpm
rpm -ivh --force --nodeps python-urlgrabber-3.10-10.el7.noarch.rpm
rpm -ivh --force --nodeps yum-metadata-parser-1.1.4-10.el7.x86_64.rpm
rpm -ivh --force --nodeps python-iniparse-0.4-9.el7.noarch.rpm
rpm -ivh --force --nodeps yum-3.4.3-168.el7.centos.noarch.rpm
3、下载 yum-3.4.3.tar.gz
根据上图的提示到 http://yum.baseurl.org/wiki
下载yum-3.4.3.tar.gz ,放到你指定的目录下解压,解压命令如下:
# 解压后进到yum-3.4.3目录
tar -zxvf yum-3.4.3.tar.gz
输入如下命令
./yummain.py update
4、yum 下载 wget 报错
发现 /etc/yum.repos.d 目录下没有文件
在其目录下新建一个文件163.repo
cd /etc/yum.repos.d
vi 163.repo
把下面内容复制进去,保存退出
执行 yum list,问题解决
[base]
name=CentOS-$releasever - Base
baseurl=http://mirrors.163.com/centos/7/os/$basearch/
gpgcheck=1
gpgkey=http://mirrors.163.com/centos/7/os/x86_64/RPM-GPG-KEY-CentOS-7
#released updates
[updates]
name=CentOS-$releasever - Updates
baseurl=http://mirrors.163.com/centos/7/updates/$basearch/
gpgcheck=1
gpgkey=http://mirrors.163.com/centos/7/os/x86_64/RPM-GPG-KEY-CentOS-7
[extras]
name=CentOS-$releasever - Extras
baseurl=http://mirrors.163.com/centos/7/extras//$basearch/
gpgcheck=1
gpgkey=http://mirrors.163.com/centos/7/os/x86_64/RPM-GPG-KEY-CentOS-7
[centosplus]
name=CentOS-$releasever - Plus
baseurl=http://mirrors.163.com/centos/7/centosplus//$basearch/
gpgcheck=1
enabled=0
九、设置秘钥登录(SSH免密远程登录)
文章链接:https://www.cnblogs.com/shisanye/p/17036311.html
文章链接:https://blog.csdn.net/u010606397/article/details/111251175
十、SELinux 权限设置
1. 开启 SELinu
// 检查 SELinux 的状态
getenforce
// 编辑配置文件
vi /etc/selinux/config
// 修改配置文件参数
SELINUX=enforcing
// 重启系统
reboot
2、关闭 SELinux
// 状态切换为 Permissive,表示 SELinux 不强制执行策略,但会记录违规行为
setenforce 0
3、永久关闭 SELinux
vi /etc/selinux/config
SELINUX=disabled
reboot
十 一、Kafka 的安装与整合SpringBoot 使用
1、下载 kafka
下载方式一:
下载地址:http://archive.apache.org/dist/kafka/2.3.1/
下载方式二(推荐使用):
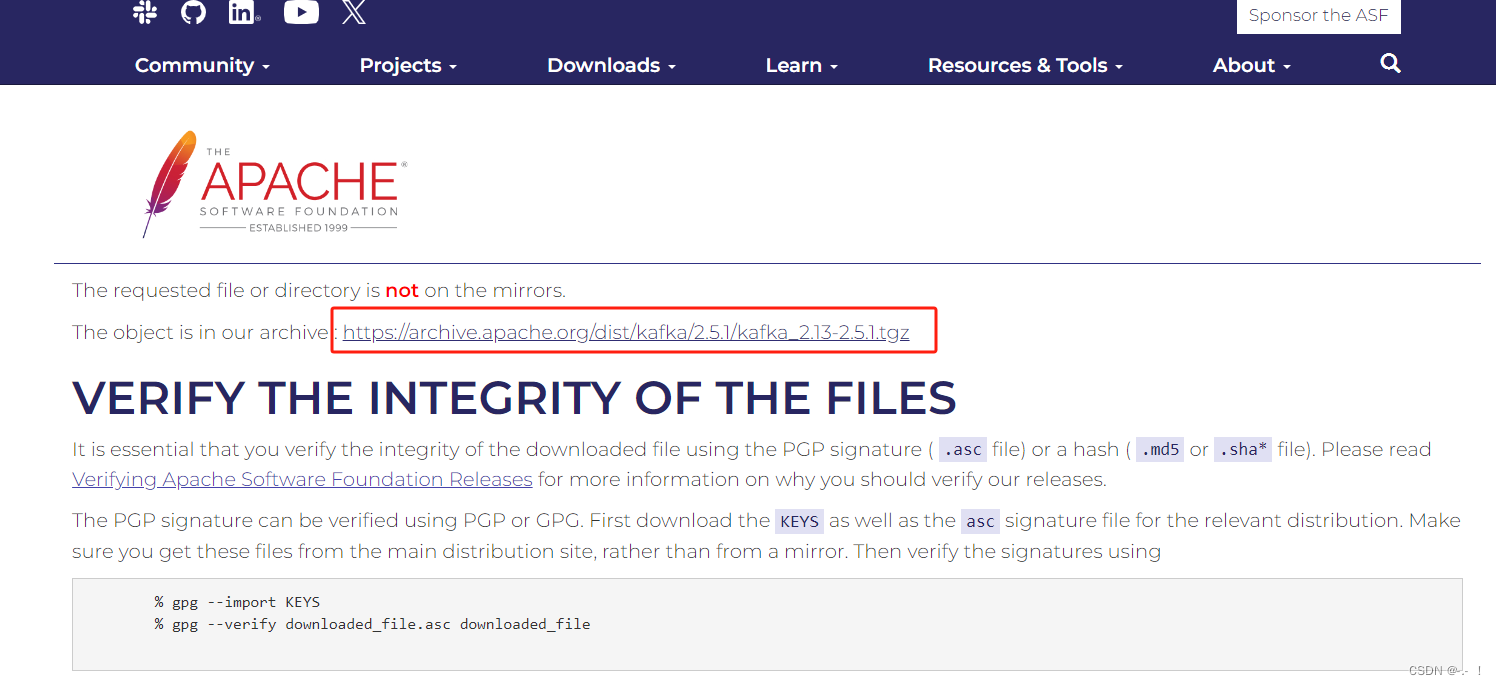
因为国外网址,下载速度很慢,建议大家使用镜像地址下载:
https://www.apache.org/dyn/closer.cgi?path=/kafka/2.5.1/kafka_2.13-2.5.1.tgz
2、安装 kafka
2.1 使用 Xftp 将 Kafka 传输到云服务器指定位置
放在 /usr/local/kafka 下
2.2 使用 Xshell 连接云服务器
// 进入放 kafka 压缩包的文件夹下
cd /usr/local/kafka
// 解压压缩包
tar -zxvf kafka_2.13-2.5.1.tgz
2.3 在 config 目录中修改相关配置
① 修改 zookeeper.properties 文件
// 在/usr/local/kafka/kafka_2.13-2.5.1 下新建一个 data 文件夹,用于存放 zookeeper 运行后的数据
cd /usr/local/kafka/kafka_2.13-2.5.1
mkdir data
// 进入 config 目录修改 zookeeper.properties 配置文件
cd /usr/local/kafka/kafka_2.13-2.5.1/confing
vim zookeeper.properties
// 修改 dataDir 路径,wq 保存退出
dataDir=/usr/local/kafka/kafka_2.13-2.5.1/data/zookeeper
② 修改 server.properties 文件
// 修改下 server.properties 配置文件,同样在 config 目录下修改配置文件
cd /usr/local/kafka/kafka_2.13-2.5.1/confing
vim server.properties
// 修改 log.dir 路径,wq 保存退出
log.dirs=/usr/local/kafka/kafka_2.13-2.5.1/data/kafka-logs
3、启动 kafka
① 先启动 zookeeper 再启动 kafka
因为 kafka 依赖于 zookeeper 所以先启动后者!
// 进入 bin 目录下执行,以指定配置文件启动 zookeeper 服务,守护进程启动方式,在结尾加一个 & 即可
cd /usr/local/kafka/kafka_2.13-2.5.1/bin
./zookeeper-server-start.sh ../config/zookeeper.properties
// zookeeper 服务启动后,打开一个新的命令窗口,执行命令,启动 Kafka服务,守护进程启动方式,在结尾加一个 & 即可
./kafka-server-start.sh ../config/server.properties
// 可以在 data 目录下看到 kafka 和 zookeeper 的启动日志文件
cd /usr/local/kafka/kafka_2.13-2.5.1/data
ll
云服务器,提前开放安全组端口
虚拟机,防火墙放行端口
kafka-zookeeper:2189
kafka:9092
// 开放防火墙2189端口
firewall-cmd --zone=public --add-port=2189/tcp --permanent
// 查看所有端口
firewall-cmd --zone=public --list-ports
② 关闭 zookeeper 和 kafka
// 在 bin 目录下
cd /usr/local/kafka/kafka_2.13-2.5.1/bin
// 关闭 zookeeper
./zookeeper-server-stop.sh
// 关闭 kafka
./kafka-server-stop.sh
③ 使用 kafka
kafka 消息发布订阅 (topics) 功能为例,来启动相关的文件,xxx.xxxx.xxx 是服务器ip
// 在 bin 目录下
cd /usr/local/kafka/kafka_2.13-2.5.1/bin
// 执行命令,创建一个主题
./kafka-topics.sh --create --bootstrap-server xxx.xxxx.xxx:9092 --replication-factor 1 --partitions 1 --topic test
// 命令含义:
--create:创建主题
--bootstrap-server xxx.xxxx.xxx:9092:创建主题的服务器及开放9092端口
--replication-factor 1:创建一个副本数量
--partitions 1:创建一个分区数
--topic test:主题名称
// 查看所有创建的主题列表
./kafka-topics.sh --list --bootstrap-server xxx.xxxx.xxx:9092
// 生产者 (producer) 向 kafka 某个主题上发送消息
./kafka-console-producer.sh --broker-list xxx.xxxx.xxx:9092 --topic test
// 消费者 (consumer) 从 kafka 某个主题上接收消息
./kafka-console-consumer.sh --bootstrap-server 8.131.66.136:9092 --topic test --from-beginning
4、SpringBoot 整合 kafka
① pom.xml 中引入Kafka依赖
<!-- https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.3.7.RELEASE</version>
</dependency>
② 配置 kafka 的 yaml 文件
kafka:
bootstrap-servers: xxx.xxx.xxx.xxx:9092 # kafka 服务器地址 :端口
producer:
# 发生错误后,消息重发的次数。
retries: 0
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# group-id:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
③ 测试使用
消费者
package com.xiaofan.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import java.util.Optional;
@Component
public class KafkaConsumer {
/**
* 消费者订阅的主题为test 就是通过 @KafkaListener(topics = {"test"}) 注解实现的
*
* @param record 接收的消息被封装成 ConsumerRecord 对象
*/
@KafkaListener(topics = "test", groupId = "3")
public void topicTest(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic){
Optional message = Optional.ofNullable(record.value());
if(message.isPresent()){
Object msg = message.get();
System.err.println("topic_test 消费了: Topic: " + topic + ",Message:" + msg);
ack.acknowledge();
}
}
}
生产者
package com.xiaofan.kafka;
import lombok.SneakyThrows;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import java.util.concurrent.TimeUnit;
@Component
public class KafkaProducer {
@Autowired private KafkaTemplate<String, Object> kafkaTemplate;
/**
* 发送消息
*
* @param topic 消息主题
* @param content 消息内容
*/
@SneakyThrows
public void sendMessage(String topic, String content) {
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, content);
RecordMetadata recordMetadata = future.get().getRecordMetadata();
if (recordMetadata == null) {
System.out.println("消息发送失败!");
}
SendResult<String, Object> result = future.get(3, TimeUnit.SECONDS);
System.out.println("发送的消息:" + result.getProducerRecord().value());
System.out.println("发送成功!");
}
}
Test测试
@Test
public void testKafka() {
// 生产者发送消息
kafkaProducer.sendMessage("test", "哈哈哈哈!");
kafkaProducer.sendMessage("test", "hhhhhh?");
// 在这里进行一下线程阻塞,模仿消费者消费消息的过程
try {
// 10s
Thread.sleep(1000 * 3);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
















 932
932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











