







Pytorch深度学习(六):Softmax函数实现多分类
- 参考B站课程:《PyTorch深度学习实践》完结合集
- 传送门:《PyTorch深度学习实践》完结合集
一、预备知识
-
多分类
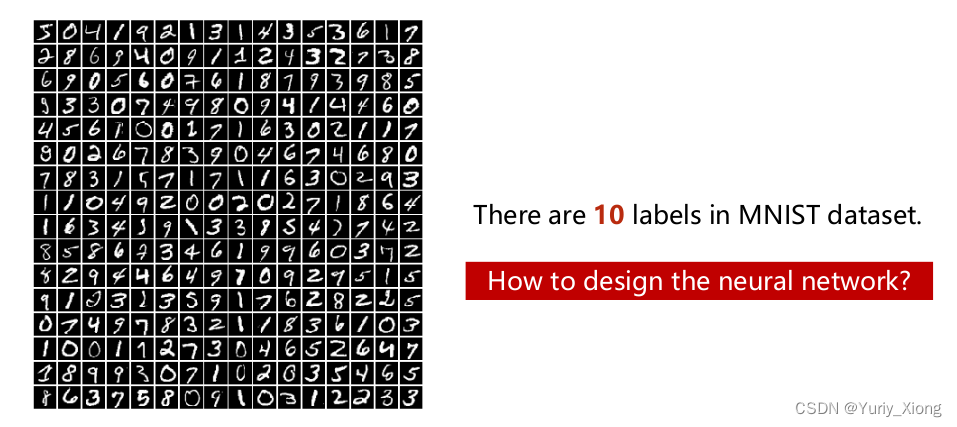
与之前的二分类不同,这个例子要识别手写数字的多分类
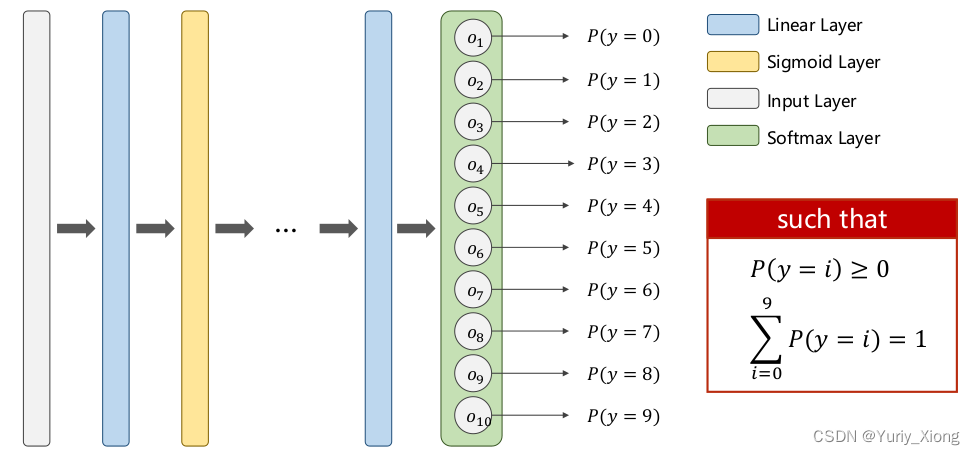
需要求出各类别的概率分布,且这些概率之和为1 -
Softmax函数
softmax函数,又称归一化指数函数。它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。下图展示了softmax的计算方法
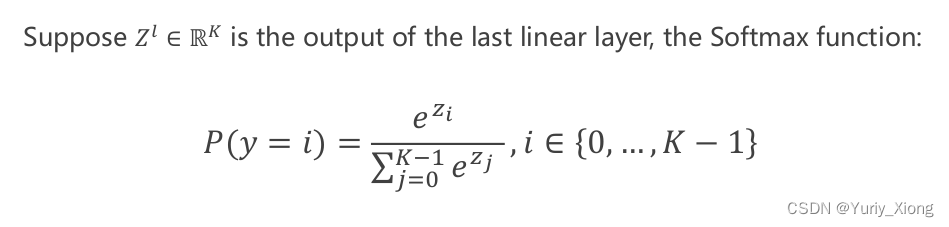
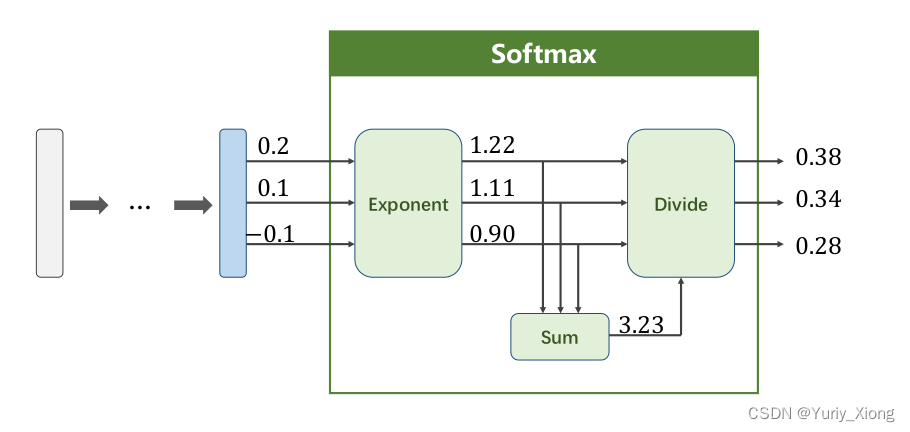
下面给出一个简单的例子,展示softmax层的计算
同样,在处理手写数字图片识别时,我们可以通过softmax层求出概率分布 -
LOSS函数——交叉熵
我们不再使用之前的BCE损失函数(用于二分类)来度量,而选用CrossEntropy损失函数。
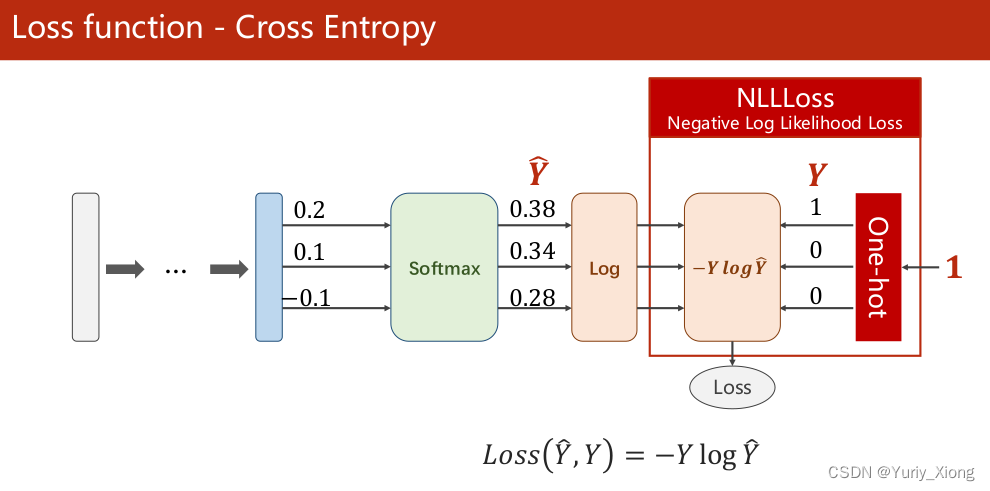
其中 Y ^ \hat{Y} Y^ 为预测的概率分布, Y Y Y 为训练集的数据 -
激活函数:ReLu
与之前的Sigmoid函数不同,这里我们使用ReLU(Rectified Linear Unit,修正线性单元)函数:
R e L u ( x ) = max { 0 , x } = { x , x ≥ 0 0 , x < 0 ReLu(x) = \max\{0,x\}=\begin{cases} x,\qquad x\geq 0\\0,\qquad x<0 \end{cases} ReLu(x)=max{0,x}={x,x≥00,x<0

-
数据集
traindataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
我们下载的训练集的图像,每张像素为 28 × 28 = 784 28\times 28 = 784 28×28=784
- 流程图

二、程序实现
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
])
traindataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
trainloader = DataLoader(traindataset,
shuffle=True,
batch_size=batch_size)
testdataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
testloader = DataLoader(testdataset,
shuffle=False,
batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
runingloss = 0.0
for batchidx, data in enumerate(trainloader, 0):
inputs, target = data
# inputs 为图片batch, target为一维张量用于储存图片结果下同labels
optimizer.zero_grad()
# forward, backward, update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
runingloss += loss.item()
if batchidx % 300 == 299:
print('[{:d}, {:5d}] loss: {:.3f}'.format(epoch+1, batchidx+1, runingloss/300))
runingloss = 0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: {:.3f} %'.format(100* correct / total))
if __name__ == '__main__':
for epoch in range(5):
train(epoch)
test()
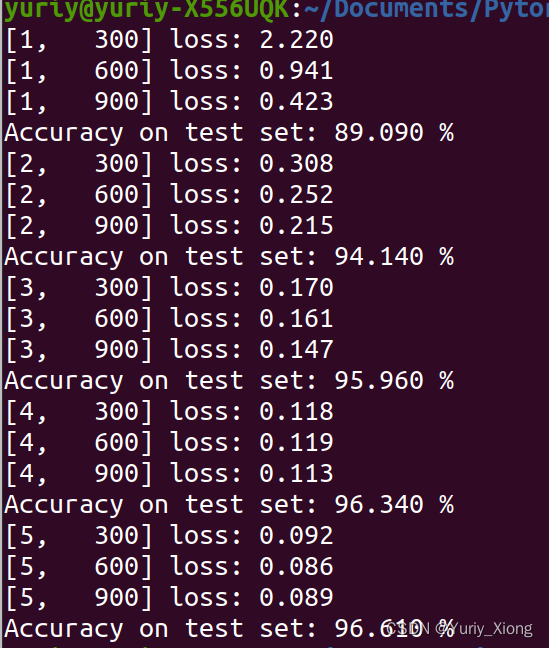
- 程序结果















 2174
2174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









