







运行效果:东南大学齿轮箱故障诊断(Python代码,MSCNN结合LSTM结合注意力机制模型,代码有注释)_哔哩哔哩_bilibili
运行代码要求:
代码运行环境要求:Keras版本>=2.4.0,python版本>=3.6.0
1.东南大学采集数据平台:

数据
该数据集包含2个子数据集,包括轴承数据和齿轮数据,这两个子数据集都是在传动系动力学模拟器(DDS)上获取的。(第一个文件夹是轴承数据,第二个文件夹是齿轮数据,本次是针对齿轮数据进行故障诊断)

有两种工况,转速-负载配置设置为20-0和30-2。
在每个文件中,有8行信号,分别表示:x、y和z三个方向上行星齿轮箱的1-电机振动、2、3、4-振动、5-电机扭矩、x、y和z三个方向上并联齿轮箱的6、7、8-振动。第2、3、4列信号最有效。
这次实验使用第2列数据。
每种工况下有4种故障状态和1种正常状态。
code20_0.py是20_0工况下故诊断代码
code30_2.py是30_2工况下故诊断代码
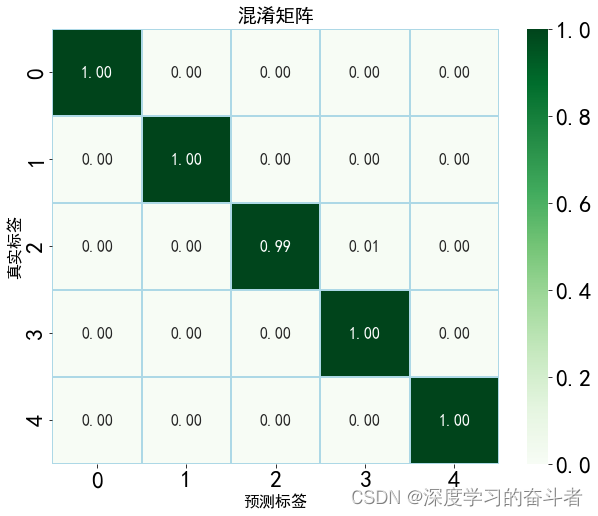
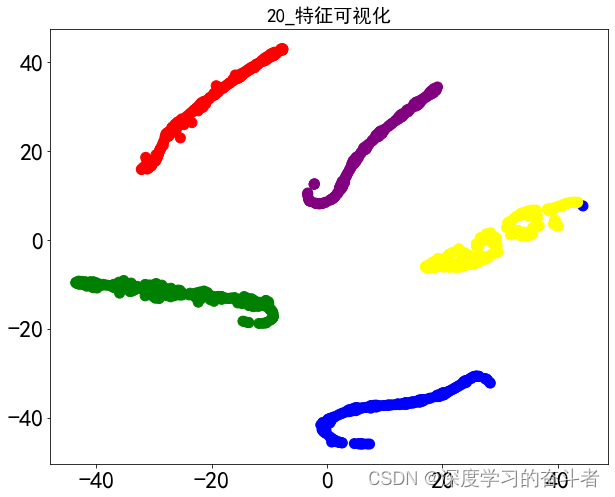
实验结果
20工况


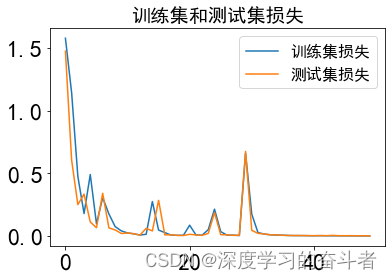
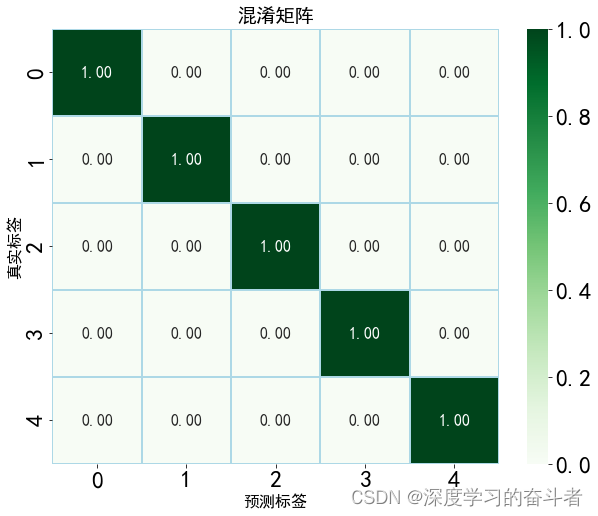
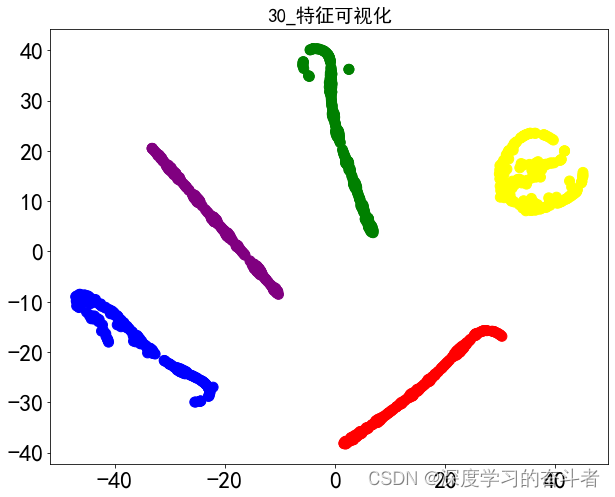
30_2工况下

对代码感兴趣的可以关注最后一行
import os
import pandas as pd
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif']=['simhei'] # 添加中文字体为黑体
plt.rcParams['axes.unicode_minus'] =False
Chipped_20_0=pd.read_csv('Chipped_20_0.csv').iloc[17:1048576,:]
Health_20_0=pd.read_csv('Health_20_0.csv').iloc[17:1048576,:]
Miss_20_0=pd.read_csv('Miss_20_0.csv').iloc[17:1048576,:]
Root_20_0=pd.read_csv('Root_20_0.csv').iloc[17:1048576,:]
Surface_20_0=pd.read_csv('Surface_20_0.csv').iloc[17:1048576,:]
#代码及数据集https://mbd.pub/o/bread/ZJyblp1q















 1523
1523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











