







本文是对周志华老师《机器学习》一书中的笔记总结,强烈推荐查看原书!!!
强化学习在某种意义上可看作具有"延迟标记信息"的监督学习问题.
一、马尔可夫决策过程(Markov Decision Process,简称MDP)
1. MDP介绍
马尔可夫决策过程(Markov Decision Process, MDP)是序贯决策(sequential decision)的数学模型,用于在系统状态具有马尔可夫性质的环境中模拟智能体可实现的随机性策略与回报 。MDP的得名来自于俄国数学家安德雷·马尔可夫(Андрей Андреевич Марков),以纪念其为马尔可夫链所做的研究 。
MDP基于一组交互对象,即智能体和环境进行构建,所具有的要素包括状态、动作、策略和奖励 。在MDP的模拟中,智能体会感知当前的系统状态,按策略对环境实施动作,从而改变环境的状态并得到奖励,奖励随时间的积累被称为回报 。
MDP的理论基础是马尔可夫链,因此也被视为考虑了动作的马尔可夫模型 。在离散时间上建立的MDP被称为“离散时间马尔可夫决策过程(descrete-time MDP)”,反之则被称为“连续时间马尔可夫决策过程(continuous-time MDP)” 。此外MDP存在一些变体,包括部分可观察马尔可夫决策过程、约束马尔可夫决策过程和模糊马尔可夫决策过程。
在应用方面,MDP被用于机器学习中强化学习(reinforcement learning)问题的建模。通过使用动态规划、随机采样等方法,MDP可以求解使回报最大化的智能体策略,并在自动控制、推荐系统等主题中得到应用。
2. MDP定义
MDP是在环境中模拟智能体的随机性策略(policy)与回报的数学模型,且环境的状态具有马尔可夫性质。
1. 交互对象与模型要素
由定义可知,MDP包含一组交互对象,即智能体和环境
智能体(agent):MDP中进行机器学习的代理,可以感知外界环境的状态进行决策、对环境做出动作并通过环境的反馈调整决策。
环境(environment):MDP模型中智能体外部所有事物的集合,其状态会受智能体动作的影响而改变,且上述改变可以完全或部分地被智能体感知。环境在每次决策后可能会反馈给智能体相应的奖励
按定义,MDP包含5个模型要素,状态(state)、动作(action)、策略(policy)、奖励(reward)和回报(return),其符号与说明在表中给出
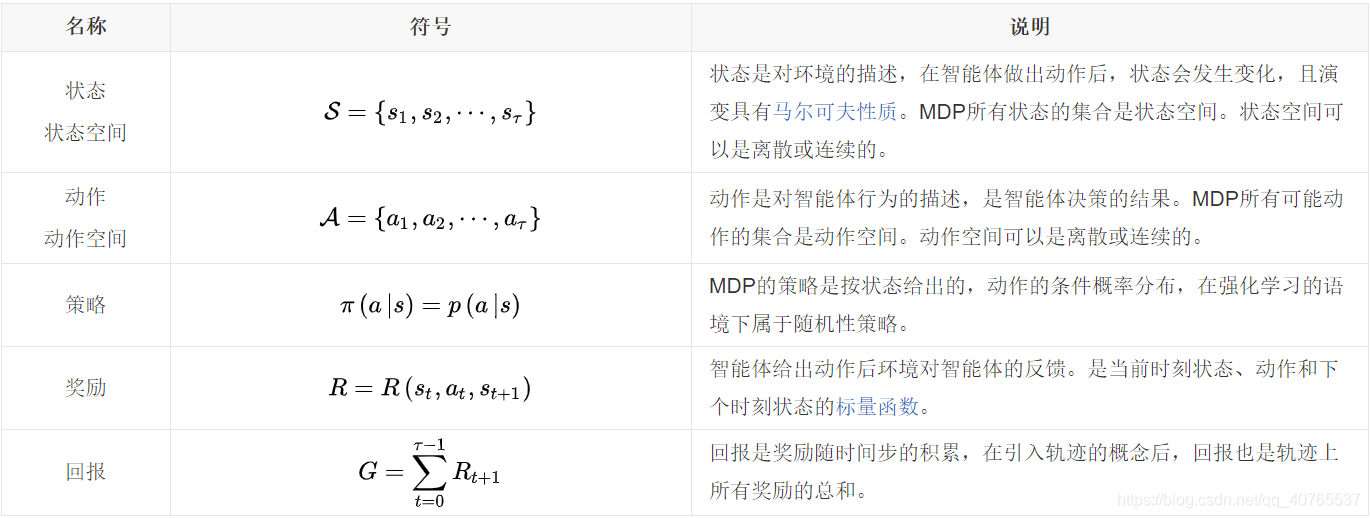
在表中建模要素的基础上,MDP按如下方式进行组织:智能体对初始环境 进行感知,按策略 实施动作 ,环境受动作影响进入新的状态 ,并反馈给智能体一个奖励 。随后智能体基于 采取新的策略,与环境持续交互。MDP中的奖励是需要设计的,设计方式通常取决于对应的强化学习问题
2.连续与离散MDP
MDP的指数集(index set)是时间步: ,并按时间步进行演化(evolution)。时间步离散的MDP被称为离散时间马尔科夫决策过程(descrete-time MDP),反之则被称为连续时间马尔科夫决策过程(continuous-time MDP),二者的关系可类比连续时间马尔可夫链与离散时间马尔可夫链。
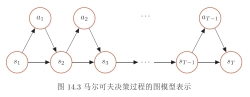
3.图模型
MDP可以用图模型表示,在逻辑上类似于马尔可夫链的转移图。MDP的图模型包含状态节点和动作节点,状态到动作的边由策略定义,动作到状态的边由环境动力项(参见求解部分)定义。除初始状态外,每个状态都返回一个奖励。
一、K摇臂赌博机
K摇臂赌博机是一个具体任务,示K-摇臂赌博机有 个摇臂,赌徒在投入一个硬币后可选择按下其中」个摇臂,每个摇臂以一定的概率吐出硬币?但这个概率赌徒并不知道.赌徒的目标是通过一定的策略最大化自己的奖赏,即获得最多的硬币。同时它也可以泛化成一种理论模型,也就是一种适用于其他任务的算法。
解决k摇臂赌博机的难点主要在于我们对于各给摇臂的奖赏(得到的金币)是未知的,因此我们需要探索每个摇臂的奖赏(最好的探索方法是我们每个摇臂都轮流往返的摇,就可以知道它的奖赏金币是多少),但是我们的最终目标是得到最大的奖赏,如果我们平均的摇,那么就会在一些低奖赏的摇臂上浪费太多的次数,但是你不平均的摇,就无法知道目前最多奖赏的是哪个摇臂,这两个问题称为探索(exploration,探索每个摇臂的奖赏)和利用(摇动奖赏最高的摇臂)问题。因此我们需要设计一个算法来折中这两种动作,从而能够得到最高的奖赏。
1. ϵ \epsilon ϵ 贪心
ϵ
\epsilon
ϵ-贪心法基于一个概率来对探索和利用进行折中:每次尝试时,以 的概率进行探索,即以均匀概率随机选取一个摇臂;以
ϵ
\epsilon
ϵ的概率进行利用,即选择当前平均奖赏最高的摇臂(若有多个,则随机选取一个)。

2. sofmax
softmax算法基于当前已知的摇臂平均奖赏来对探索和利用进行折中.若各摇臂的平均奖赏相当,则选取各摇臂的概率也相当;若某些摇臂的平均奖赏明显高于其他摇臂,则它们被选取的概率也明显更高。
softmax并不会显式地用 ϵ \epsilon ϵ选择探索还是利用,而是通过一个对与摇臂k地概率来达到探索和利用的折中。

Q
(
i
)
Q(i)
Q(i)是当前摇臂i的平均奖赏,
ρ
\rho
ρ称为温度,温度越小平均奖赏搞得摇臂被选中得概率越高,当温度趋于0的时候,softmax讲趋于仅利用,当温度趋于无穷大的时候,softmax将趋于仅探索。

三、有模型学习
什么是有模型学习?
假定任务对应的马尔可夫决策过程四元组E =<X,A,P,R>均为己知, 这样的情形称为 “模型 己知,即机器已对环境行了建模,能在机器内部模拟出与环境相同或近似的状况.在 己知模型的环境中学习称为"有模型学习” (model-based learning)。
因此,可以看到,上面给予k摇臂赌博机的 ϵ \epsilon ϵ贪心和softmax算法,其实都不是有模型学习,下面我们可以看到,他们实际上属于免模型学习。
在有模型学习中,由于E =<X,A,P,R>已知,所以事实上给定一个初始状态,我们是可以直接计算的到最优的路径(正经来讲叫做策略),所以有模型学习问题,其实就是一个奖赏最大化的计算问题。主要解决的问题就是如何计算以及如何进行高效的计算。
要求的最优的策略,那就是向前看T步,计算出相应的值函数或状态值函数(四元组E =<X,A,P,R>均为己知是可以直接向前看T步的基础),然后再决定当前步采取什么样的动作。事实上,这有两种计算思路,一种就是直接计算,另一种思路就是我们从包含T步的一个初始化策略出发,然后不断地改进这个策略,使得它变成最优的,那么这时候得到的策略一定是全局最优的。
因此,这就引出了有模型学习的两个基本问题:策略评估和策略改进。
策略是什么?策略是状态->动作,它可以是一种简单的if-else(硬策略,也叫表驱动的策略),也可以是概率化的策略,就是什么状态下以什么概率做出某动作(这个概率就是模型给出的,所以称为有模型学习)。
1. 策略评估
策略评估就是评估该策略带来的期望累计奖赏。所以这里我们引入两个函数。
V π ( x ) V^{\pi}(x) Vπ(x)表示从状态x出发,使用策略 π \pi π所带来的累积奖赏;函数 Q π ( x , a ) Q^{\pi}(x,a) Qπ(x,a)表示从状态x出发,执行动作a后再使用策略 π \pi π带来的累积奖赏. 这里V称为状态值函数(state value function),Q称为状态-动作值函数(state-action value function)。
状态值函数如下,这里的求平均操作的初衷是对轨迹中所有以 x 0 x_0 x0状态开始的长度为T的片段的累积奖赏进行平均,或者是是多次尝试的T步轨迹的累计奖赏进行平均。
{ V T π ( x ) = E π [ 1 T ∑ t = 1 T r t ∣ x 0 = x ] V γ π ( x ) = E π [ ∑ t = 0 + ∞ γ t r t + 1 ∣ x 0 = x ] \left\{\begin{array}{l} V_{T}^{\pi}(x)=\mathbb{E}_{\pi}\left[\frac{1}{T} \sum_{t=1}^{T} r_{t} \mid x_{0}=x\right] \\ V_{\gamma}^{\pi}(x)=\mathbb{E}_{\pi}\left[\sum_{t=0}^{+\infty} \gamma^{t} r_{t+1} \mid x_{0}=x\right] \end{array}\right. {VTπ(x)=Eπ[T1∑t=1Trt∣x0=x]Vγπ(x)=Eπ[∑t=0+∞γtrt+1∣x0=x]
{ Q T π ( x , a ) = E π [ 1 T ∑ t = 1 T r t ∣ x 0 = x , a 0 = a ] Q γ π ( x , a ) = E π [ ∑ t = 0 + ∞ γ t r t + 1 ∣ x 0 = x , a 0 = a ] \left\{\begin{array}{l} Q_{T}^{\pi}(x, a)=\mathbb{E}_{\pi}\left[\frac{1}{T} \sum_{t=1}^{T} r_{t} \mid x_{0}=x, a_{0}=a\right] \\ Q_{\gamma}^{\pi}(x, a)=\mathbb{E}_{\pi}\left[\sum_{t=0}^{+\infty} \gamma^{t} r_{t+1} \mid x_{0}=x, a_{0}=a\right] \end{array}\right. {QTπ(x,a)=Eπ[T1∑t=1Trt∣x0=x,a0=a]Qγπ(x,a)=Eπ[∑t=0+∞γtrt+1∣x0=x,a0=a]
接下来我们极少如何求这个平均的状态值函数,可以采用递归的方式,也就是,用上面的递归等式来计算值函数,实际上就是一种动态规划算法.对于
V
T
π
V_T^\pi
VTπ,可设想递归一直进行下去,直到最初的起点;换言之,从值
函数的初始值
V
0
π
V_0^\pi
V0π出发,通过一次迭代能计算出每个状态的单步奖赏
V
0
π
V_0^\pi
V0π,这样,只需迭代T轮就能精确地求出值函数。

π
(
x
,
a
)
\pi(x,a)
π(x,a)表示再x状态采取a动作的概率,后面就是采取a动作后,到达不同的可能状态的概率。两种加和表示第一步的一个平均奖赏,后面再加上T-1不得平均累计奖赏。



注意这里V和Q的区别,其实区别不大,Q就是比V多限定了一个动作。
1. 策略改进
对于一个随机初始化的策略,如何根据它的奖赏评估来改进他,从而最大化奖赏。
这里的改进是通过一种类似于探索-利用的思路来进行,但是这里的探索都是有用的探索,就是比如说我一开始的策略是初始化的策略,然后我评估它的平均累计奖赏。由于是有模型学习,事实上我是上帝,我什么都已知,所以我只要对于这个策略 π \pi π中对于每一个状态x它后面所要采取的的动作呢,我都取为从x出发经过T步得到的累计奖赏最大的哪个动作a。
那样的话是不是只要遍历一次 x ∈ X x \in X x∈X就行了呢?不是的,首先你取为从x出发经过T步得到的累计奖赏最大的哪个动作a是根据当前并不是最优的策略选取的,所以你更新完 π ( x ) \pi(x) π(x)就是策略 π \pi π对状态x应该依照什么概率采取什么动作,并不能说明是最优的策略,只有这个策略不在发生改变时,我们称它是最优的。
这个过程可以归纳为: 初始策略 π 0 \pi _0 π0 ->评估->根据评估改进策略->评估…
为什么这样得到的最终策略就是最优的?在西瓜书380也有一个简单的证明,不再赘述,但是没有说明它的本质,它的本质就是所有的评估其实依据的是我们的转移概率P,这个是已知且真实的,所以像马尔可夫平稳条件一样,一个随机初始化的策略,它一定会改进到一个最优策略。
因此,这种从包含T步的一个初始化策略出发,然后不断地改进这个策略的算法如下所示:

事实上,正如我们说到了还有另一种思路,那就是向前看T步,计算出相应的最优值函数或状态值函数,然后再决定当前步采取什么样的动作。

因为,这里的策略是经过向前看T步得到的,所以应当是T步最优的。
四、免模型学习
在现实的强化学习任务中,环境的转移概率、奖赏函数往往很难得知,甚至很难知道环境中共有多少状态.若学习算法不依赖于环境建模,则称为"免模型学习" (model-free learning) ,这比有模型学习要难得多。
在免模型情形下,策略选代算法首先遇到的问题是策略无法评估,这是由于模型未知而导致无法做全概率展开.此时只能通过在环境中执行选择的动作来观察转移的状态和得到的奖赏。 受摇臂赌博机的启发,一种直接的策略评估替代方法是多次"采样",然后求取平均累积奖赏来作为期望累积奖赏的近似,这称为蒙特卡罗强化学习。由于采样必须为有限次数,因此该法更适合于使用T步累积奖赏的强化学习任务。
另一方面,策略迭代算法估计的是状态值函数, 而最终的策略是通过状态-动作值函数来获得。当模型己知时,有很简单的转换方法,而当模型未知时,这也会出现困难。于是,我们将估计对象从状态值函数转变为估计每一对"状态-动作"的值函数。
1. 蒙特卡洛学习
在模型未知的情形下,我们从起始状态出发、使用某种策略进行采样,执行该策略并获得轨迹(称为trajectory),然后,对轨迹中出现的每一对状态-动作,记录其后的奖赏之和,作为该状态-动作对的一次累积奖赏采样值。多次采样得到多条轨迹后,将每个状态-动作对的累积奖赏采样值进行平均,即得到状态-动作值函数的估计。通过批处理轨迹所有动作进行策略的评估和改进,这样的学习算法成为蒙特卡洛强化学习算法。

同策略蒙特卡罗强化学习算法最终产生的是
ϵ
\epsilon
ϵ贪心策略.然而,引入
ϵ
\epsilon
ϵ贪心是为了便于策略评估,在使用策略时并不需要
ϵ
\epsilon
ϵ贪心;实际上我们希望改进的是原始(非 ε-贪心)策略.那么,能否仅在策略评估时引入
ϵ
\epsilon
ϵ贪心,而在策略改进时却改进原始策略呢?
可以,这就是异策略蒙特卡洛强化学习算法。

2. 时序差分学习
蒙特卡罗强化学习算法通过考虑采样轨迹,克服了模型未知给策略估计造成的困难。此类算法需在完成一个采样轨迹后再更新策略的值估计,而前面介绍的基于动态规划的策略迭代和值迭代算法在每执行一步策略后就进行值函数更新。两者相比,蒙特卡罗强化学习算法的效率低得多?这里的主要问题是蒙特卡罗强化学习算法没有充分利用强化学习任务的 MDP 结构。时序差分(Temporal Difference ,简称 TD) 学习则结合了动态规划与蒙特卡罗方法的思想,能做到更高效的免模型学习。
蒙特卡罗强化学习算法的本质,是通过多次尝试后求平均未作为期望累积奖赏的近似。但它在求平均时是"批处理式"进行的,即在一个完整的采样轨迹完成后再对所有的状态-动作对进行更新.实际上这个更新过程能增量式进行.
记得前面的蒙特卡洛算法中,有
Q ( x t , a t ) = Q ( x t , a t ) × count ( x t , a t ) + R count ( x t , a t ) + 1 Q\left(x_t, a_t\right)=\frac{Q\left(x_t, a_t\right) \times \operatorname{count}\left(x_t, a_t\right)+R}{\operatorname{count}\left(x_t, a_t\right)+1} Q(xt,at)=count(xt,at)+1Q(xt,at)×count(xt,at)+R
稍加转换得到
Q
(
x
t
,
a
t
)
=
Q
(
x
t
,
a
t
)
×
(
count
(
x
t
,
a
t
)
+
1
)
−
Q
(
x
t
,
a
t
)
+
R
count
(
x
t
,
a
t
)
+
1
=
Q
(
x
t
,
a
t
)
+
R
−
Q
(
x
t
,
a
t
)
count
(
x
t
,
a
t
)
+
1
=
Q
(
x
t
,
a
t
)
+
α
(
R
−
Q
(
x
t
,
a
t
)
)
\begin{align} Q\left(x_t, a_t\right)&=\frac{Q\left(x_t, a_t\right) \times (\operatorname{count}\left(x_t, a_t\right)+1) -Q\left(x_t, a_t\right)+R}{\operatorname{count}\left(x_t, a_t\right)+1}\\ &=Q\left(x_t, a_t\right)+\frac{R-Q\left(x_t, a_t\right)}{\operatorname{count}\left(x_t, a_t\right)+1}\\ &=Q\left(x_t, a_t\right) + \alpha ({R-Q\left(x_t, a_t\right)}) \end{align}
Q(xt,at)=count(xt,at)+1Q(xt,at)×(count(xt,at)+1)−Q(xt,at)+R=Q(xt,at)+count(xt,at)+1R−Q(xt,at)=Q(xt,at)+α(R−Q(xt,at))
注意到这里 R = 1 T − t ∑ i = t + 1 T r i R=\frac{1}{T-t} \sum_{i=t+1}^T r_i R=T−t1∑i=t+1Tri,仍涉及多个动作,而非增量式进行,因此我们使用 r + γ Q ( x ′ , a ′ ) r+\gamma Q\left(x^{\prime}, a^{\prime}\right) r+γQ(x′,a′)来近似估计R,从而使得动作-值函数的更新只依赖一个动作(增量式)。
因此,同策略和异策略就被修改为Sarsa算法和Q学习算法

3. Value Function Approximation
对于上述的状态值函数和动作值函数,在状态空间很小时,我们可以为每个状态初始化值,并使用Saras和Q学习算法来学习最终的状态值函数。但是在实际状况下,状态往往是连续的或者状态的数量及其大,单独估计每个状态的值变得不可接受的慢。
因此,我们可以引入一下函数来估计值函数,该函数以状态(+动作)作为输入,输出对应的状态值函数(或动作值函数)。比如线性函数。
那么这个值函数的label是什么的?
1)For MC, the target is the return R
2)For TD,the target is the TD target
五. 基于策略的强化学习

基于策略的强化学习不使用值函数,直接输入状态,输出动作。
1. Policy Gradient
Policy Gradient包含了Policy Based和Actor-Critic
Policy Gradient 严格来说就是一个深度神经网络,那么输入是什么?输出什么是?目标函数又是什么?
1)输入:状态
2)输出:策略(或者是由策略决定的下一步动作)
3)目标函数——最大化平均奖赏,即所有状态下所有可能动作所带来的奖赏的平均。
a. 只看单步奖赏
J ( θ ) = E π θ [ r ] = ∑ s ∈ S d ( s ) ∑ a ∈ A π θ ( s , a ) R s , a ∇ θ J ( θ ) = ∑ s ∈ S d ( s ) ∑ a ∈ A π θ ( s , a ) ∇ θ log π θ ( s , a ) R s , a = E π θ [ ∇ θ log π θ ( s , a ) r ] \begin{aligned} J(\theta) & =\mathbb{E}_{\pi_\theta}[r] \\ & =\sum_{s \in \mathcal{S}} d(s) \sum_{a \in \mathcal{A}} \pi_\theta(s, a) \mathcal{R}_{s, a} \\ \nabla_\theta J(\theta) & =\sum_{s \in \mathcal{S}} d(s) \sum_{a \in \mathcal{A}} \pi_\theta(s, a) \nabla_\theta \log \pi_\theta(s, a) \mathcal{R}_{s, a} \\ & =\mathbb{E}_{\pi_\theta}\left[\nabla_\theta \log \pi_\theta(s, a) r\right] \end{aligned} J(θ)∇θJ(θ)=Eπθ[r]=s∈S∑d(s)a∈A∑πθ(s,a)Rs,a=s∈S∑d(s)a∈A∑πθ(s,a)∇θlogπθ(s,a)Rs,a=Eπθ[∇θlogπθ(s,a)r]
b. 考虑后面所有的累积奖赏,即 Q ( s , a ) Q(s,a) Q(s,a)
∇ θ J ( θ ) = E π θ [ ∇ θ log π θ ( s , a ) Q π θ ( s , a ) ] \nabla_\theta J(\theta)=\mathbb{E}_{\pi_\theta}\left[\nabla_\theta \log \pi_\theta(s, a) Q^{\pi_\theta}(s, a)\right] ∇θJ(θ)=Eπθ[∇θlogπθ(s,a)Qπθ(s,a)]
Using return v t v_t vt, i.e., R, as an unbiased sample of Q π θ ( s , a ) Q^{\pi_\theta}(s, a) Qπθ(s,a)
c. 使用一个参数为w的critic函数更好地估计
Q
π
θ
(
s
,
a
)
Q^{\pi_\theta}(s, a)
Qπθ(s,a) -》Actor-Critic
Q
w
(
s
,
a
)
≈
Q
π
θ
(
s
,
a
)
Q_w(s, a) \approx Q^{\pi_\theta}(s, a)
Qw(s,a)≈Qπθ(s,a)
∇
θ
J
(
θ
)
≈
E
π
θ
[
∇
θ
log
π
θ
(
s
,
a
)
Q
w
(
s
,
a
)
]
Δ
θ
=
α
∇
θ
log
π
θ
(
s
,
a
)
Q
w
(
s
,
a
)
\begin{aligned} \nabla_\theta J(\theta) & \approx \mathbb{E}_{\pi_\theta}\left[\nabla_\theta \log \pi_\theta(s, a) Q_w(s, a)\right] \\ \Delta \theta & =\alpha \nabla_\theta \log \pi_\theta(s, a) Q_w(s, a) \end{aligned}
∇θJ(θ)Δθ≈Eπθ[∇θlogπθ(s,a)Qw(s,a)]=α∇θlogπθ(s,a)Qw(s,a)
d. 经证明,参数为w的critic函数实际上是可以替代为参数为 θ \theta θ的critic函数, 这里 θ \theta θ同时也是策略的参数。
∇ θ J ( θ ) = E π θ [ Q θ ( s , a ) ∇ θ log π θ ( s , a ) ] = E π θ [ Q w ( s , a ) ∇ θ log π θ ( s , a ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\pi_\theta}\left[Q^\theta(s, a) \nabla_\theta \log \pi_\theta(s, a)\right]=\mathbb{E}_{\pi_\theta}\left[Q_w(s, a) \nabla_\theta \log \pi_\theta(s, a)\right] ∇θJ(θ)=Eπθ[Qθ(s,a)∇θlogπθ(s,a)]=Eπθ[Qw(s,a)∇θlogπθ(s,a)]
e. 为了减少方差,在目标函数中可减去一个与a无关的量,刚好状态值函数与a无关,因此可用此量.
我们从策略梯度中减去基线函数B(s), 这可以在不改变期望的情况下减少方差
A
π
θ
(
s
,
a
)
=
Q
π
θ
(
s
,
a
)
−
V
π
θ
(
s
)
∇
θ
J
(
θ
)
=
E
π
θ
[
∇
θ
log
π
θ
(
s
,
a
)
A
π
θ
(
s
,
a
)
]
\begin{aligned} A^{\pi_\theta}(s, a) & =Q^{\pi_\theta}(s, a)-V^{\pi_\theta}(s) \\ \nabla_\theta J(\theta) & =\mathbb{E}_{\pi_\theta}\left[\nabla_\theta \log \pi_\theta(s, a) A^{\pi_\theta}(s, a)\right] \end{aligned}
Aπθ(s,a)∇θJ(θ)=Qπθ(s,a)−Vπθ(s)=Eπθ[∇θlogπθ(s,a)Aπθ(s,a)]
此时
A
π
θ
(
s
,
a
)
A^{\pi_\theta}(s, a)
Aπθ(s,a)称为优势函数 advantage function
证明:
E
π
θ
[
∇
θ
log
π
θ
(
s
,
a
)
B
(
s
)
]
=
∑
s
∈
S
d
π
θ
(
s
)
∑
a
∇
θ
π
θ
(
s
,
a
)
B
(
s
)
=
∑
s
∈
S
d
π
θ
B
(
s
)
∇
θ
∑
a
∈
A
π
θ
(
s
,
a
)
=
0
\begin{aligned} \mathbb{E}_{\pi_\theta}\left[\nabla_\theta \log \pi_\theta(s, a) B(s)\right] & =\sum_{s \in \mathcal{S}} d^{\pi_\theta}(s) \sum_a \nabla_\theta \pi_\theta(s, a) B(s) \\ & =\sum_{s \in \mathcal{S}} d^{\pi_\theta} B(s) \nabla_\theta \sum_{a \in \mathcal{A}} \pi_\theta(s, a) \\ & =0 \end{aligned}
Eπθ[∇θlogπθ(s,a)B(s)]=s∈S∑dπθ(s)a∑∇θπθ(s,a)B(s)=s∈S∑dπθB(s)∇θa∈A∑πθ(s,a)=0

五、参考资料
周志华 《机器学习》
DAVID SILVER Reinforcement Learning (https://www.davidsilver.uk/teaching/)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









