









获取高德POI兴趣点的详细信息
思路介绍:
获取高德POI兴趣点主要分为两部分,一,爬取高德地图的想要搜索的兴趣点的数据,比如获取某市的所有桥梁信息,此时获得所有的市区范围内的桥梁信息,二,再用此获得的目录去百度百科爬取词条详细的数据。
一,获取高德地图POI数据
在搜索POI开发文档中可以查看到获取数据信息的方式。
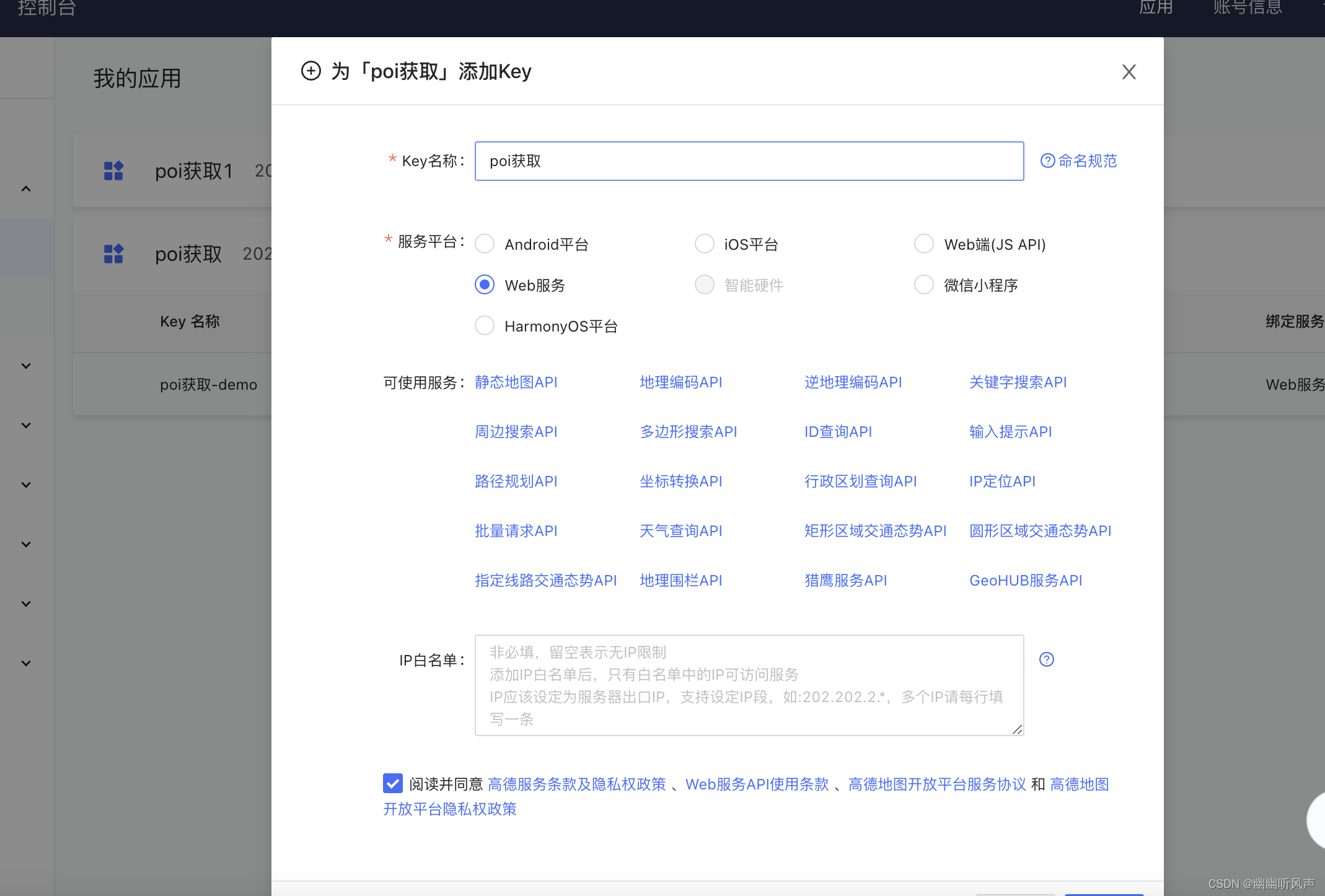
第一步,申请”Web服务API”密钥(Key);
首先找到高德开放平台高德开放平台提供的API接口,这里提供了高德开放的可以适用于各种客户端的获取POI的方式。
找到应用管理 添加一个key, 这个key后面用于发送请求使用。
第二步,拼接HTTP请求URL,第一步申请的Key需作为必填参数一同发送;
发送请求的网址:
https://restapi.amap.com/v3/place/text?keywords=输入的关键字&city=beijing&output=xml&offset=20&page=1&key=<用户的key>&extensions=all
keywords和type可以指定哪一个市区或者什么类型的POI。
在文档中可以获取到不同市区和建筑物种类的代码
拼接url的代码如下,
# 各下级行政区的代码,不要选择市区的代码,否则会出现问题
arr = [
'540102', '540103', '540104', '540121', '540122', '540123', '540124', '540127',
'540202', '540221', '540222', '540223', '540224', '540225', '540226', '540227', '540228', '540229', '540230',
'540231', '540232', '540233', '540234', '540235', '540236', '540237',
'540302', '540321', '540322', '540323', '540324', '540325', '540326', '540327', '540328', '540329', '540330',
'540402', '540421', '540422', '540423', '540424', '540425', '540426',
'540502', '540521', '540522', '540523', '540524', '540525', '540526', '540527', '540528', '540529', '540530',
'540531',
'540602', '540621', '540622', '540623', '540624', '540625', '540626', '540627', '540628', '540629', '540630',
'542521', '542522', '542523', '542524', '542525', '542526', '542527'
]
# API的URL,在这里进行了结构化处理
url1 = "https://restapi.amap.com/v3/place/text?keywords=桥&types=190307&city="
url2 = "&output=JSON&offset=20&key=4f981956ab23875a4636f9418832e54f&extensions=all&page="
# 用于储存数据
x = []
# 用于计数
num = 0
# 190307 地名地址信息 交通地名 桥
第三步,接收HTTP请求返回的数据(JSON或XML格式),解析数据。
官方对返回的POI数据的数量进行了限制,只能最多获取900条。所以逻辑加了一个判断。
# 循环各下级行政区进行POI检索
for i in range(0, len(arr)):
# 当前行政区
city = arr[i]
# 因为官方对API检索进行了45页限制,所以只要检索到45页即可
for page in range(1, 46):
# 若该下级行政区的POI数量达到了限制,则警告使用者,之后考虑进行POI类型切分
if page == 45:
print("警告!!POI检索可能受到限制!!")
# 构造URL
thisUrl = url1 + city + url2 + str(page)
# 获取POI数据
data = requests.get(thisUrl)
sleep(1)
# 转为JSON格式
s = data.json()
# 解析JSON
aa = s["pois"]
# 若解析的JSON为空,即当前行政区的数据不够45页(即没有达到限制),返回
if len(aa) == 0:
break
# 对每条POI进行存储
for k in range(0, len(aa)):
s1 = aa[k]["name"]
s2 = aa[k]["type"]
s3 = aa[k]["adname"]
x.append([s1, s2, s3])
num += 1
print("爬取了 " + str(num) + " 条数据")
# 将数据结构化存储至规定目录的xls文件中
c = pd.DataFrame(x)
c.to_csv('./getEXCELS/西藏桥梁汇总.xls', encoding='utf-8-sig')
二,将获取到的所有POI数据作为目录爬取详细信息
第一步,读取Excel文件中的数据
在这里用的是xlrd插件,将获取到的数据作为一个列表进行返回。
import xlrd
# 从Excel中获取名字,组装URL
def getBridgeNames():
# 打开一个excel
book = xlrd.open_workbook("getEXCELS/西藏桥梁汇总.xls")
# 打开excel中的哪一个sheet页
sheet = book.sheet_by_index(0)
# 获取名字的一列数据
bridge_names = sheet.col_values(1)
return bridge_names
第二步,封装请求头信息
随机在列表中拿取一个请求头
import random
user_agents = ['Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/525.19 (KHTML, like Gecko) Chrome/1.0.154.50 Safari/525.19',
'Mozilla/5.0 (Windows; U; Windows NT 6.0; de) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13']
def get_header():
header = {'User-Agent': random.choice(user_agents)}
return header
第三部,发送请求获取详细信息
这里存在一个问题:(暂未解决)
百度百科上对于不同的关键字,搜索到的词条的格式可能不同,比如搜索柳梧大桥和搜索拉萨大桥的词条的格式会存在不同再或者就是遇见百度百科没有资料的关键字。
而在获取页面的时候没有办法统一格式导致的有些信息无法取到,比如图片中的 有的属性叫桥长,但是在另一个里面属性为长度。
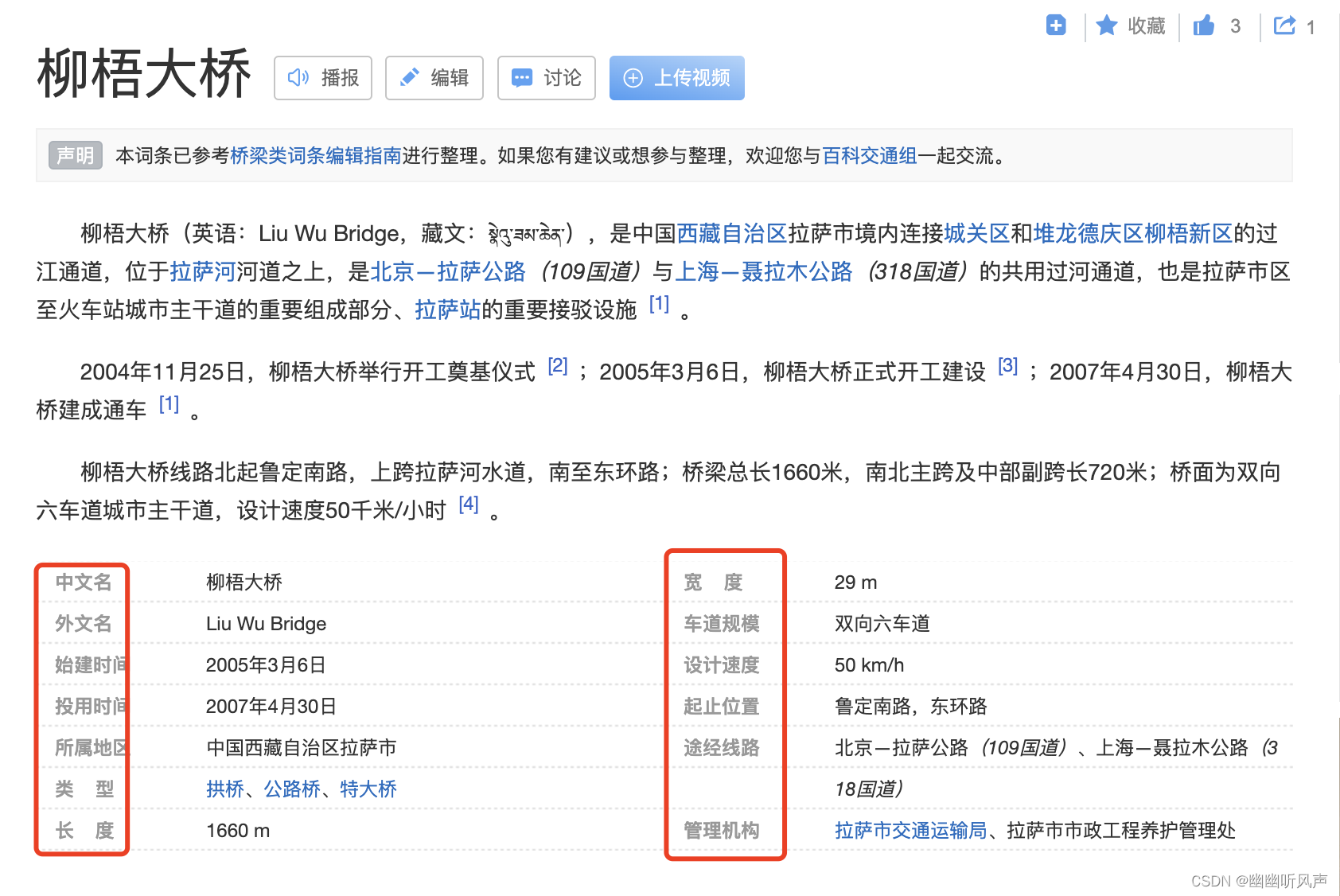

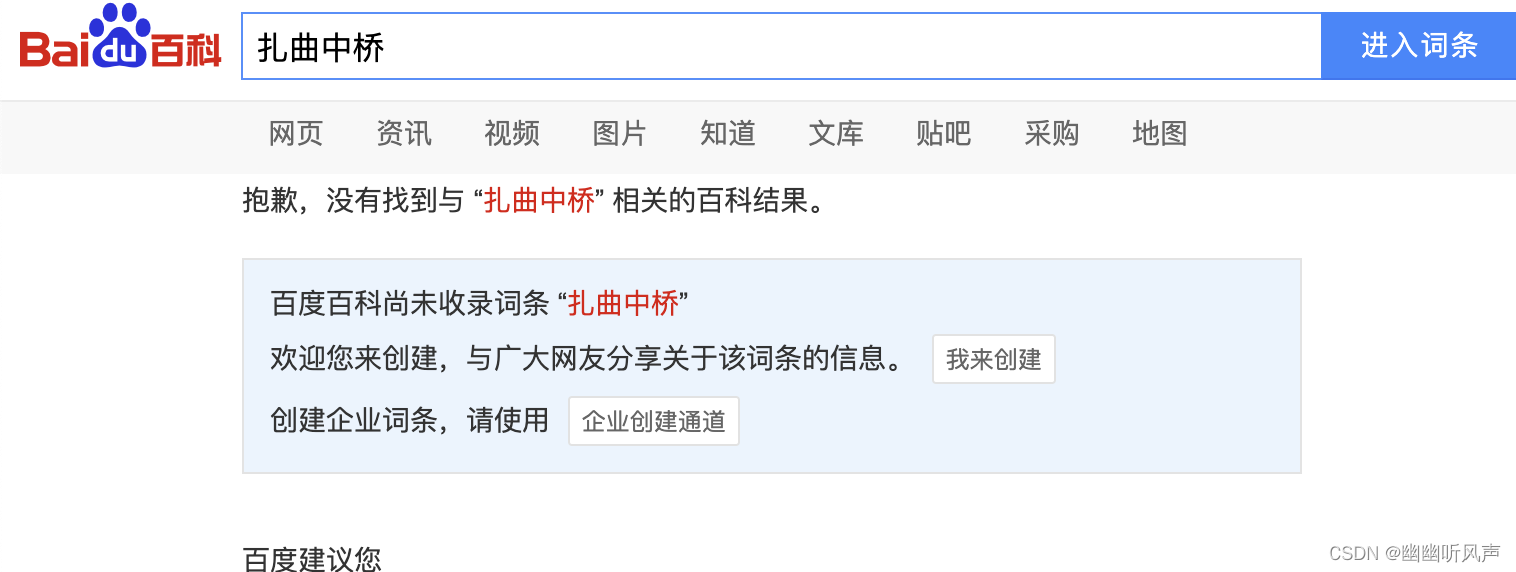
解析词条的代码如下,最终以一个列表返回所有的数据。
def getInfo(url, bridge_name):
# 获取代理ip
# proxies = ipGetter.ipGet()
# 拿到网页text数据
html_text = requests.get(url, headers=getHeaders.get_header()).text
# print(html_text)
# 加载进内存用来解析网页html数据
html_data = etree.HTML(html_text)
# 获取词条属性信息
base_title = html_data.xpath('//dl[contains(@class,"basicInfo")]/dt//text()')
base_info = html_data.xpath('//dl[contains(@class,"basicInfo")]/dd')
# 存放基础信息的列表
info = []
for element in base_info:
info.append(''.join(str.strip() for str in element.xpath('.//text()')))
# 将基础信息存放到字典里
info_dict = dict(zip(base_title, info))
# 创建一个列表 存放本次url的获取到的信息
# 加入中文名
tmp_info = [bridge_name]
# 英文名
english_name = info_dict.get("外文名", "")
tmp_info.append(english_name)
# 始建时间
build_time = info_dict.get("始建时间", "")
tmp_info.append(build_time)
# 投用时间
use_time = info_dict.get("投用时间", "")
tmp_info.append(use_time)
# 所属地区
address = info_dict.get("所属地区", "")
tmp_info.append(address)
# 类型
bridge_type = info_dict.get("类\xa0\xa0\xa0\xa0型", "")
tmp_info.append(bridge_type)
# 长度
length = info_dict.get("长\xa0\xa0\xa0\xa0度", "")
tmp_info.append(length)
# 宽度
width = info_dict.get("宽\xa0\xa0\xa0\xa0度", "")
tmp_info.append(width)
# 车道规模
lane_size = info_dict.get("车道规模", "")
tmp_info.append(lane_size)
# 设计速度
speed = info_dict.get("设计速度", "")
tmp_info.append(speed)
# 起止位置
start_stop_position = info_dict.get("起止位置", "")
tmp_info.append(start_stop_position)
# 途径线路
route = info_dict.get("途经线路", "")
tmp_info.append(route)
# 管理机构
manage_org = info_dict.get("管理机构", "")
tmp_info.append(manage_org)
# 获取简介
content_text = html_data.xpath('//div[@class="lemma-summary"]//text()')
if len(content_text) == 0 :
tmp_info.append("")
else:
content = ''.join([con.strip() for con in content_text])
tmp_info.append(content)
# 获取img图片信息
try:
img = "https://baike.baidu.com" + html_data.xpath('//a[@class="more-link"]/@href')[0]
tmp_info.append(img)
except Exception as e:
tmp_info.append("")
# 加入到列表汇总
bridge_info.append(tmp_info)
第四步,保存数据
将获取到的数据保存在excel中
# 保存数据
def saveData(dataList, savePath):
# 建立一个excel文档
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
# 建立一个sheet页
sheet = book.add_sheet("西藏桥梁汇总", cell_overwrite_ok=True)
cols = ["中文名", "英文名", "始建时间", "投用时间", "所属地区", "类型", "长度", "宽度", "车道规模", "设计速度", "起止位置", "途径线路", "管理机构", "简介", "图片链接"]
# 写入标题行
for i in range(15):
sheet.write(0, i, cols[i])
# 写入数据
for i in range(0, len(dataList)):
data = dataList[i]
for j in range(15):
sheet.write(i+1, j, data[j])
book.save(savePath)
效果展示及总结
最终的excel文档的样式为:
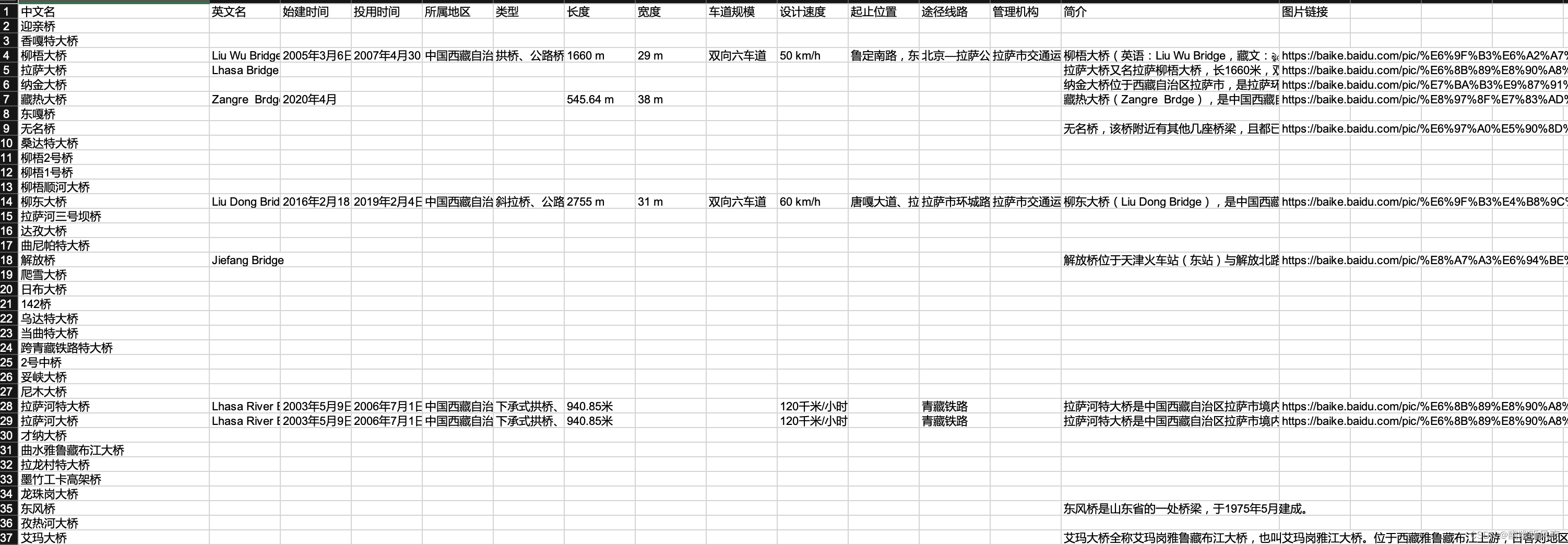
空值导致的原因可能有:
1,词条在百度百科不存在。
2,该属性在词条中不存在。
3,该属性在词条中的名称不相同。
存在的问题主要有:
1,词条不存在的关键字信息如何获取。
2,词条的属性格式不统一导致的无法获取到相同的信息格式。

















 9223
9223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









