






应用场景是什么?
CoT + RLHF + LoRA +
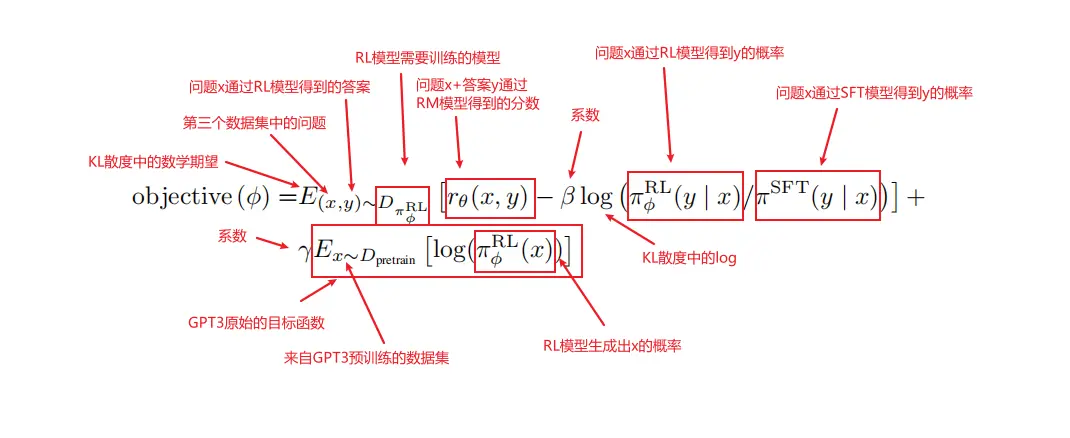
众所周知,整个 RLHF (基于人类反馈的强化学习) 分为这么三步:
SFT (Supervised Fine-Tuning): 有监督的微调,使用正常的 instruction following 或者对话的样本,来训练模型的基础对话、听从 prompt 的能力;
RM (Reward Modeling): 基于人类的偏好和标注,来训练一个能模拟人偏好的打分模型;
RL (Reinforcement Learning): 在前面的 SFT 模型的基础上,借助 RM 提供反馈,来不断通过 PPO 的强化学习框架来调整模型的行为。
Codebase
trl(一款采用强化学习训练Transformer语言模型和稳定扩散模型的全栈库):监督微调步骤(SFT)到奖励建模步骤(RM)再到近端策略优化(PPO)步骤。该库建立在Hugging Face 的 transformers 库之上。因此,可以通过 transformers 直接加载预训练语言模型。具体介绍
[github](https://github.com/huggingface/trl]
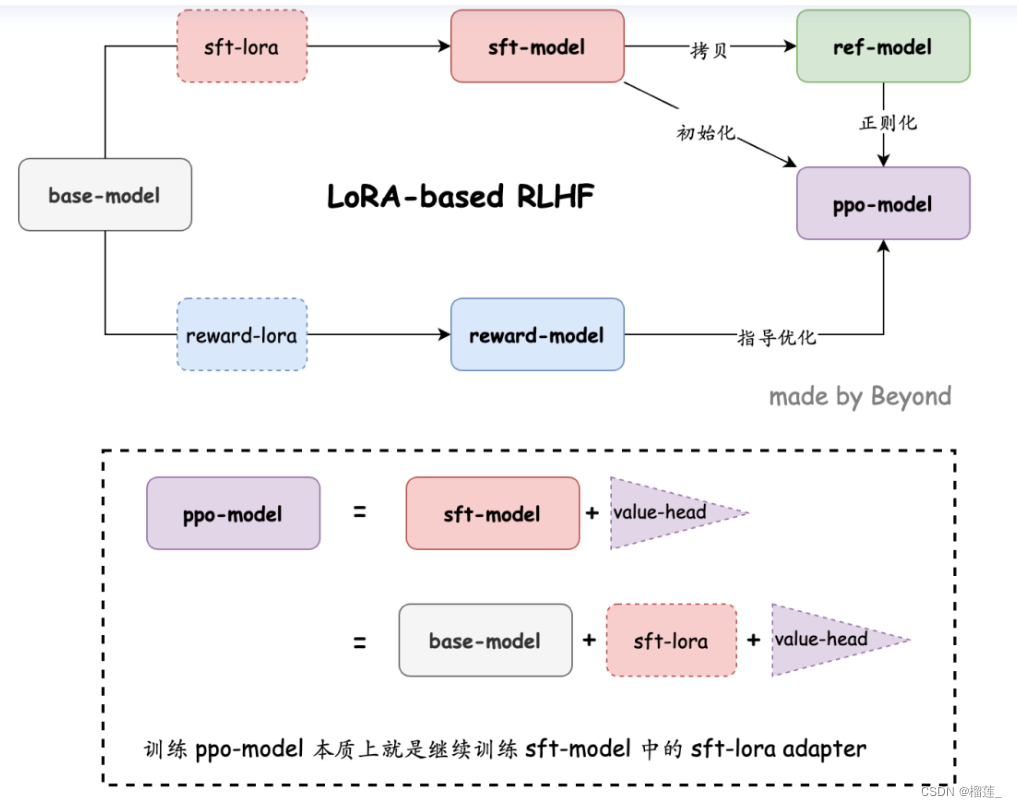
基于 LoRA 的 RLHF
基于 LoRA 的 RLHF: 记一次不太成功但有趣的百川大模型调教经历
h:
github
这个代码将LoRA和RLHF的训练过程相结合。从图中可以看出RL阶段的四个模型分别是:sft-model,ref-model,ppo-model, reward-model。
LLaVA-RLHF
通过使用图像-文本配对进行额外的预训练,或通过在专门的视觉指令调整数据集上进行微调,大型语言模型可以进入多模态领域,从而产生强大的大型多模态模型。然而,构建多模态模型存在一些障碍,其中最主要的是多模态数据和纯文本数据集之间的数量和质量差异。以LLaVA模型为例,它是从预训练的视觉编码器和针对指令进行调整的语言模型初始化的,比纯文本模型的训练实例要少得多,纯文本模型使用了超过1亿个实例涵盖了1800个任务。LLaVA仅仅是在15万个基于图像的人工对话中进行训练。由于这些数据的限制,由于这些数据限制,视觉和语言模式可能不一致。:https://www.atyun.com/57343.html
他们的一个重要贡献是将多模态对齐适应到被称为人类反馈强化学习的通用和可扩展对齐范式上,这种范式对于基于文本的人工智能代理已经证明了显著的有效性。为了对LMM进行微调,它收集人类偏好,重点是识别幻觉,并将这些偏好用于强化学习中。
https://llava-rlhf.github.io/
https://github.com/llava-rlhf/LLaVA-RLHF
其他相关链接
chatgpt的rlhf实现(有点复杂,没太看懂):https://blog.csdn.net/v_JULY_v/article/details/132939877
https://blog.csdn.net/Remixa/article/details/130576255
关于第三阶段的实现代码细节:没看明白 https://blog.csdn.net/Remixa/article/details/130666878

















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









