









2021年4月27日,ARM宣布推出新一代CMN产品——CMN-700,该产品有望在ARM的mesh网络方式、可扩展性、性能以及灵活性等方面带来更为显著的改进。
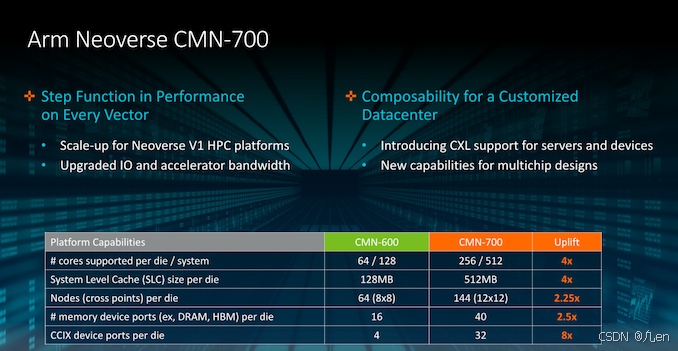
从新设计的基本特征开始,重要的新特性是网格现在已经从8 × 8节点(64)的限制增长到12 × 12(144),允许Arm增加单个网格和硅芯片上的CPU数量。
术语:
RN-F:Fully coherent Request Node(全相干请求节点) — 通常是一个CPU核心,一个双核的CAL,或一个DSU集群
HN-F:Fully coherent Home Node(全相干主节点) — 一个带有Snoop filter的SLC缓存块
CAL: Component Aggregation Layer(组件聚合层) — 一个包含两个CPU核心连接到一个RN-F端口的块
一个网格中的实际最大核数已经从64增长到256,后一个数字可以通过128个RN-F请求节点通过CAL(组件聚合层)每个2核实现。对于细心的读者来说,看到Arm说CMN-600只支持64核,而我们有80核的设计,比如Altra,可能会觉得很奇怪。Arm解释说,64核的限制是通过连接到RN-F或通过cal的本地核,当你通过DSU (DynamiQ Shared Units)将它们集成到网格中时,实际上可以托管更多的核。Ampere从未确定过他们的网格布局,但这似乎是他们如何在CMN-600上实现如此高的核心计数的唯一解释。
除了承载多达256个内核的128个RN-F外,该芯片还承载多达128个HN-F主节点,即SLC(System Level Cache)所在的节点。Arm在这里透露了每个die的最大SLC高达512MB,这意味着每个节点4MB,而奇怪的是,CMN-600只支持128MB,这在技术上是不正确的,因为参考手册说它在64个节点上每个节点4MB可达到256MB。
在这两种情况下,SLC的数字都有点极端,人们不应该期望很快就有这样大小的设计。
当前一代Graviton2和Altra Q芯片在其网格设计中仅具有32MB的SLC缓存容量。在过去我们没有讨论过的一个原因是,除了实际的SLC之外,网格中的HN-F节点还包含对大小要求特别高的snoop过滤器缓存。Arm表示,通常情况下,snoop过滤器的大小需要至少是核心独占缓存总量的1.5倍,所以在80核的Altra Q中,每核1MB的L2,在网格上至少需要120MB的snoop过滤器缓存,以及32MB的SLC。这将是一个很好的可能的解释,为什么SLC比AMD和Intel使用的要小,例如前者使用L2的shadow tags来保持一致性(而IOD使用CCD L3的shadow tags)。Arm的设计似乎面积效率不高。
网格中的最大内存控制器(CHI SN-F节点)已从16个端口大幅增加到40个端口,因为Arm设想在这些新设计中采用更广泛的混合存储系统架构和设计。
最后,CCIX端口也从4个大幅增加到32个,这对于一些将部署的分解芯片设计至关重要。
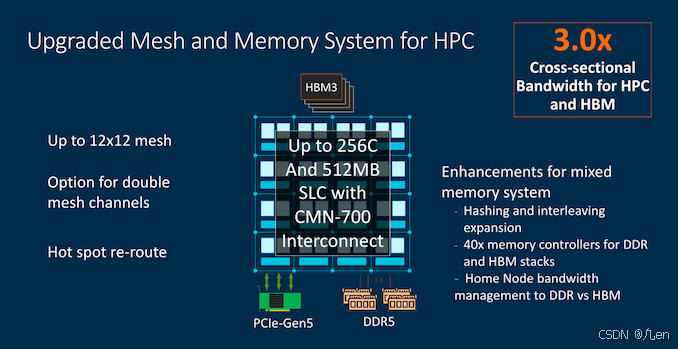
在内存能力方面,我们注意到Arm预计混合架构设计将不仅使用更多的DDR内存控制器,还将集成HBM内存。SiPearl的Rhea芯片再次是一个已被证实的设计,具有4个HBM2E堆栈和4到6个DDR5内存控制器。CMN-700能够处理这种内存配置,并适当管理异构内存架构中的带宽和流量。
Arm引用了网格中横截面带宽的三倍增长。其中一部分是通过代际更高的网格频率实现的,但新设计更重要的是现在允许节点之间的网格通道加倍。一个网格通道仍然是256位宽,具有专用的读写端口,所以加倍的设计实际上是每个方向的2x256位。Arm披露了大约2GHz的网格频率,所以如果我的计算没错的话,一个12x12的网格,如果通道加倍,将导致大约3TB/s的横截面带宽。
我们问Arm新的网格是否能够在直接连接节点的直接互连方面支持更奇特的3D路由,但遗憾的是,对于这一代产品,它仍然仅限于2D布局。
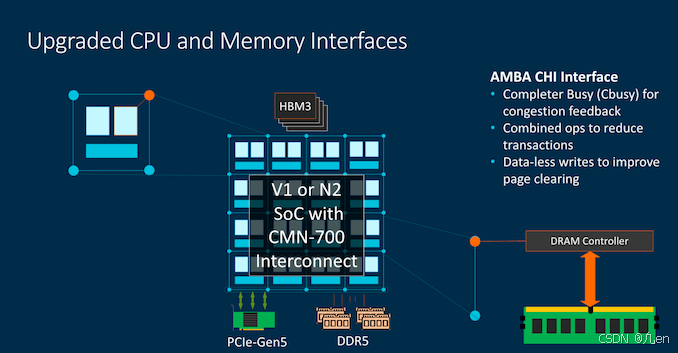
在V1系统特性中提到,CBusy是一种新的CPU-Mesh功能,旨在在高负载下缓解网格流量拥塞,通过改变CPU的流量需求来实现。此外,还有总体流量改进,例如合并操作以减少操作次数,或者直接操作,如无数据写入页面(将页面写为全零只需一次事务,而不是将零写入每个缓存行)。
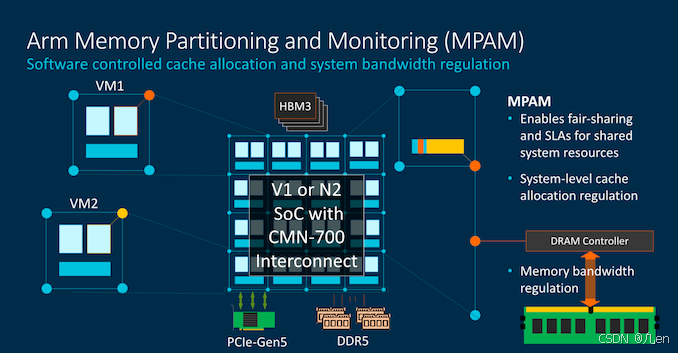
如前所述,在CPU部分中解释的MPAM有助于在系统(如虚拟机)上管理独立工作负载之间的流量,确保满足服务水平协议要求的服务质量,并在系统中的各个实体之间进行一般资源分配。
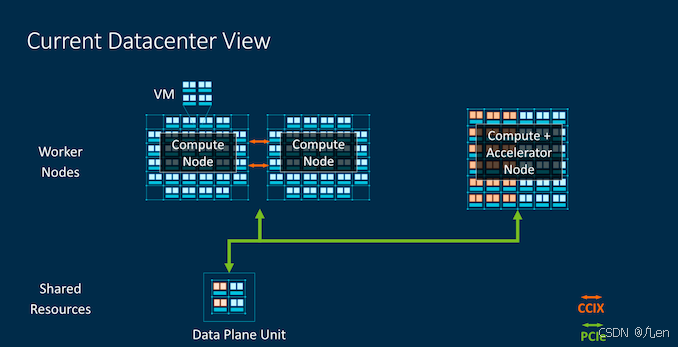
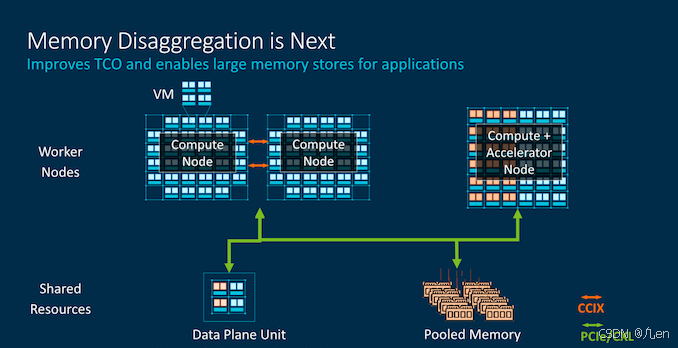
这一代的CMN-600已经支持CCIX 1.1,该技术已被应用于Altra Q等设计中。现在,CMN-700还引入了CCIX 2.0以及CXL兼容性。
除了通过PCIe与一致性加速器协同工作外,Arm还预见了未来内存解耦的趋势,届时,大型内存池将由CPU集群和计算或加速节点以一致性方式访问。
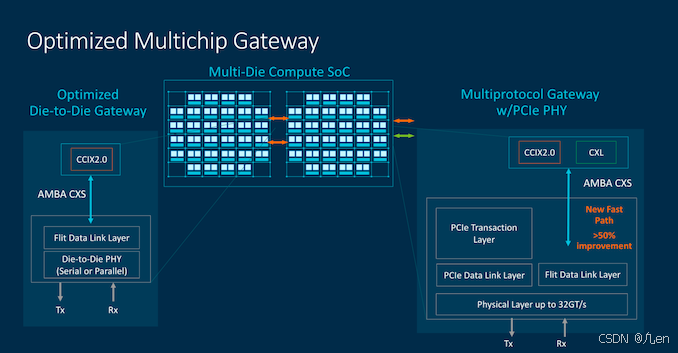
CCIX 2.0 对未来的multi-die和multi-socket设计非常重要,因为它允许去掉PCIe事务层和物理层,采用一个更封闭的通用链路层和PHY。前一代实现的一个重大缺点,例如在multi-socket系统中,在跨越所有这些不同层和协议时产生了巨大的延迟惩罚。我们在Ampere Altra芯片的core-to-core测试中看到了这一点的影响,该芯片在这方面表现非常糟糕。
新的CMN-700和CCIX 2.0互连有望解决这些非常高的延迟,以及在本地socket中的两个core之间通信时请求远程socket cache line的行为。这不仅对socket-to-socket的通信重要,也直接适用于chiplet-to-chiplet 的设计。需要注意的是,在这里Arm设计仍然需要在AMBA CHI和CCIX 2.0之间进行转换,尽管这比我们在CCIX 1.1实现中看到的情况有了很大改进,但很可能仍然不如Intel和AMD解决方案那样具有完全原生协议处理的性能。
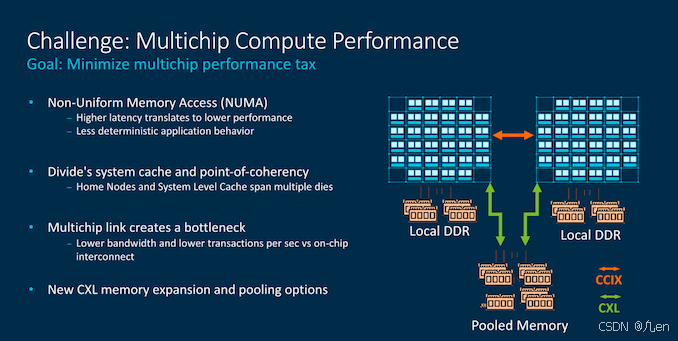
在通过NUMA域分离内存的多芯片系统中,处理相同数据时可能会导致性能下降。缓解这种情况的一种方法是将主节点的一致性分布在两个芯片之间(这就是为什么CMN-700被宣传为在一个“系统”中最多512个核心的原因)。这样做也有缺点,因为多芯片链接可能会造成瓶颈,但也可以设计一些奇特的架构,例如在两个芯片之间实现等同访问的共享内存。
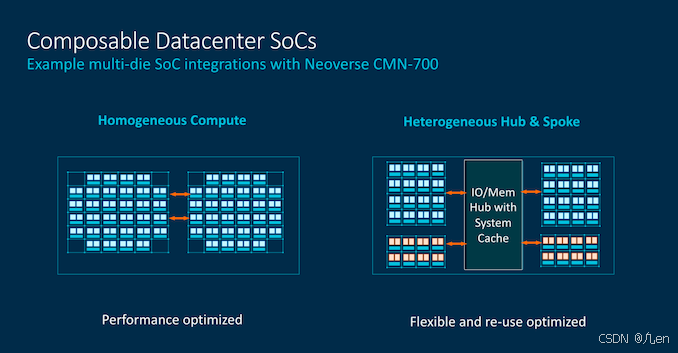
现在大多数读者应该已经熟悉AMD的chiplet方法,鉴于摩尔定律的放缓,大多数供应商都在朝着这种通用架构发展。Arm的CMN-700也允许设计出与AMD今天使用的非常相似的系统,其中可以有一个中央IO Hub,以及辅助的计算die。
我们可以有更多传统芯片设计简单地相互连接,或者有更多异构chiplet架构的复杂设计。
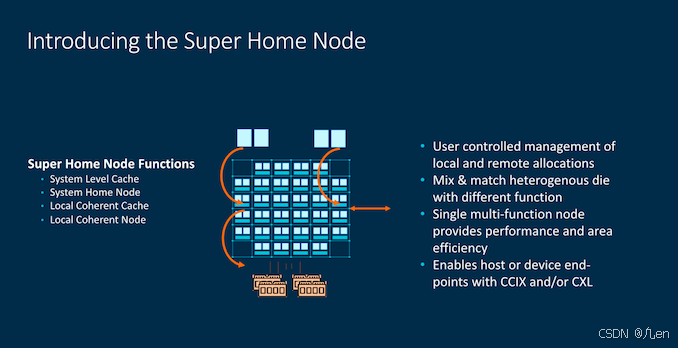
后来,Arm引入了“Super Home Node”的概念,它充当中央一致性点。本质上,这只是一个网格,但理论上它可以没有核心,仅仅容纳一个SLC(或没有),中央snoop filter处理所有cores的一致性。在这种架构中,该die内的SLC充当L4,而chiplet网格中的SLC充当L3。这里术语有些混乱,因为我们添加了layers和chiplets,但希望大多数人能理解这种层次结构。


















 1422
1422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









