







1.背景简介
RNN是自然语言处理中比较重要一个模型。因为语言总是连续的,而且是上下文相关的。就比如,你说“今天杨__来家访了”,普通人往往能判断横线处应该是“老师”这个词,因为这就是通过上下文推断出来的。在使用RNN之前,主要的语言模型都是N-Gram。假设一个词语出现的概率之和前面的N个词语有关系。正是因为往往只和前面N个词汇有关系,不能够充分的考虑上下文信息,所以才会出现RNN,从而考虑上下文信息。这里有一段英文描述来阐述RNN的用途是不错的:
Processing Temporal Sequence
There are many tasks for which the output depends on a sequence of inputs rather than a single input. For example:
- Speech Recognition
- Time Series Prediction
- Machine Translation
- handwriting recognition
好了,接下来就开始介绍rnn。
2.1 SRN (RNN最初始的样子,2000年以前)
下图是一个最原始的RNN 叫做Simple Recurrent Network(SRN)1990年由Elman 提出。

在这个网络中,基于某个特定时刻(timestep), 输入X[I1,I2,I3] 是单次的序列会和context layer[O1,O2,O3] 一起计算H层的激活值。然后再下一次开始之前,将H层的激活值移动到上面的Contextlayer中去。因此,Context layer就是被用来记住在不断的循环中所涉及到的所有信息,从而预测正确的输出。
PS: 最基本的SRN可以增加一条’shortcut‘通路,直接从输入层接到输出层,或者从输出层返回隐藏层。这种设计有时叫做’Jordan Network‘
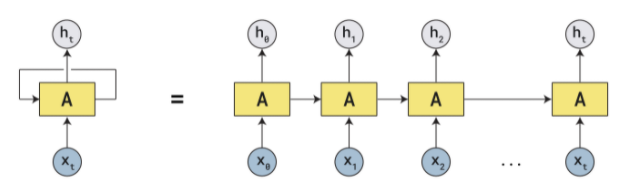
刚刚描述的是一次的过程, 那么如果循环起来,整个框架就会变成这样。看起来好像是不断循环,所以是循环神经网络。
还有一种网络结构叫做’Gated Network‘ 往往是用来处理二进制序列。

这里的二进制序列是用来动态选择W0还是W1,最后整个网络,W0,W1和P会不断地被反向传播算法所训练。这种循环结构常常用来预测正则化语言,举个例子:我们可以不断地训练网络一种正则化语言的规则“拒绝连续3个0出现的字符串”,那么我们就可以使用这个网络结构,尝试在向量空间中将其进行分类,从而进行识别。

当然,除了正则语言,我们还能预测非正则的语言,比如’AnBn‘就是说,是否一个序列出现的ab数量相同,通过不断训练是可以很好的解决的。
这就是到2000年之前,循环网络的应用。
2.2 现在的RNN(RPTT反向传播现在没有,以后有空了更新)
接下来阐述一下现在的神经网络是什么样子的呢?首先结构上并没有非常大的变化:

Ot = g(V * St) [每一次的输出都是隐藏层的值和隐藏层对应的权重矩阵进行相乘输出]
St = f(UXt + WSt-1) [每一次的隐藏层都取决于输入乘以输入矩阵+前一次的隐藏层结果*对应的系数矩阵 ]

2.3 Pytorch中的RNN
class torch.nn.RNN(*args, **kwargs) :应用多层的Elman RNN,使用tanh 或者ReLU 非线性函数来处理输入。
For each element in the input sequence, each layer computes the following function:
where h t h_t ht is the hidden state at time t t t, x t x_t xt is the input at time t t t, and h t h_t ht

参数列表:
input_size: 输入的气汤的特征数量
hidden_size:隐藏状态h的特征数量
num_layers:循环层数量。比如堆叠两个RNN形成一个堆叠RNN,第二个ENN接受第一个RNN的输出并计算结果。
nonlinearity:非线性函数。可选参数:’tanh‘,’relu‘ default:‘tanh’
bias:如果是false 那么就不会使用bias权重b_ih and b_hh.默认是True
batch_size:if True, 输入和输出向量被认为是(batch,seq,feature)而不是(seq,batch,feature)default:False
dropout:默认是0
bidirectional:是否设计成双向RNN,默认是False


这个方法很可能会梯度消失或者梯度爆炸(取决于推导公式中β的大小)
所以有一些方案来规避:
1、合理化的选择初始化权重值
2、使用relu来替代tahn以及sigmoid
3、使用LSTM或者是GRU















 7091
7091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









