







淘宝这种大厂反扒机制相对其他网站要高不少,姑且先说一下我在数据获取时遇到的各种问题:
- 首先我从请求入手的时候,我发现右键点开源代码的时候网页信息在源代码上根本都找不到。。。哇的一声就哭了
- 数据找不到就找一下reasonse呗,数据在页面上显示出来了必定会存在网站上,于是我就在网页上随便找一个数据,打开F12,在搜索框里搜索,看一下数据在哪里。
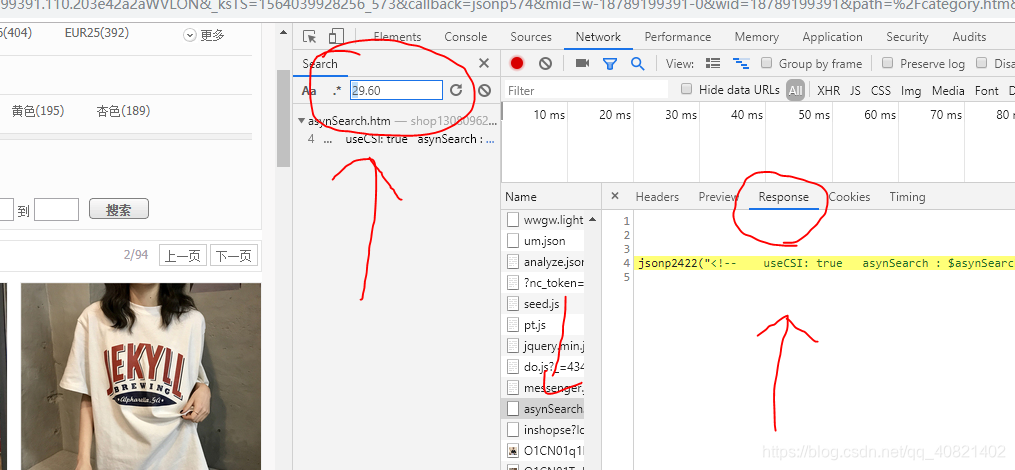
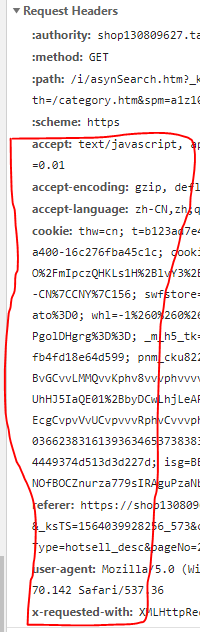
- 找到数据之后有些欣喜,就赶紧想把这块数据爬下来,一阵requests请求加上请求头,这里一定要先登陆一下再做请求头,里面一定要有cookie。并且请求头要全面,下图的这些东西最好都放进去,然后数据就能请求到了,如果说请求到的数据不是response里的而是一个登陆的链接那可能是伪装的不好,网站识别到不是浏览器访问,才会弹出登录链接。
- 所有的数据虽然可以匹配出来了,但是我要如何才能把需要的东西匹配出来呢?只是太浅不知道怎么把这些的有用数据匹配出来(捂脸),得到的数据就类似下图这种的。

当然我一定抽时间把这个问题给解决了,然后我决然换了一种思路,用selenium爬,万能的selenium啊!!!
我就还是只说一下我爬的过程中的一些问题和解决办法:
- selenium可以获取到网站显示的所有数据,但是有个缺点就是慢,,
- selenium每次打开浏览器都会先登陆一下淘宝,但是淘宝登录需要验证码,不过在网站看到有前辈写了一个第三方微博登陆的,不需要滑动验证,很
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8464
8464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









