






多视图/多模态的相关文章
文章目录
- 多视图/多模态的相关文章
- 多视图introduction
- 一、Multi-view Contrastive Graph Clustering
- 二、Multi-view Subspace Clustering via Partition Fusion
- 三 Multi-view Attributed Graph Clustering
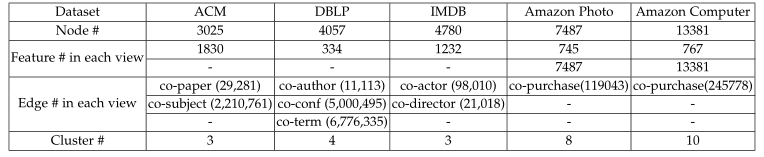
- 数据集
- 四 Contrastive Multi-View Representation Learning on Graphs
- Self-supervised Consensus Representation Learning for Attributed Graph 这种分为拓扑图和特征图的思路是否可行
- Self-supervised Contrastive Attributed Graph Clustering
- Multi-View Information-Bottleneck Representation Learning
- 数据集链接整理
多视图introduction
多视图的两个基本假设:视图之间的一致性和互补性。即Consistency and Complementarity.That is to say, there exists consistent information which is shared by all views and complementary knowledge that is not contained in all views.
分类
ref:二 introduction
1、co-training:最大化视图互信息达成最广泛共识
maximize the mutual agreement across all views and arrive at their broadest consensus
2、kernel-based methods:对不同视图使用对对应预定义的核,线性/非线性组合这些核
use pre-defined kernels corresponding to different
views and then combine these kernels either linearly or non-linearly in order to
improve the clustering performance
3、graph-based
graph-based methods have been derived from traditional spectral clustering with the help of some similarity measures
4、subspace clustering based
找到一个低维子空间使得所有数据点被正确分割
Subspace clustering tries to find underlying subspaces such that all data points
can be segmented correctly and each group fits into one of the low-dimensional
subspaces
基于这个文章进行拓展:
一、Multi-view Contrastive Graph Clustering
机器学习
https://proceedings.neurips.cc/paper/2021/file/10c66082c124f8afe3df4886f5e516e0-Paper.pdf
这个文章中存在什么可优化的方法?
数据集的分布特点是什么?
表达方面好像还有改进的空间

为什么S可以用来聚类呢?
S是一个一致性图,代表了所有样本之间的关系,它的维度是N*N,那么相对关系倒是也可以用来聚类
二、Multi-view Subspace Clustering via Partition Fusion
作者同时期发了另一篇文章,机器学习

包含的基本假设:
①multi-view clustering is that there exists a unique clustering pattern shared by all view
1. From abstract 动机
大部分多视图聚类的基本原理是把多视图集成到graph,然后用谱聚类算法得到最终结果。但是单个视图存在噪声或异构特征之间不一致,会导致性能可能下降。因此在现有结果的基础上**提出在划分空间中融合多视图信息,增强多视图的鲁棒性**。
具体的:生成多个分区并对它们进行集成已找到共享分区
2.已有的工作:
1、learn the sample affinity graph matrix of each view by deploying features of different views, and then build a consensus graph S
2、directly learn a common graph matrix S.Subsequently, spectral clustering algorithm [45, 46] is implemented on the graph Laplacian constructed by S to obtain the final clustering result
但是这些方法将S的学习和最后的聚类是分开的,这样学到的S经常是有噪音的,不能揭示数据之间真实关系,就会恶化下游聚类任务,导致次优
3.改进
为了把多视图信息integrating集成到单个图,本文提出 fuse partitions的方法。基于假设①,因此使用partition space会对噪声更具鲁棒性。即使图呗损坏或者污染,聚类也只会受到轻微影响。
具体来说,自适应的学习每个视图的权重,控制最终聚类贡献。The final clustering is achieved through a purposely designed weighting mechanism imposed on basic partitions.
因此总体贡献是:提出在partition space融合多视图信息,进一步发展一种consensus clustering。端到端模型,迭代学习每个视图的图,每个视图的partition,每个partition的权重,以及consensus clustering。四个子任务内在交互,互相增强
4.已有相关工作
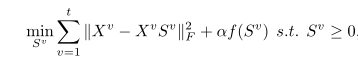
其中
S
v
S^v
Sv是自表达系数矩阵,把每个样本表示为其他样本的线性组合,因此S可以体现样本之间的相关性。然后用谱聚类算法。
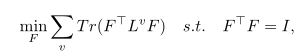
强制所有图共享一个唯一的聚类指示矩阵。也就是说不使用谱聚类而是使用学习指示矩阵的方法。
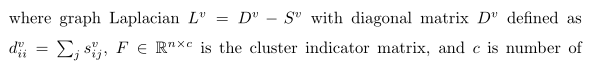
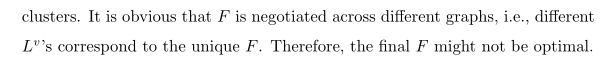
还有的通过直接对所有视图
S
v
S^v
Sv求平均以计算一致性图S,再谱聚类
还有这种
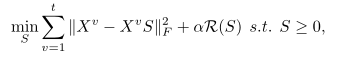
其中
R
(
S
)
R(S)
R(S)是个正则化项目,不同算法中不同。比如流行的低秩正则化,稀疏正则化。
本文提出通过融合分区集成多视图知识,具体来说为每个视图生成一个分区形成基本分区,然后根据设计的加权机制寻找共识聚类。每个分区将捕捉集群的内在结构,因此很容易找到所有分区之间的一个agreement,同时如果一个partition严重distorted,它就通过分配较小的权重减少影响,防止对聚类不利(鲁棒性)。
与其他集成聚类不同的时每个视图只生成一个分区。其次基本分区的集成方式不同,比如有的采用低秩稀疏分解发现视图的联系,检测噪声,然后外卖使用统一框架。
具体方法
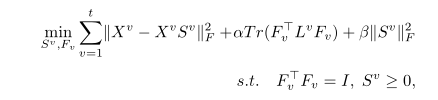

可以看到上面两个图,相当于每个视图都学到一个
F
v
F_v
Fv,由于不同视图的噪声或者特征的 一致性,这些划分矩阵一般情况下不同,那么下一步就是找到一个共识聚类。
为区别对待每个视图,引入加权机制
W
v
W_v
Wv体现v视图的重要度。然后提出这个优化目标
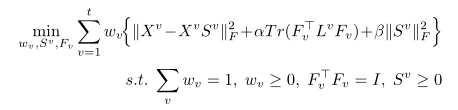

如果括号内的损失小,那么权重W就会大一些
这时候共识聚类即一个适合所有视图的分区,使用内积定义分区之间的距离,然后提出一个融合方法
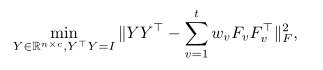
其中Y是一致性聚类指示矩阵
然后结合上面的两项损失,提出了PFSC最终的损失函数为



使用的数据集





还进行了参数敏感度分析
还通过对图像添加高斯噪声和Salt&-Pepper噪声验证鲁棒性
论文地址
论文地址:https://www.sciencedirect.com/science/article/pii/S0020025521000712
代码地址:https://github.com/LyuJC/PFSC
三 Multi-view Attributed Graph Clustering

还是同一个作者的文章,发表于2021 IEEE
针对具有属性和图的数据,提出多视图属性图聚类MAGC框架.创新点是:①利用图过滤技术实现平滑节点表示,不使用深度神经网络.②原始图可能存在噪声或者不完整,不能直接应用,所以考虑异构视图从数据中学习共识图.③设计一个新的正则化器,以一种灵活的方式探索高阶关系。
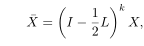
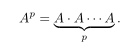
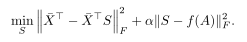
然后加入权重
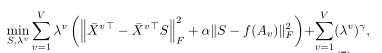

数据集

链接
https://github.com/sckangz/MAGC
思考
使用谱方法直接过滤得到embedding的这类问题,是否需要考虑好高阶关系的利用
PMLR 2020 GNN,对比学习,多视图,ref:218,看一下多视图使用深度学习的方法是怎么进行的
四 Contrastive Multi-View Representation Learning on Graphs

摘要
使用自监督的方法,通过对比图的结构视图来学习节点和图级别的表示,提出将试图数增加到连两个以上或者对比多尺度的编码不会提高性能???而 the best performance is achieved by contrasting encodings from first-order neighbors and a graph diffusion。
什么是图扩散网络
https://www.cnblogs.com/owoRuch/p/15600554.html
通过随机游走,不止使用一阶邻居。然后得到序列后对矩阵稀疏化,去掉一些边关系


图
方法
对比学习已经在图像分类等baseline取得了最先进的结果,但目前还不清楚如何把它应用到graphs数据,为了解决这个问题,引入一种自监督的方法训练图编码器,通过最大化不同图结构视图的互信息 maximizing MI between representations encoded from different structural views of graphs


数据集

评价
这个不是多视图的任务,而是通过数据增强增加视图,发现增强视图多于2个就不能提高performance了,the best performance通过对比一阶近邻和一般的图扩散编码来实现。contrasting encodings from first-order neighbors and a general graph diffusion。认为与可微分池(DiffPool)等层次图池方法hierarchical graph pooling methods相比,一个a simple graph readout layer在两个图和节点两个分类任务上都能获得更好的性能。认为applying regularization (except early-stopping) or normalization layers has a negative effect on the performance。
里面提到一个概念:拓扑关系和属性之间的关系应该是一致的
Self-supervised Consensus Representation Learning for Attributed Graph 这种分为拓扑图和特征图的思路是否可行
这是一篇无关多视图的论文,但是它是属性图的,可以稍微了解一下
https://github.com/topgunlcs98/SCRL

方法
分为两种图,分别是拓扑图和特征图


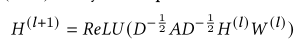
加入一个线性层C
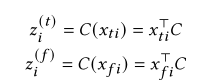
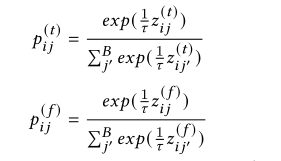

如何建立伪标签呢,即这个q是怎么获得的呢?本文将伪标签分配问题转换为最优传输问题,使用迭代Sinkhorn算法计算伪标签
Sinkhorn distances: Lightspeed computation of optimal transport.
https://zhuanlan.zhihu.com/p/340471751

建立了“交换预测”问题。假设拓扑图和特征图都会产生相同标签。因此,从一个图得到的伪标签可以用另一个图预测,准确的说是对每个节点,目标是最小化两对概率的交叉熵。
Self-supervised Contrastive Attributed Graph Clustering

方法


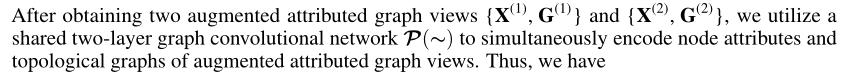
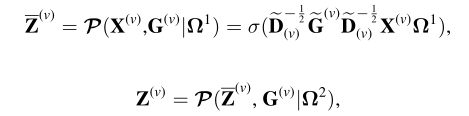

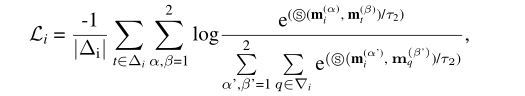




数据集

Multi-View Information-Bottleneck Representation Learning
搜索多视图表达学习的时候看到的,ref:1
https://blog.csdn.net/gandebeautiful/article/details/115999816
论文通过信息瓶颈原则,以及综合使用多视图各个视图之间的公共表征和单个视图的特定表征,来学习得到一个标签信息丰富和鲁棒性强的表征。传统的多视图处理往往是只关注于多个视图之间的公共信息,而忽略了单个视图也有利于后续任务的特定信息,因此本文综合考虑两者,并加入信息瓶颈原则,使得学习得到的表征去除冗余信息。
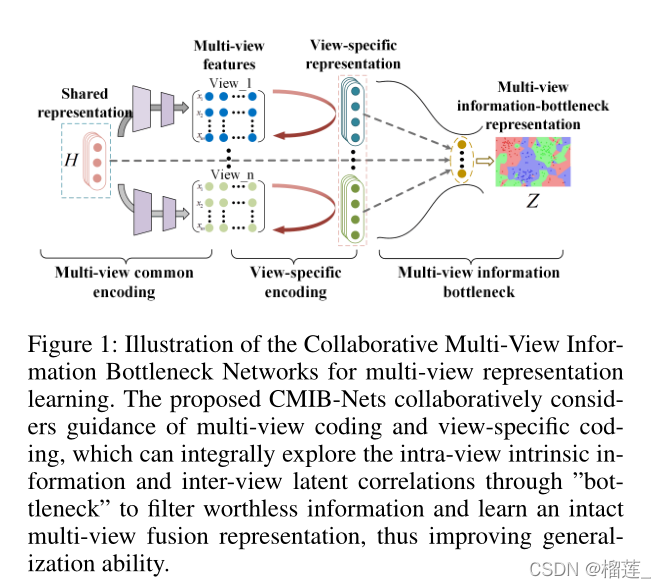
原始特征X,共享表示H,多视图信息瓶颈表示Z,特定视图表示S。探索不同视图的复杂关系和视图内的内在信息
共享表示:the multiple views are originated from an underlying latent representation
对所有的视图X学习到唯一一个共享表示,这个共享表示要达到能以一种稳定的方式重构每个视图。(这个共享表示可以描述不同视图共享的底层结构)。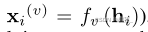
通常还会假设每个视图的共享潜在表示h_i是条件独立的
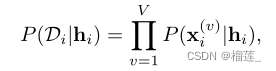
上式表示在所有视图中的联合分布,我们用条件h_i建模可能性。
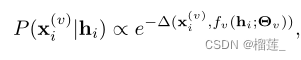


上面这个概率变换的目的就是说想把这个联合分布转换为可优化可衡量的方法,所以转换为(4),把概率分布的乘法变成相加,概率用损失(类似重构损失)来表示。
似然值的最大化相当于重构损失的最小化
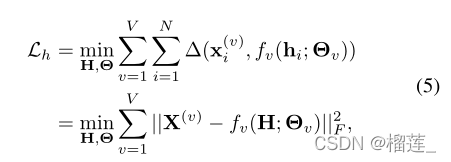
以上是对一致性的学习,现在要对互补性进行优化
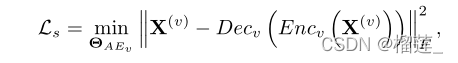
数据集链接整理
https://github.com/wangsiwei2010/awesome-multi-view-clustering















 961
961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









