







上一篇:NLP篇【02】白话Word2vec原理以及层softmax、负采样的实现
下一篇:NLP【04】tensorflow 实现Wordvec(附代码详解)
一、前言
Glove模型是在Word2vec之后提出来的训练词向量的模型,glove可以说是在Wordvec模型基础上改进而来的模型,所以理论上,glove训练的词向量的效果会更好。在应用的时候,我们可以结合glove词向量和Word2vec词向量,不过对我们来说,理解glove是如何在wordvec基础上改进的,才是最重要的,因为这种思想可以运用到改进其他算法模型。
二、Glove基本思想
GloVe模型的思想方法,主要结合以下两个算法:
一个是基于奇异值分解(SVD)的LSA算法,该方法对term-document矩阵(矩阵的每个元素为tf-idf)进行奇异值分解,从而得到term的向量表示和document的向量表示。此处使用的tf-idf主要还是term的全局统计特征。
另一个方法是word2vec算法,该算法可以分为skip-gram 和 continuous bag-of-words(CBOW)两类,但都是基于局部滑动窗口计算的。即,该方法利用了局部的上下文特征(local context)
LSA和word2vec作为两大类方法的代表,一个是利用了全局特征的矩阵分解方法,一个是利用局部上下文的方法。
GloVe模型就是将这两种特征合并到一起的,即使用了语料库的全局统计(overall statistics)特征,也使用了局部的上下文特征(即滑动窗口)。为了做到这一点GloVe模型引入了Co-occurrence Probabilities Matrix。要计算共现概率矩阵,我们先来计算共现矩阵,共现矩阵是单词对共现次数的统计表。我们可以通过大量的语料文本来构建一个共现统计矩阵。
例如,有语料如下:
I like deep learning.
I like NLP.
I enjoy flying.
以窗半径为1来指定上下文环境,则共现矩阵就应该是:
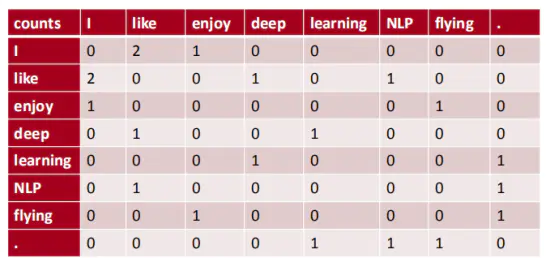
那么共现概率矩阵是就是每个值除于每行的和,例如对于第一行就是p(like | I)=2/(1+2)=2/3 ,也就代表着第一个词出现I ,第二个词出现 like的概率为2/3。这样依次计算我们就会得到一个共现概率矩阵。
根据上一篇所讲的word2vec原理,我们知道,对于cbow或者skip-gram,如果窗口size为1,则like相似的词就是前后各一个词,而且描述的是否相似,标签要么为1要么为0,和全局出现的情况无关。而Glove是想办法找到一个算法可以描述这个共现概率矩阵。那么最后我们来看看它是如何找到某个算法来描述这个共现概率矩阵。


模型推导过程 :


















 1084
1084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









