







 该文提出将分词模型与NER模型融合训练,以增强中文社交媒体的命名实体识别效果。通过LSTM-CRF结构,利用字符的词性embedding、字符embedding及分词模型的隐藏层输出作为特征,论文和代码链接已提供。
该文提出将分词模型与NER模型融合训练,以增强中文社交媒体的命名实体识别效果。通过LSTM-CRF结构,利用字符的词性embedding、字符embedding及分词模型的隐藏层输出作为特征,论文和代码链接已提供。
简介
文章主要贡献将训练分词的模型(单向LSTM-CRF)与NER的训练合并来试图提高NER模型的性能。
论文地址: https://arxiv.org/pdf/1603.00786.pdf
代码gitlab地址: https://github.com/hltcoe/golden-horse
模型结构
模型的总体结构如下:
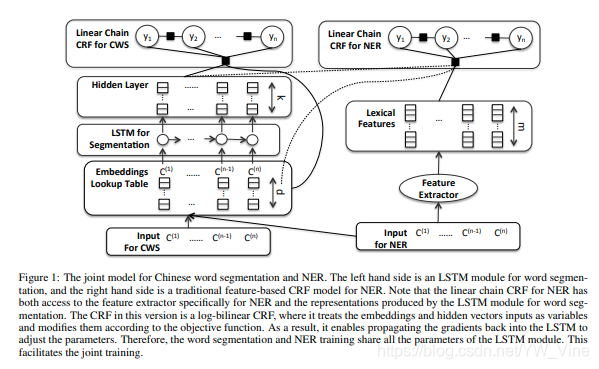
左边是中文分词的模型结构(LSTM+CRF),右边是NER的模型结构,NER模型的CRF前面的最后一层主要使用了三个特征:
- 字符的词性embedding
- 字符的embedding,即分词使用的字符embedding
- 分词模型中每个字符对应的隐藏层的输出(分词模型CRF层前面的一层输出)
训练时的目标函数如下:
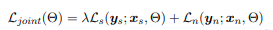
第一项表示分词模型的损失函数,第二项表示NER的损失函数,λ\lambdaλ表示权重,一般更关注NER的结果所以一般
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









