







YOLOv2
论文:YOLO9000: Better, Faster, Stronger
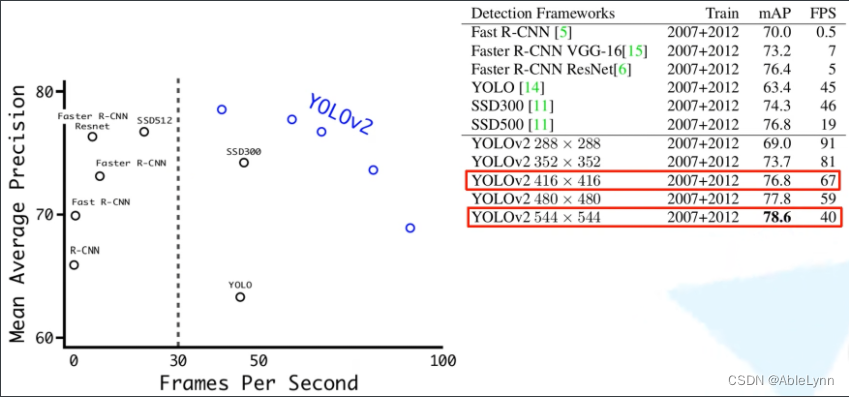
相较于YOLOv1的尝试:
- Batch Normalization
- 在YOLOv1的每个卷积层后加上了BN层,加了BN层后,对于训练收敛帮助很大,起到了对模型的正则化作用,BN层可以替代Dropout层
- High Resolution Classifier
- 采用更高分辨率的分辨器
- Convolutional With Anchor Boxes
- 使用基于Anchor偏移的目标边界框的预测方式
- Dimension Clusters
- Direct location prediction
- Fine-Grained Features
- 增加了PassThrough Layer层
- Multi-Scale Training
- 每迭代10个batch,就改变输入图像的大小,{320,352,…,608}的随机数,即32的整数倍,最小为320,最大为608
网络结构:其中主干网络为Darknet19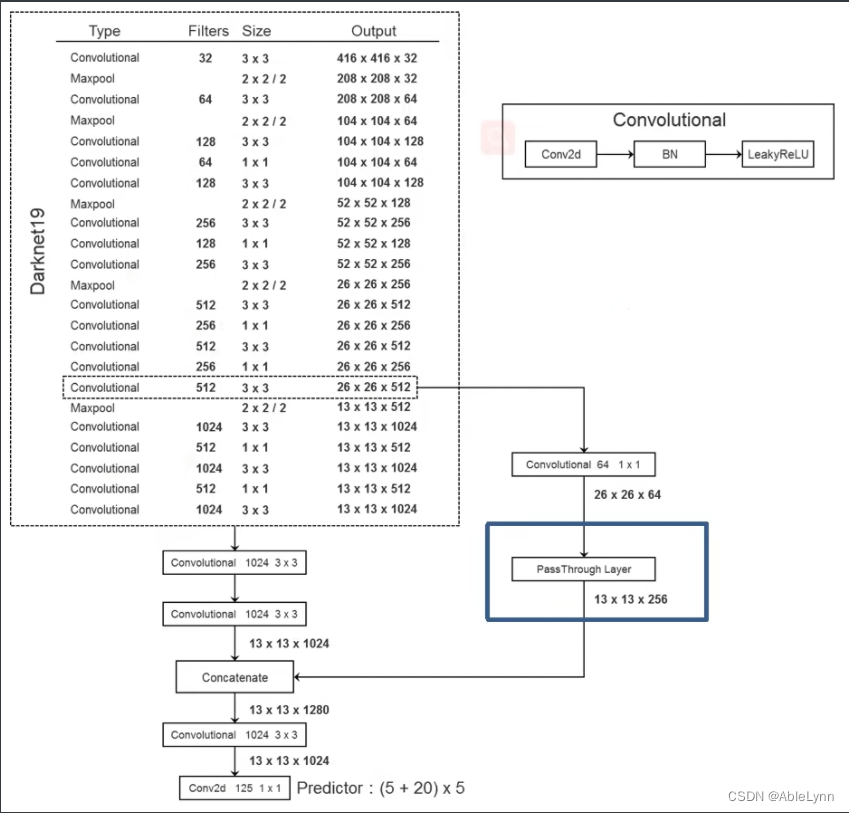
PassThrough Layer:将相对底层的26 * 26 * 512的特征矩阵经过1 * 1 * 64的卷积层得到的26 * 26 * 64的特征矩阵,经过PassThrough Layer得到13 * 13 *256的特征矩阵与相对高层的13 * 13 * 1024的特征矩阵进行融合(即深度方向进行拼接相加,1024+256=1280),得到13 * 13 * 1280的特征矩阵
即特征矩阵经过PassThrough Layer层后会W、H减半,然后深度变为4倍
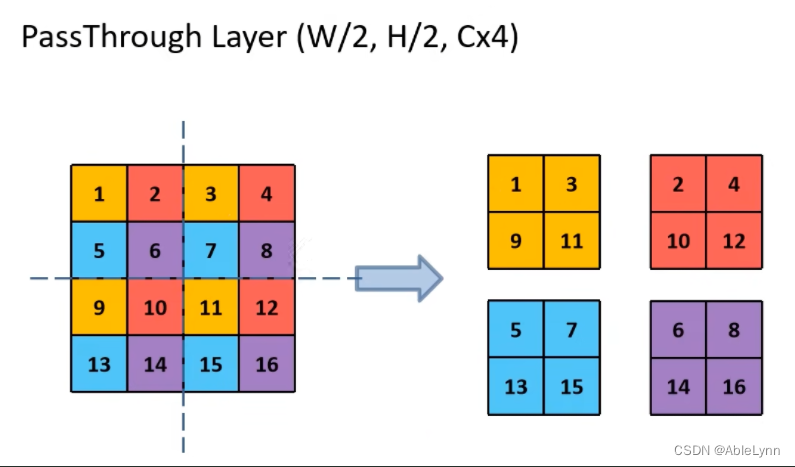
因为输入特征矩阵为416 * 416 * 32 最终得到的特征矩阵为 13 * 13 * 1024,即缩放因子为416 / 13 = 32,所以可以选择的输入图像大小为{320,352,…,608},即32的整数倍,最小为320,最大为608
Convolutional 是有 Conv2d + BN + LeakReLU 组成
注意:
最后的1 * 1的卷积层即为预测器,输出深度为(所检测数据集的类别数+(x,y,w,h, confidence)) * 5
论文中为125为:总共使用了5个Anchor,对于每个Anchor中有(x,y,w,h)、confidence以及对于VOC数据集中20个类别对应的分数,即(5+20) * 5















 3574
3574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









