









自监督对应学习的对比转换,Contrastive Transformation for Self-supervised Correspondence Learning(AAAI2021)
source code and pretrained model : https://github.com/594422814/ContrastCorr
【什么是对应学习?Correspondence learning?】
Temporal correspondence task: video object segmentation, video object tracking, semantic and instance propagation
【自监督体现在哪里?自监督信息是如何产生的?】
当前帧当做目标帧,之前的帧当做reference帧
【对比变换是什么意思?对比学习?跟transformer?】
主要是对比学习的应用,无transformer
无监督的表示学习 unsupervised representation learning
从未加标签的图像或视频中学习表示已被广泛研究。 无监督方法从不同角度探讨了作为监督信号的图像或视频内部的内在本质,例如帧排序(Lee等人2017),图像内容恢复(Pathak等人2016),深度聚类(Caron等人2018),亲和力扩散(Huang等人2020),运动建模(Pathak等人2017; Tung等人2017)和双向流量估算(Meister,Hur和Roth 2018)。 这些方法学习了无监督的特征提取器,可以通过使用一小组标记的样本进行进一步的微调来将其推广到不同的任务。 在本文,我们专注于无监督领域中的子区域,即特征学习,可进行细粒度的像素匹配而无需进行特定于任务的微调。 我们的框架与(Wang and Gupta 2015)分享了部分见解,该框架利用现成的视觉跟踪器进行数据预处理。 不同地,我们以端对端的方式联合跟踪和扩展feature embedding以进行补充学习。 我们的方法还受到对比学习的启发(Den Oord,Li和Vinyals 2018),这是无监督学习家族中的另一个流行框架。 在下文中,我们将详细讨论对应学习和对比学习。
自监督的对应性学习
在视觉对象跟踪(VOT),视频对象分割(VOS)和流量估计(Dosovitskiy et al.2015)任务中探索了时序对应 temporal correspondence。 VOT旨在基于初始目标框在每个帧中定位目标框,而VOS传播初始目标掩码。 为了避免繁琐的人工注释,自监督方法已引起越来越多的关注。 在(Vondrick et al.2018)中,基于逐帧affinity,来自参考帧的像素颜色作为自监控信号传输到目标帧。 Wang等 (Wang,Jabri和Efros 2019)在未标记的视频中进行前后跟踪,并利用起点和终点之间的不一致来优化特征表示。 UDT al Gorithm(Wang et al.2019)利用了类似的双向跟踪思想,并为无监督的跟踪器训练构建了相关滤波器。 在(Yang,Zhang,and Zhang 2019)中,通过使用单个视频片段进行增量学习来训练无监督的跟踪器。 最近,李艾尔等人。 Li et al.2019)以粗到精的方式结合了对象级和细粒度的对应关系,并显示出显着的性能提升。 在(Jabri,Owens和Efros 2020)中,时空对应学习被公式化为对比随机游走,并显示出令人印象深刻的结果。 尽管上述方法取得了成功,但它们仍将重点放在视频内自我监督上。 通过同时利用视频内和视频间的一致性来学习更多区分性特征嵌入,我们的方法又向前迈进了一步。 因此,以前基于视频内的方法可被视为我们框架的一部分。
对比学习
对比学习是一种流行的无监督学习范式,旨在扩大不同实例的嵌入分歧为了表示学习(Den Oord,Li和Vinyals 2018; Ye等人。2019; Hjelm等。 2019)。 基于对比框架,最近的SimCLR方法(Chen等人,2020年)显着缩小了有监督模型和无监督模型之间的性能差距。 他等。 (He et al。2020)提出了MoCo算法来充分利用存储库中的负样本。 受对比学习最近成功的启发,我们还为鉴别特征学习引入了大量否定样本。 与现有的对比方法相比,主要区别在于我们的方法在视频领域共同跟踪和扩展了特征嵌入。
因此,我们的方法捕获了随时间变化的外观变化,而不是手动增强静止图像。 此外,我们没有使用标准的对比损失(Hadsell,Chopra和Lecun 2006),而是通过概念上简单而有效的对比转换机制将对比思想纳入了对应任务,以缩小域差距domain gap。
Motivation: 以前的工作主要集中在每个视频片段内进行变换。主要通过两帧之间的相似性在单个视频内跨帧变换图像内容。在本文的方法中为了使instance-level更具有判别性的表示,本文在框架中引入了视频间的分析进行对比学习。


这是这篇文章的框架图。给定一批无标记的视频,通过patch level tracking获取图像对,分别进行视频内和视频间的变换。
Affinity-based Transformation
首先计算介绍一下帧重构(像素复制)操作,主要基于的假设是两个连续视频帧中的内容是连贯的。给定一对视频帧,可以从另一帧的像素中复制帧中的像素颜色(例如,RGB值)可以使用affinity矩阵Ar→t通过线性变换来表示帧重构操作。
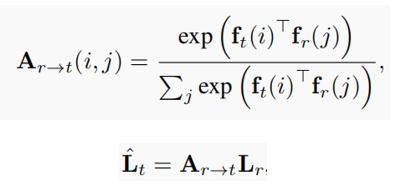
affinity矩阵中相似度测量的一般选择是feature embedding之间的点积。最用可以通过ˆLt = Ar→tLr将各种信息从Lr参考帧转换为目标帧。
对于 对比对的生成

传统对比框架中利用数据增强来建立正图像对。本文方法通过利用视频中内容的时序一致性来构造正图像对。 对于每个视频,我们首先利用patch level跟踪来获取一对内容相似的高质量图像patch。
具体实现是:给定参考帧中随机裁剪的patch,目的是在目标帧中定位最佳匹配的patch,计算参考帧中随机patch特征与整个目标帧特征之间的patch与帧的关联度。 基于这种关联性,在目标帧中,可以识别一些最类似于参考像素的目标像素,并将这些像素坐标平均为跟踪的目标中心。 我们还估计了采用UVC方法后的patch scale变化(Li等,2019)。
Intra- and Inter-video Transformations



然后进行视频内和视频间的变换,
对于Intra-video 视频内部的变换,
通过patch level tracking获得一对匹配的特征图后,计算亲和力矩阵,基于这种视频内相似性,可以在单个视频中将图像内容从参考patch转换为目标patch。
对于应用Inter-video 视频之间变换的motivation是
基于相似性的变换的主要是在众多子像素之间实现准确的标签复制。
但是在一对patch区域内,图像内容高度相关,甚至可能只覆盖了一个大物体的一个子区域,包含很少的来自其他对象的负像素。所以通过引入视频间变换来实现对比学习。
来自同一个video的帧是正样本,其他video的帧是负样本。将多个帧进行concat与目标帧计算亲和力矩阵A, A是由正样本亲和力矩阵和负样本亲和力矩阵组成的。图4是视频间变换的框架图。
loss function:

视频间的自监督loss:变换后的目标帧与原始的目标帧一致。
视频内和视频间的一致性:
来自其他视频的参考特征被认为是负嵌入。学习到的视频间亲和力预计将排除不相关的嵌入,以获得变换保真度
最后为了扩大不同视频特征之间的差异,约束视频间相似性Ar∑→t中的子相似性是稀疏的。
最后还添加了循环一致性的约束。















 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









