








目录
本篇文章主要是依托 sklearn 库,来进行决策树模型的建立。书中主要是从底层算法来建立决策树模型。对于纯小白来说,能明白原理是再好不过,如果有些难度,本篇文章或许能让我们比较简单的实现这个决策树的案例。
一、导入所需的第三方库
import pandas as pd
import numpy as np
import graphviz # 用于可视化决策树
from sklearn import tree
from sklearn.model_selection import train_test_split二、数据读取及预处理
2.1 读取数据
# 读取数据
data = pd.read_csv('lenses.txt',sep='\t',header=None)
data.columns = ['年龄','症状','是否散光','眼泪数量','眼镜类型']
data.head()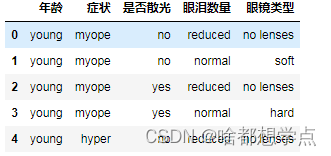
2.2 转换为数据集
这里需要强调一点的是,由于调用的 sklearn 库的决策树分类器 DecisionTreeClassifier()只支持数据类型,所以需要将数据里面的字符串转换为具体的数值。
data_array = np.array(data)
# 将字符串转换为数据
"""
young = 1,pre = 2, presbyopic = 3
myope = 1,hyper = 2,
no = 1,yes = 2,
reduced = 1,normal = 2,
no lenses = 1,hard = 2, soft = 3
"""
temp = data_array
list_1 = ['young','myope','no','reduced','no lenses']
list_2 = ['pre','hyper','yes','normal','hard']
for i in range(len(temp)):
for j in range(len(temp[i])):
if (temp[i][j] in list_1):
temp[i][j] = 1
elif (temp[i][j] in list_2):
temp[i][j] = 2
else:
temp[i][j] = 3
data_array = temp.astype('int')
2.3 划分特征集合标签集
# 划分特征数据和标签数据
data_labels = data_array[:,-1]
data_character = data_array[:,:4]
data_character[:10],data_labels[:10]
2.4 划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(data_character,data_labels,random_state=22,test_size=0.3)三、建立决策树模型
# criterion="entropy" 表示采用 ID3 算法
model = tree.DecisionTreeClassifier(criterion="entropy")
model.fit(X_train,y_train)四、用 test 中的数据检验
y_pre = model.predict(X_test.astype('int'))
print(y_pre)
print("预测准确率:",y_pre == y_test)
print(model.score(X_test,y_test))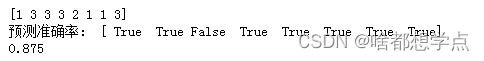
五、决策树可视化显示
"""
model:决策树模型
out_file:图形数据的输出路径
class_names:目标属性的名称,一般用于中文化
feature_names:特征属性的名称,一般用于种文化
filled= True :是否使用颜色填充
rounded=True:边框是否采用圆角边框
"""
tree_data = tree.export_graphviz(model,
out_file=None,
filled=True,
rounded=True,
special_characters=True,
feature_names=data.columns[:4],
class_names=['no lenses','hard','soft'])
graph = graphviz.Source(tree_data)
graph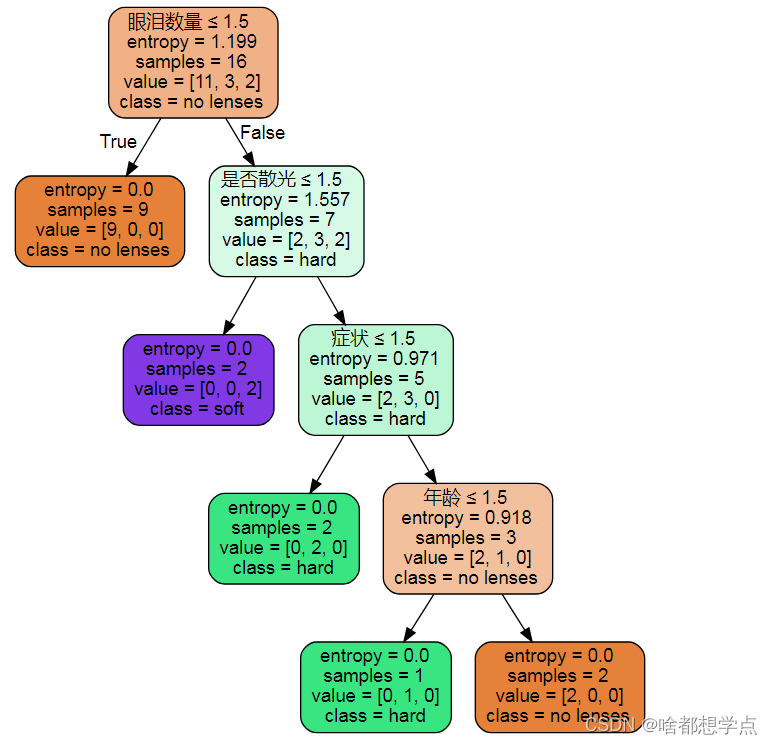















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









