






大模型八股文
领域知识
transformer参数量计算

Norm
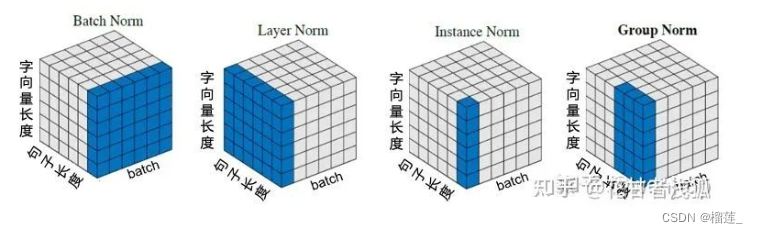
- Batch Norm:把每个Batch中,每句话的相同位置的字向量看成一组做归一化。
- Layer Norm:在每一个句子中进行归一化。
- Instance Norm:每一个字的字向量的看成一组做归一化。
- Group Norm:把每句话的每几个字的字向量看成一组做归一化。
其实只要仔细看上面的例子,就很容易能想到NLP中每一种norm的优缺点:
Batch Normalization(Batch Norm):缺点:在处理序列数据(如文本)时,Batch Norm可能不会表现得很好,因为序列数据通常长度不一,并且一次训练的Batch中的句子的长度可能会有很大的差异;此外,Batch Norm对于Batch大小也非常敏感。对于较小的Batch大小,Batch Norm可能会表现得不好,因为每个Batch的统计特性可能会有较大的波动。
Layer Normalization(Layer Norm):优点:Layer Norm是对每个样本进行归一化,因此它对Batch大小不敏感,这使得它在处理序列数据时表现得更好;另外,Layer Norm在处理不同长度的序列时也更为灵活。
Instance Normalization(Instance Norm):优点:Instance Norm是对每个样本的每个特征进行归一化,因此它可以捕捉到更多的细节信息。Instance Norm在某些任务,如风格迁移,中表现得很好,因为在这些任务中,细节信息很重要。缺点:Instance Norm可能会过度强调细节信息,忽视了更宏观的信息。此外,Instance Norm的计算成本相比Batch Norm和Layer Norm更高。
Group Normalization(Group Norm):优点:Group Norm是Batch Norm和Instance Norm的折中方案,它在Batch的一个子集(即组)上进行归一化。这使得Group Norm既可以捕捉到Batch的统计特性,又可以捕捉到样本的细节信息。此外,Group Norm对Batch大小也不敏感。缺点:Group Norm的性能取决于组的大小,需要通过实验来确定最优的组大小。此外,Group Norm的计算成本也比Batch Norm和Layer Norm更高。
RLHF
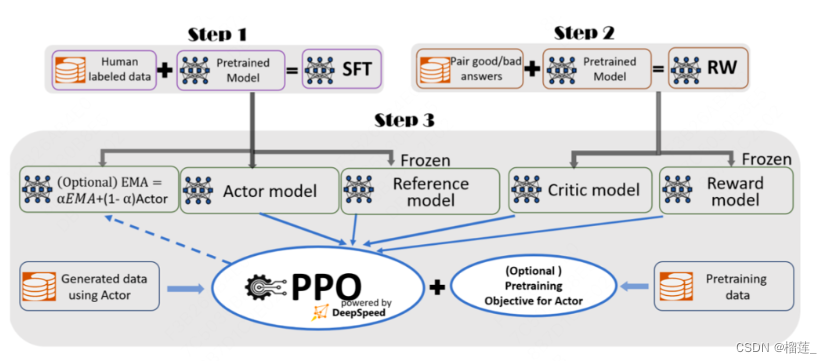
评测
大模型数据格式
[[#1 SFT(有监督微调)的数据集格式?|1 SFT(有监督微调)的数据集格式?]]
[[#2 RM(奖励模型)的数据格式?|2 RM(奖励模型)的数据格式?]]
[[#3 PPO(强化学习)的数据格式?|3 PPO(强化学习)的数据格式?]]
[[#4 找数据集哪里找?|4 找数据集哪里找?]]
[[#5 微调需要多少条数据?|5 微调需要多少条数据?]]
[[#6 有哪些大模型的训练集?|6 有哪些大模型的训练集?]]
[[#7 进行领域大模型预训练应用哪些数据集比较好?|7 进行领域大模型预训练应用哪些数据集比较好?]]
prefix LM 和 causal LM 区别是什么?
Prefix LM(前缀语言模型)和Causal LM(因果语言模型)是两种不同类型的语言模型,它们的区别在于生成文本的方式和训练目标。
Prefix LM:一种生成模型,它在生成每个词时都可以考虑之前的上下文信息。在生成时,前缀语言模型会根据给定的前缀(即部分文本序列)预测下一个可能的词。这种模型可以用于文本生成、机器翻译等任务。(Encoder 用的掩码,能看到「过去」和「未来」)
Causal LM:因果语言模型是一种自回归模型,它只能根据之前的文本生成后续的文本,而不能根据后续的文本生成之前的文本。在训练时,因果语言模型的目标是预测下一个词的概率,给定之前的所有词作为上下文。这种模型可以用于文本生成、语言建模等任务。
总结来说,前缀语言模型可以根据给定的前缀生成后续的文本,而因果语言模型只能根据之前的文本生成后续的文本。它们的训练目标和生成方式略有不同,适用于不同的任务和应用场景。
 https://blog.csdn.net/m0_64768308/article/details/128118706
https://blog.csdn.net/m0_64768308/article/details/128118706
大模型分词
大模型位置编码
对于transformer模型,位置编码是必不可少的。因为attention模块是无法捕捉输入顺序的,无法区分不同位置的token。位置编码分为绝对位置编码和相对位置编码。
最直接的方式是训练式位置编码**,将位置编码当作可训练参数,训练一个位置编码向量矩阵**。GPT3就采用了这种方式。训练式位置编码的缺点是没有外推性,即若训练时最大序列长度为2048,在推断时最多只能处理长度为2048的序列,超过这个长度就无法处理了。
绝对位置编码(sinusoidal),旋转位置编码(RoPE),以及相对位置编码ALiBi
sinusoidal位置编码
绝对位置编码是直接将序列中每个位置的信息编码进模型的,从而使模型能够了解每个元素在序列中的具体位置。原始Transformer提出时采用了sinusoidal位置编码,通过正弦和余弦的函数结构使得模型捕获位置之间的复杂关系,且这些编码与序列中每个位置的绝对值有关。
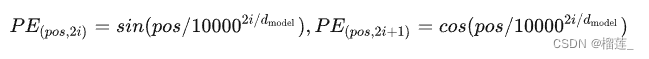
其中,pos表示位置,
d
m
o
d
e
l
d_{model}
dmodel代表embedding的维度,
2
i
,
2
i
+
1
2i,2i+1
2i,2i+1代表的是embedding不同位置的索引。
原始 Transformer 的位置编码虽然是基于绝对位置的,但其数学结构使其能够捕获一些相对位置信息。使用正弦和余弦函数的组合为每个位置创建编码,波长呈几何级数排列,意味着每个位置的编码都是独特的。然而,正弦和余弦函数的周期性特性确保了不同位置之间的编码关系是连续且平滑的。
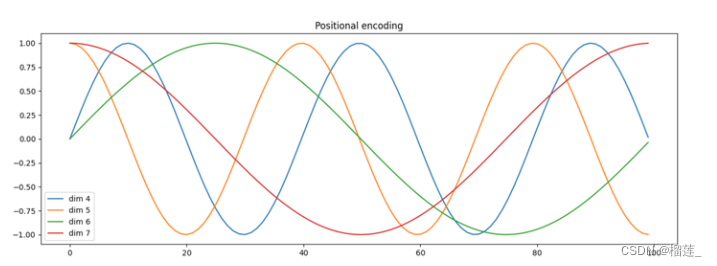
Rotary Position Embedding
总的来说就是在Q,K处注入位置信息。
sinusoidal位置编码对相对位置关系的表示还是比较间接的,那有没有办法更直接的表示相对位置关系呢?那肯定是有的,而且有许多不同的方法,旋转位置编码(Rotary Position Embedding,RoPE)是一种用绝对位置编码来表征相对位置编码的方法,并被用在了很多大语言模型的设计中。
旋转位置编码RoPE训练式的位置编码作用在token embedding上,而旋转位置编码RoPE作用在每个transformer层的self-attention块,在计算完Q/K之后,旋转位置编码作用在Q/K上,再计算attention score。旋转位置编码通过绝对编码的方式实现了相对位置编码,有良好的外推性。值得一提的是,RoPE不包含可训练参数。LLaMA、GLM-130B、PaLM等大语言模型就采用了旋转位置编码RoPE。
具体推导可以见视频,我没看明白

Jianlin Su提出旋转位置编码,这个做法被OPT,LLaMA等所采用,主要的做法就是:在每一层的self-attention计算中,我们对query和key做sinusoidal乘法。 llama的embedding我们不需要学习,这样做的好处呢,就是我们不需要在训练中去学习embedding,即可以节省内存消耗,又可以在推理时cover token长度远远长于训练时token的情况,效果也比较好。
ALiBi
ALiBi(Attention with Linear Biases)[12]也是作用在每个transformer层的self-attention块,如下图所示,在计算完attention score后,直接为attention score矩阵加上一个预设好的偏置矩阵。这里的偏置矩阵是预设好的,固定的,不可训练。这个偏置根据q和k的相对距离来惩罚attention score,相对距离越大,惩罚项越大。相当于两个token的距离越远,相互贡献就越小。ALiBi位置编码有良好的外推性。BLOOM就采用了这种位置编码。
本文的做法是不添加position embedding,然后添加一个静态的不学习的bias,如下图:
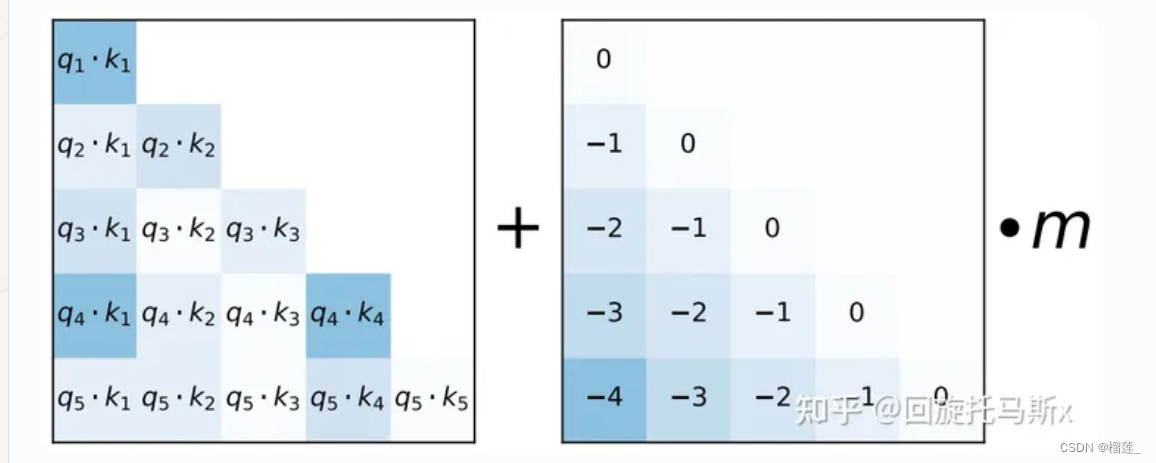
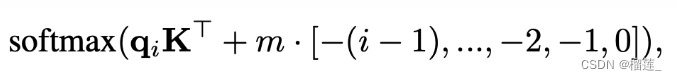
怎么理解呢,就是在query和key做矩阵点乘的基础上,加上一个常数负值,比如距离当前位置前1位为-1, 前两位为-2,这些常数要乘上 权重 m
大模型正则化
Layer norm
如下图所示,按照layer normalization的位置不同,可以分为post layer norm和pre layer norm。
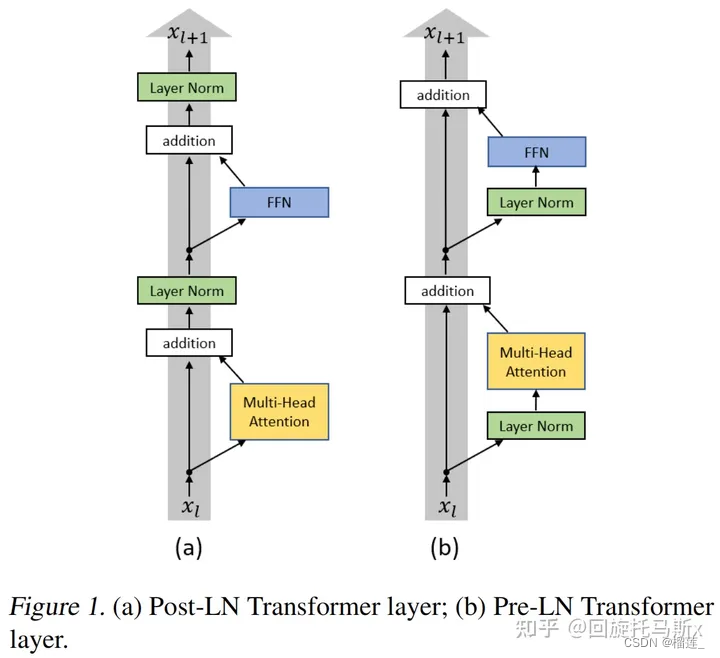
post layer norm。在原始的transformer中,layer normalization是放在残差连接之后的,称为post LN。使用Post LN的深层transformer模型容易出现训练不稳定的问题。如下图所示,post LN随着transformer层数的加深,梯度范数逐渐增大,导致了训练的不稳定性。
pre layer norm。改变layer normalization的位置,将其放在残差连接的过程中,self-attention或FFN块之前,称为“Pre LN”。如下图所示,Pre layer norm在每个transformer层的梯度范数近似相等,有利于提升训练稳定性。相比于post LN,使用pre LN的深层transformer训练更稳定,可以缓解训练不稳定问题。但缺点是pre LN可能会轻微影响transformer模型的性能 大语言模型的一个挑战就是如何提升训练的稳定性。为了提升训练稳定性,GPT3、PaLM、BLOOM、OPT等大语言模型都采用了pre layer norm。
RMS norm
layer normalization重要的两个部分是平移不变性和缩放不变性。有人认为layer normalization取得成功重要的是缩放不变性,而不是平移不变性。因此,去除了计算过程中的平移,只保留了缩放,进行了简化,提出了RMS Norm(Root Mean Square Layer Normalization),即均方根norm。
相比于正常的layer normalization,RMS norm去除了计算均值进行平移的部分,计算速度更快,效果基本相当,甚至略有提升。Gopher、LLaMA、T5等大语言模型都采用了RMS norm。

Deep Norm

大模型激活函数
广泛使用的激活函数有gelu(Gaussian Error Linear Unit)函数和swish函数。swish函数是一种自门控激活函数。

大模型
垂直领域大模型落地思考
包含
- 领域微调数据构建之数据的生成:Self-Instruct,多轮对话,Self-QA,Self-KG
- 数据混合:hybrid-tuning的策略
- 减缓幻觉:如何让大模型的生成结果减缓幻觉,同时如何检测幻觉,并在后处理阶段进行消除。Generate with Citation(生成时引用,用户自己可以通过提供的参考快速判断回答对不对),**Factual Consistency Evaluation(**事实一致性评估)属于自然语言推理任务Natural Language Inference(NLI)的一种。具体是给定一个前提知识和一个猜想,判断这个猜想与前提知识的关系,是包含,无关,还是矛盾。知识召回:
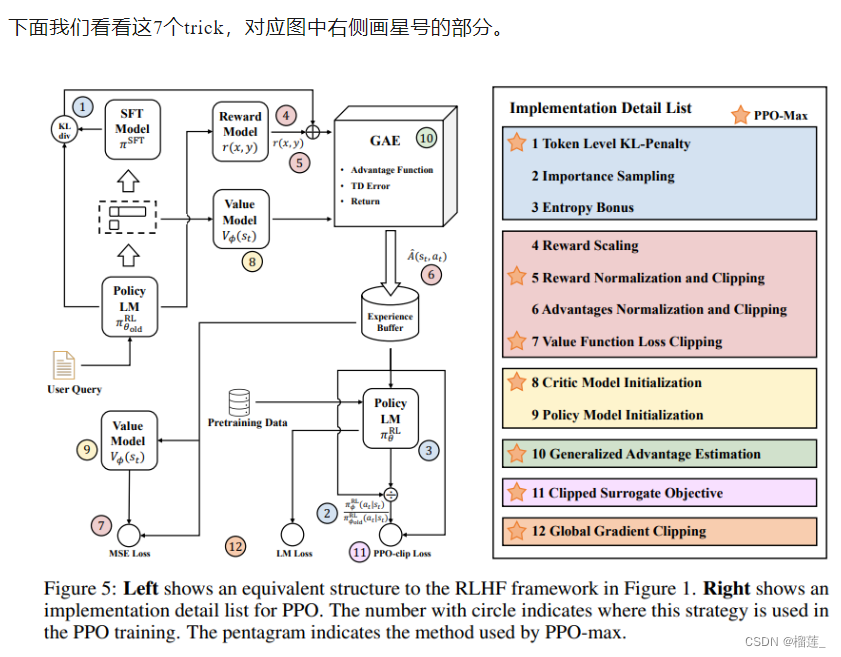
大模型RLHF的trick
首先并不是RM的分数越高越好,PPO经常容易训崩,表现形式为要么训着训着不听话,要么变成停不下来的复读机,输出到后面没有逻辑直到maxlen,要么变成哑巴,直接一个eosid躺平。因此原始的PPO非常难训,对SFT基模型和RM的训练数据以及采样prompt的数据要求很高,参数设置要求也很高。因此复旦MOSS提出了7个trick如下图。用的东西还是模型的老三样,训练过程裁剪,初始化,loss改进,主要集中在如何能让RLHF更好调。
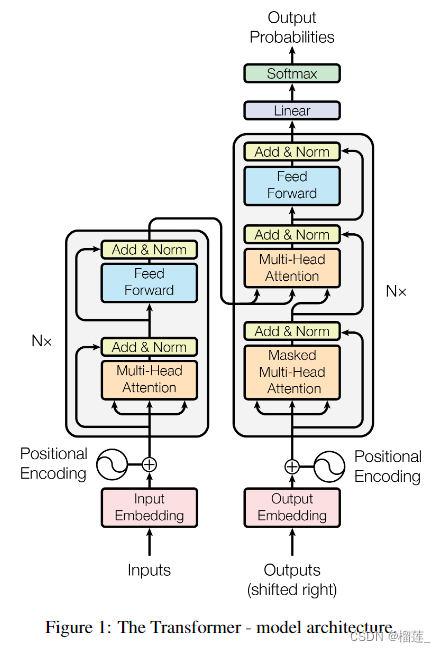
transformer具体结构
Transformer的结构分为encoder和decoder两部分。标准的 Transformer 模型主要由两个模块构成:
Encoder(左边):负责理解输入文本,为每个输入构造对应的语义表示(语义特征);
Decoder(右边):负责生成输出,使用 Encoder 输出的语义表示结合其他输入来生成目标序列。
Encoder和Decoder的区别在于它们的输入和输出以及它们的功能。Encoder的输入是输入序列,输出是每个位置的隐藏向量表示;Decoder的输入是Encoder的输出和前面生成的部分输出序列,输出是生成的下一个位置的词。Encoder用于编码输入信息,Decoder用于生成输出信息。
这两个模块可以根据任务的需求而单独使用:
纯 Encoder 模型:适用于只需要理解输入语义的任务,例如句子分类、命名实体识别;
纯 Decoder 模型:适用于生成式任务,例如文本生成;
Encoder-Decoder 模型或 Seq2Seq 模型:适用于需要基于输入的生成式任务,例如翻译、摘要。Transformer 模型不同分支的代表模型
以encoder部分训练为代表的是BERT,以decoder部分训练为代表的就是后面的GPT系列。
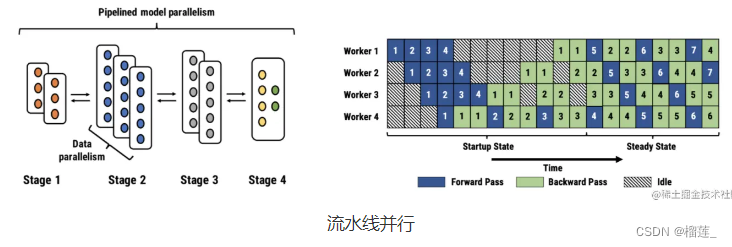
深度学习的三种并行方式:数据并行,模型并行,流水线并行
数据并行 (Data Parallelism)
模型/张量并行 (Model/Tensor Parallelism),注意这个术语在这几年的发展中产生了一些概念上的转变,现在其实人们所说的模型并行更多是指张量并行
流水线并行 (Pipeline Parallelism):理论上来讲也是模型并行的一种方式,只是在时间域上进行了设备的复用
数据并行
当模型规模足够小且单个 GPU 能够承载得下时,数据并行就是一种有效的分布式训练方式。因为每个 GPU 都会复制一份模型的参数,我们只需要把训练数据均分给多个不同的 GPU,然后让每个 GPU 作为一个计算节点独立的完成前向和反向传播运算。
数据并行不仅通信量较小,而且可以很方便的做通信计算重叠,因此可以取得最好的加速比。
模型并行
如果模型的规模比较大,单个 GPU 的内存承载不下时,我们可以将模型网络结构进行拆分,将模型的单层分解成若干份,把每一份分配到不同的 GPU 中,从而在训练时实现模型并行。
训练过程中,正向和反向传播计算出的数据通过使用 All gather 或者 All reduce 的方法完成整合。这样的特性使得模型并行成为处理模型中大 layer 的理想方案之一。**然而,深度神经网络层与层之间的依赖,使得通信成本和模型并行通信群组中的计算节点 (GPU) 数量正相关。**其他条件不变的情况下,模型规模的增加能够提供更好的计算通信比。
流水线并行
流水线并行,可以理解为层与层之间的重叠计算,也可以理解为按照模型的结构和深度,将不同的 layer 分配给指定 GPU 进行计算。相较于数据并行需要 GPU 之间的全局通信,流水线并行只需其之间点对点地通讯传递部分 activations,这样的特性可以使流水并行对通讯带宽的需求降到更低。
然而,流水并行需要相对稳定的通讯频率来确保效率,这导致在应用时需要手动进行网络分段,并插入繁琐的通信原语。同时,流水线并行的并行效率也依赖各卡负载的手动调优。这些操作都对应用该技术的研究员提出了更高的要求。
Deepspeed分布式训练的了解,zero 0-3(Optimizer state sharding)的了解。
https://blog.csdn.net/weixin_43301333/article/details/127237122
https://juejin.cn/post/7108974938299564039
在数据并行,模型并行,流水并行三种并行方式中,数据并行因其易用性,得到了最为广泛的应用。然而,数据并行会产生大量冗余 Model States 的空间占用。ZeRO 的本质,是在数据并行的基础上,对冗余空间占用进行深度优化。
ZeRO 就是为了解决 Model States 而诞生的一项技术。首先,我们来聊一下模型在训练过程中 Model States 是由什么组成的:
-
Optimizer States:Optimizer States 是 Optimizer 在进行梯度更新时所需要用到的数据,例如 SGD 中的 Momentum 以及使用混合精度训练时的 Float32 Master Parameters。
-
Gradient:在反向传播后所产生的梯度信息,其决定了参数的更新方向。
-
Model Parameter:模型参数,也就是我们在整个过程中通过数据“学习”的信息。
混合精度
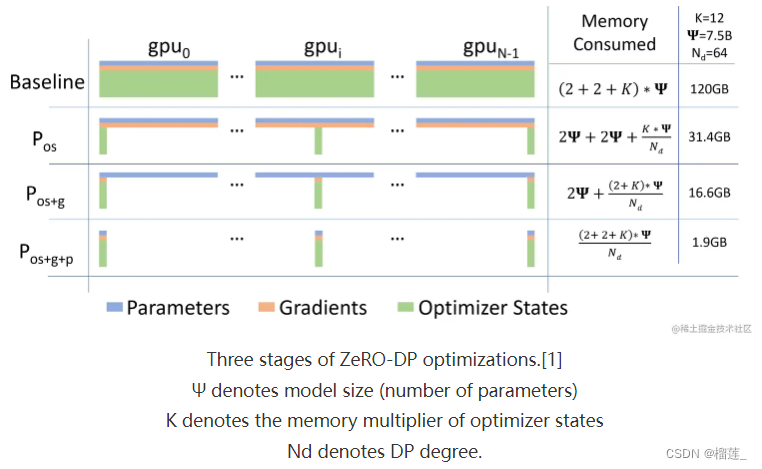
在传统数据并行下,每个进程都使用同样参数来进行训练。每个进程也会持有对 Optimizer States 的完整拷贝,同样占用了大量显存。在混合精度场景下,以参数量为 Ψ 的模型和 Adam optimzier 为例,Adam 需要保存:
- Float16 的参数 和 梯度 的备份。这两项分别消耗了 2Ψ 和 2Ψ Bytes 内存;(1 Float16 = 2 Bytes)
- Float32的参数、Momentum、Variance备份,对应到 3 份 4Ψ 的内存占用。(1 Float32 = 4 Bytes)
最终需要 2Ψ + 2Ψ + KΨ = 16Ψ bytes 的显存。一个 7.5B 参数量的模型,就需要至少 120GB 的显存空间才能装下这些 Model States。当数据并行时,这些重复的 Model States 会在 N 个 GPU 上复制 N 份。
ZeRO 则在数据并行的基础上,引入了对冗余 Model States 的优化。使用 ZeRO 后,各个进程之后只保存完整状态的 1/GPUs,互不重叠,不再存在冗余。在本文中,我们就以这个 7.5B 参数量的模型为例,量化各个级别的 ZeRO 对于内存的优化表现。
ZeRO 的三个级别
相比传统数据并行的简单复制,ZeRO通过将模型的参数、梯度和Optimizer State划分到不同进程来消除冗余的内存占用。
ZeRO 有三个不同级别,分别对应对 Model States 不同程度的分割 (Paritition):
ZeRO-1:分割 Optimizer States;
ZeRO-2:分割 Optimizer States 与 Gradients;
ZeRO-3:分割 Optimizer States、Gradients 与 Parameters;
Zero-1:分割Optimizer states
Optimizer在进行梯度更新时,会使用参数与Optimizer States计算新的参数。而在正向或反向传播中,Optimizer States 并不会参与其中的计算。
因此,我们完全可以让每个进程只持有一小段 Optimizer States,利用这一小段 Optimizer States 更新完与之对应的一小段 参数 后,再把各个小段拼起来合为完整的模型参数。ZeRO-1 中正是这么做的:
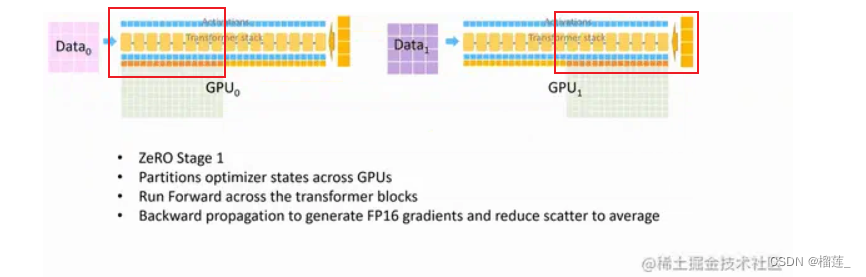
总的来说,zero0首先是将优化器状态Optimizer states进行分割,让每个GPU只持有一小段Optimizer states,这部分Optimizer states更新与之对应的一小段参数后,再把各个小段拼起来做完整的模型参数。
ZeRO-2:分割 Optimizer States 与 Gradients
ZeRO-1 将 Optimizer States 分小段储存在了多个进程中,所以在计算时,这一小段的 Optimizer States 也只需要得到进程所需的对应一小段 Gradient 就可以。遵循这种原理,和 Optimizer States 一样,ZeRO-2 也将 Gradient 进行了切片:
在一个 Layer 的 Gradient 都被计算出来后:
- Gradient 通过 AllReduce 进行聚合。 (类似于 DDP)
- 聚合后的梯度只会被某一个进程用来更新参数,因此其它进程上的这段 Gradient 不再被需要,可以立马释放掉。(按需保留)
这样就在 ZeRO-1 的基础上实现了对 Gradient 的切分。
通过 ZeRO-2 对 Gradient 和 Optimizer States 的分段化储存,7.5B 参数量的模型内存占用将由 ZeRO-1 中 31.4GB 进一步下降到 16.6GB。
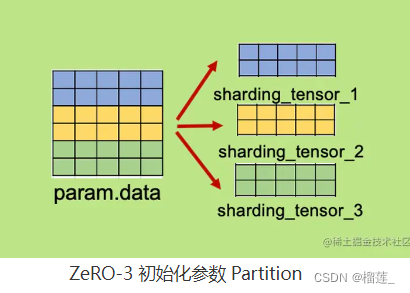
ZeRO-3:分割 Optimizer States、Gradients 与 Parameters
当 Optimizer States 和 Gradient 都被分布式切割分段储存和更新之后,剩下的就是 Model Parameter 了。
ZeRO-3 通过对 Optimizer States、Gradient 和 Model Parameter 三方面的分割,**从而使所有进程共同协作,只储存一份完整 Model States。**其核心思路就是精细化通讯,按照计算需求做到参数的收集和释放。
对于CLIP的了解
四亿图文对,进行图文对比学习。
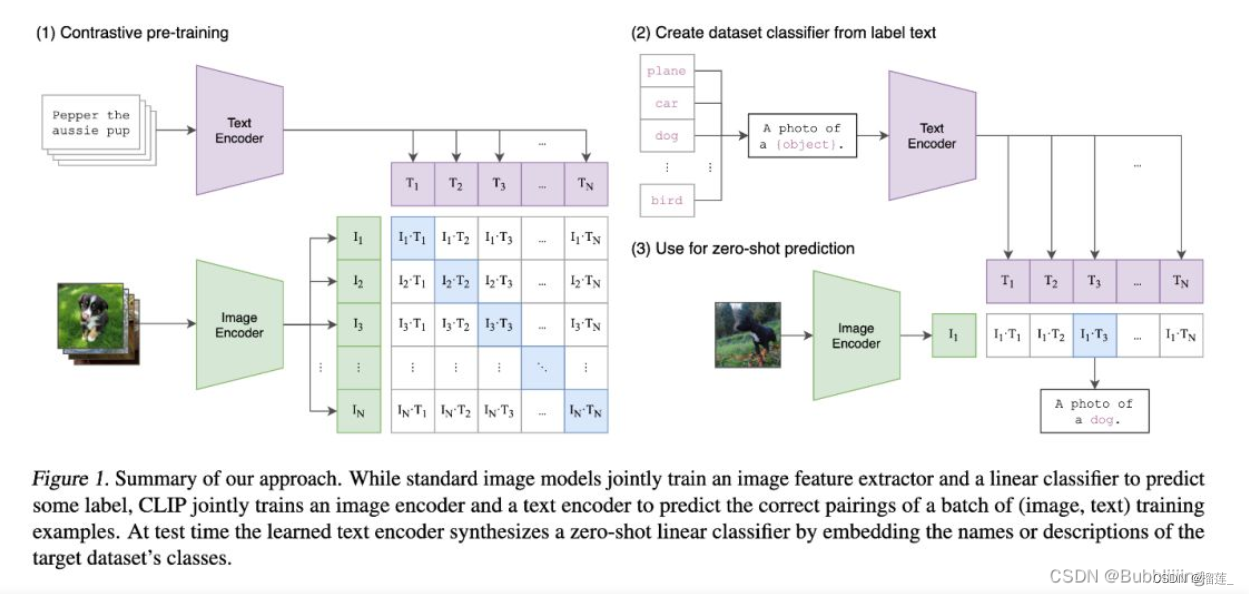
训练部分的思路和前面介绍的一样。
假设一个批次中有64个文本图像对,此时我们会同时获得64个图片和64个文本,首先我们从64个文本图像对中取出一个文本图像对,成对的文本图像对是天然的正样本,它们是配对的。
而对于这个样本的文本来讲,其它63个图像都为负样本,它们是不配对的。
而对于这个样本的图像来讲,其它63个文本都为负样本,它们是不配对的。
对比学习损失(InfoNCE loss):InfoNCE(Noise-Contrastive Estimation for Information Maximization) loss 是一种用于自监督学习的损失函数,通常用于学习具有良好表示的模型。它的设计基于最大化正样本(positive sample)与负样本(negative sample)之间的信息量。

def forward(self, image, text):
image_features = self.encode_image(image)
text_features = self.encode_text(text)
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
return logits_per_image, logits_per_text
# 训练的代码如下,仅仅截取部分用于理解
def fit_one_epoch(...):
...
# 这里不使用logits_per_text是因为dp模式的划分有问题,所以使用logits_per_image出来的后转置。
logits_per_image, _ = model_train(images, texts)
logits_per_text = logits_per_image.t()
labels = torch.arange(len(logits_per_image)).long().to(images.device)
loss_logits_per_image = nn.CrossEntropyLoss()(logits_per_image, labels)
loss_logits_per_text = nn.CrossEntropyLoss()(logits_per_text, labels)
loss = loss_logits_per_image + loss_logits_per_text
...
伪代码

对比学习的InfoNCE和交叉熵损失CrossEntroyLoss的关系
说几种对比学习的损失函数,以及它们的特点和优缺点
https://www.flyai.com/article/828
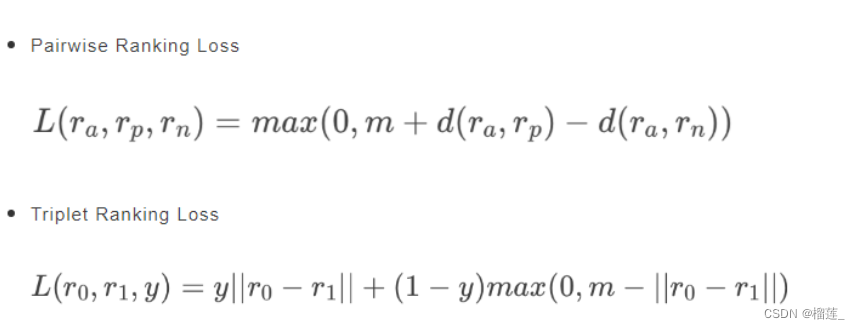

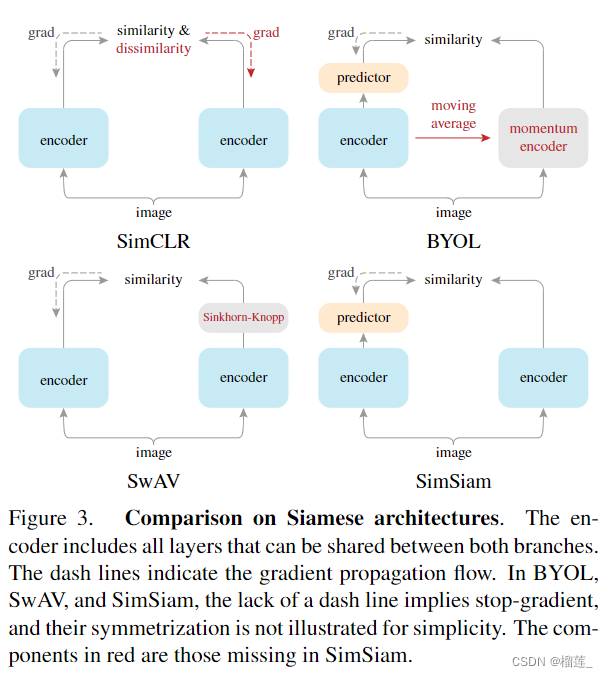
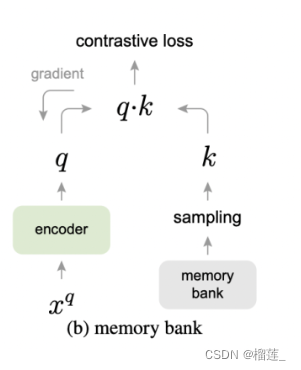
一文梳理无监督对比学习(MoCo/SimCLR/SwAV/BYOL/SimSiam)
想让对比学习效果好,一个核心点是扩大对比样本(负样本)的数量。
总结了对比学习的4种基本训练结构,包括End-to-End、Memory Bank、Momentum Encoder以及In-Batch Negtive,以及各自的优缺点。对比学习训练方式发展的核心是,如何实现量级更大、质量更好、更平稳的负样本表示。通过优化负样本,可以显著提升对比学习的效果。
方法角度
损失函数角度
Info NCE、Cross entropy
对比学习(Contrastive Learning)的目标是通过比较同一样本的不同表示或不同样本的相似性来学习有意义的表示。在对比学习中,损失函数起着至关重要的作用,下面是几种常见的对比学习损失函数及其特点和优缺点:
Triplet Loss(三元组损失):
特点: 通过比较锚点(Anchor)、正样本(Positive)和负样本(Negative)之间的距离来进行训练。目标是使锚点与正样本的距离小于锚点与负样本的距离。
优点: 直观易懂,易于理解。在许多早期的对比学习方法中被广泛使用。
缺点: 存在“易于选择”的问题,即选择合适的三元组对对训练的效果很关键。这可能导致训练过程的不稳定性。
Contrastive Loss(对比损失):
特点: 通过最大化正样本的相似性并最小化负样本的相似性,通常使用余弦相似度或欧氏距离作为相似性度量。
优点: 相对于三元组损失,更容易训练,不需要精心挑选三元组。
缺点: 随着样本数量的增加,计算所有正负样本对之间的相似性将变得非常昂贵。
InfoNCE Loss(Noise-Contrastive Estimation Loss):
特点: 基于信息论的思想,通过最大化正样本的似然概率和最小化负样本的似然概率来进行训练。
优点: 有效地处理了负样本的采样问题,减少了计算量。
缺点: 依赖于选择合适的负样本,对噪声的敏感性较强。
SimCLR Loss(SimCLR 损失):
特点: 使用对称性的对比学习损失,通过最大化正样本的相似性和最小化负样本的相似性来学习表示。
优点: 在大规模数据集上表现良好,易于实现。使用了数据扩充(data augmentation)来增加正样本对的多样性。
缺点: 需要大量的计算资源,训练较慢。
Moco Loss(Momentum Contrast 损失):
特点: 通过使用动量更新的目标网络和当前网络之间的比较来进行对比学习。
优点: 通过维护一个动量更新的目标网络,可以提高模型的鲁棒性,减轻训练中的噪声。
缺点: 需要额外的超参数来调整动量,训练过程中对于负样本的选择也需要关注。
每种损失函数都有其适用的场景和优缺点,选择合适的对比学习损失函数通常依赖于具体的任务和数据集。在实际应用中,通常需要根据具体情况进行实验和调优。
说说大模型生成采样的几种方式,它们的特点和优缺点比较
包括贪心算法、n贪心搜索/采样(greedy search/sampling)、集束搜索(beam search)、TopK采样等
Greedy Search
方式:每一时间步都选择概率最大的词。
参数设置:do_sample = False, num_beams = 1
缺点:
1、生成文本重复
2、不支持生成多条结果。 当num_return_sequences参数设置大于1时,代码会报错,说greedy search不支持这个参数大于1
Random Sampling
随机采样(Random Sampling):按照概率分布随机选择一个单词。这种方法可以增加生成的多样性,但是可能会导致生成的文本不连贯和无意义。
Beam-search(定向搜索)
方式:每一时间步选择num_beams个词,并从中最终选择出概率最高的序列。
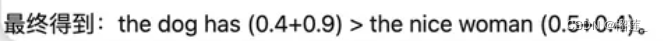
参数设置:do_sample = False, num_beams>1
缺点:虽然结果比贪心搜索更流畅,但是仍然存在生成重复的问题
Multinomial sampling(多项式采样)
方式:每一个时间步,根据概率分布随机采样字(每个概率>0的字都有被选中的机会)。
参数:do_sample = True, num_beams = 1
优点:解决了生成重复的问题,但是可能会出现生成的文本不遵守基本的语法
Beam-search multinomial sampling
方式:结合了Beam-search和multinomial sampling的方式,每个时间步从num_beams个字中采样
参数:do_sample = True, num_beams > 1
其他trick
惩罚重复
方式:在每步时对之前出现过的词的概率做出惩罚,即降低出现过的字的采样概率,让模型趋向于解码出没出现过的词
参数:repetition_penalty(float,取值范围>0)。默认为1,即代表不进行惩罚。值越大,即对重复的字做出更大的惩罚
代码实现逻辑:如果字的概率score<0,则score = score*penalty, 概率会越低; 如果字的概率score>0, 则则score = score/penalty,同样概率也会变低。
惩罚n-gram
方式:限制n-gram在生成结果中出现次数
参数:no_repeat_ngram_size,限制n-gram不出现2次。 (no_repeat_ngram_size=6即代表:6-gram不出现2次)
N-gram 是自然语言处理中一种用来表示文本或语言序列的方法,它是一种基于连续子序列的模型。在 N-gram 模型中,N 表示连续的子序列的长度。
一个 N-gram 就是一个长度为 N 的子序列,通常是一个词语序列。常见的有 unigram(1-gram)、bigram(2-gram)、trigram(3-gram)等。以 bigram 为例,如果有一个句子 “I love natural language processing”,其 bigrams 就是:
I love
love natural
natural language
language processing
N-gram 模型的基本思想是,文本中的词语或字符并不是独立的,而是与其前面的若干个词语或字符相关。因此,通过捕捉这些相邻词语之间的关联性,N-gram 模型可以在一定程度上理解语言的上下文。
在应用 N-gram 模型时,需要考虑 N 的选择,选择合适的 N 取决于具体任务和语料库的性质。较小的 N 可能更适用于捕捉局部的语境,而较大的 N 则可能更适用于捕捉更长范围的上下文关系。
限制采样Trick
Temperature
方式:通过温度,控制每个字的概率分布曲线。温度越低,分布曲线越陡峭,越容易采样到概率大的字。温度越高,分布曲线越平缓,增加了低概率字被采样到的机会。
参数:temperature(取值范围:0-1)设的越高,生成文本的自由创作空间越大;温度越低,生成的文本越偏保守。
Top-K采样
方式:每个时间步,会保留topK个字,然后对topk个字的概率重新归一化,最后在重新归一化后的这K个字中进行采样
参数:top_k
缺点:在分布陡峭的时候仍会采样到概率小的单词,或者在分布平缓的时候只能采样到部分可用单词
Top-P采样(又称Nucleus Sampling)
方式:每个时间步,按照字出现的概率由高到底排序,当概率之和大于top-p的时候,就不取后面的样本了。然后对取到的这些字的概率重新归一化后,进行采样。
参数:top_p (取值范围:0-1)
top-P采样方法往往与top-K采样方法结合使用,每次选取两者中最小的采样范围进行采样,可以减少预测分布过于平缓时采样到极小概率单词的几率。
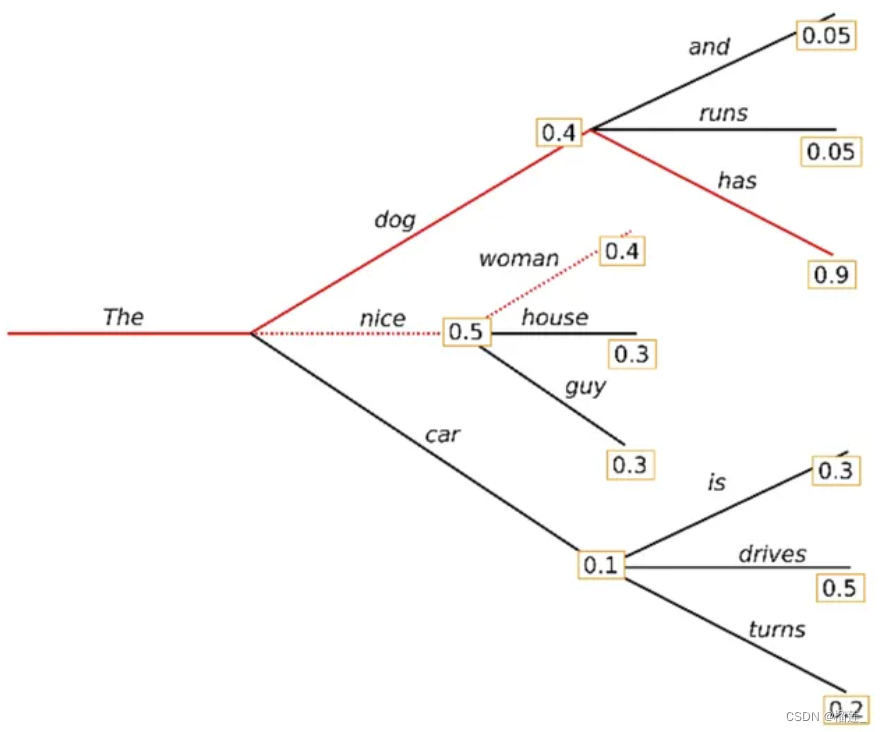
联合采样(top-k & top-p & Temperature)
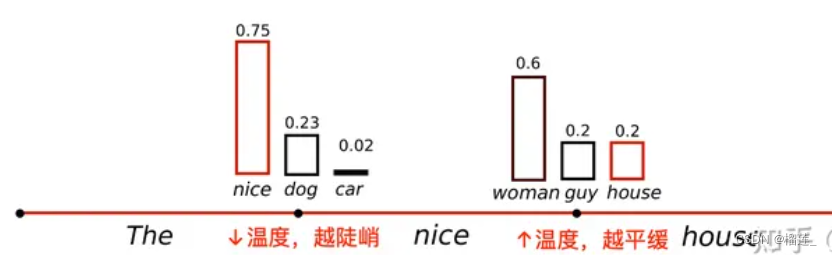
通常我们是将 top-k、top-p、Temperature 联合起来使用。使用的先后顺序是 top-k->top-p->Temperature。
我们还是以前面的例子为例。
首先我们设置 top-k = 3,表示保留概率最高的3个 token。这样就会保留女孩、鞋子、大象这3个 token。
女孩:0.664
鞋子:0.199
大象:0.105
接下来,我们可以使用 top-p 的方法,保留概率的累计和达到 0.8 的单词,也就是选取女孩和鞋子这两个 token。接着我们使用 Temperature = 0.7 进行归一化,变成:
女孩:0.660
鞋子:0.340
接着,我们可以从上述分布中进行随机采样,选取一个单词作为最终的生成结果。
以下是对大模型文本生成——解码策略(Top-k & Top-p & Temperature)的详细解释:
https://zhuanlan.zhihu.com/p/647813179
损失函数中温度的作用

BLIP2的细节。(BLIP为什么将训练分成两个阶段)
BLIP
从数据角度出发(Bootstrap)
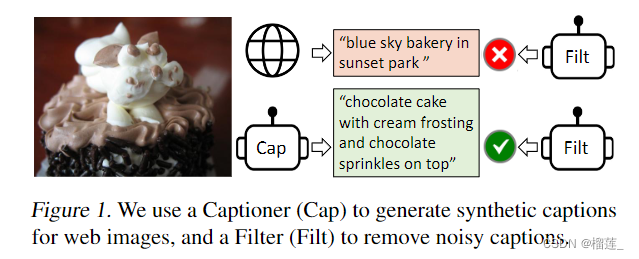
noisy data是suboptimal,如何clean noisy data,更好的利用图文对关系.noisy data是suboptimal,如何clean noisy data,更好的利用图文对关系
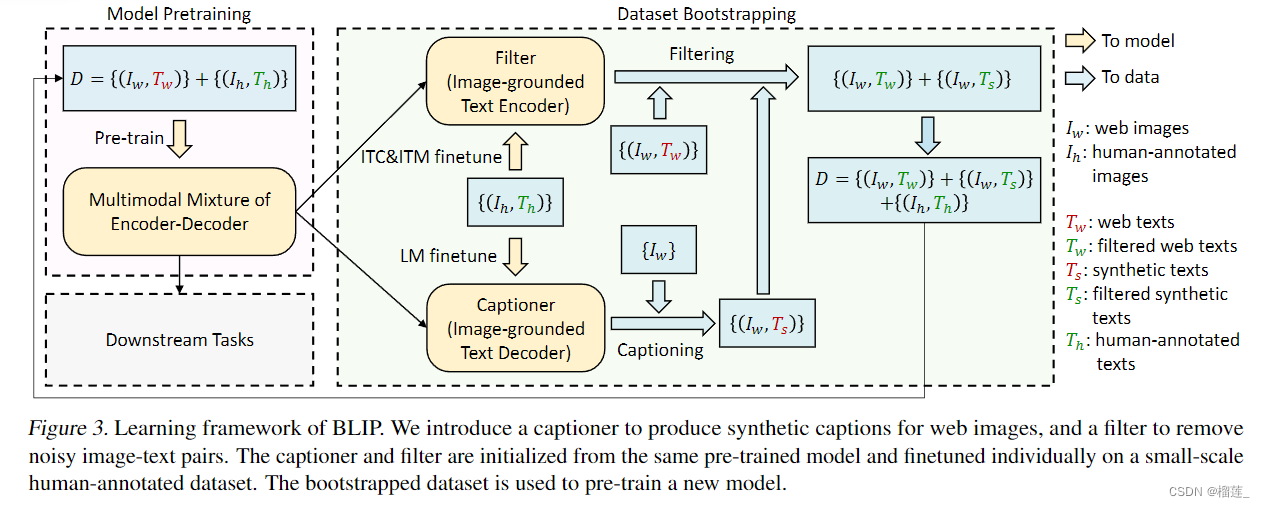
从模型角度出发(Unified)
现有模型无法直接应用到如text generation这类生成任务上
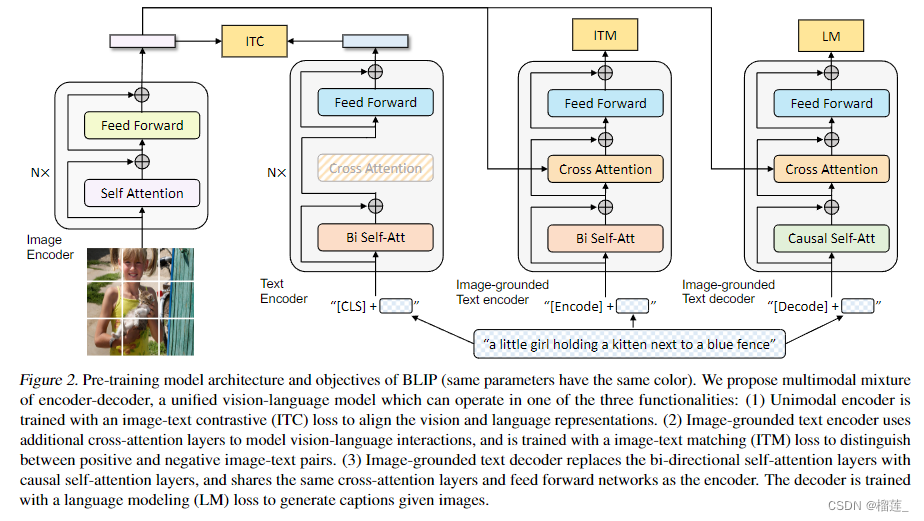
BLIP2
BLIP2的预训练任务分为两个阶段。
- 第一个阶段用于对齐多模态表征。 vision-language representation learning stage with a frozen image encoder。主要通过Image-Text Contrastive Loss (ITC)、 Image-text matching (ITM)、Image-grounded Text Generation3个任务的联合训练来实现。能够强制让 Q-Former 学习更和文本相关的视觉表达信息。
- 第二个阶段用于让LLM理解第一个阶段产生的soft visual prompt的语义,从而借助LLM强大的知识库实现视觉推理等更为复杂的任务,主要通过language modeling(LM)任务的训练来实现。具体来说,通过将 Q-Former 的输出和 frozen LLM 连接起来实现 vision-to-language 生成式学习,所要实现的目标是能用 LLM 来解释 Q-Former 的输出视觉表达特征
BLIP2的预训练任务同样用了BLIP提出的boostrapping caption(也称为CapFilt method)技术。
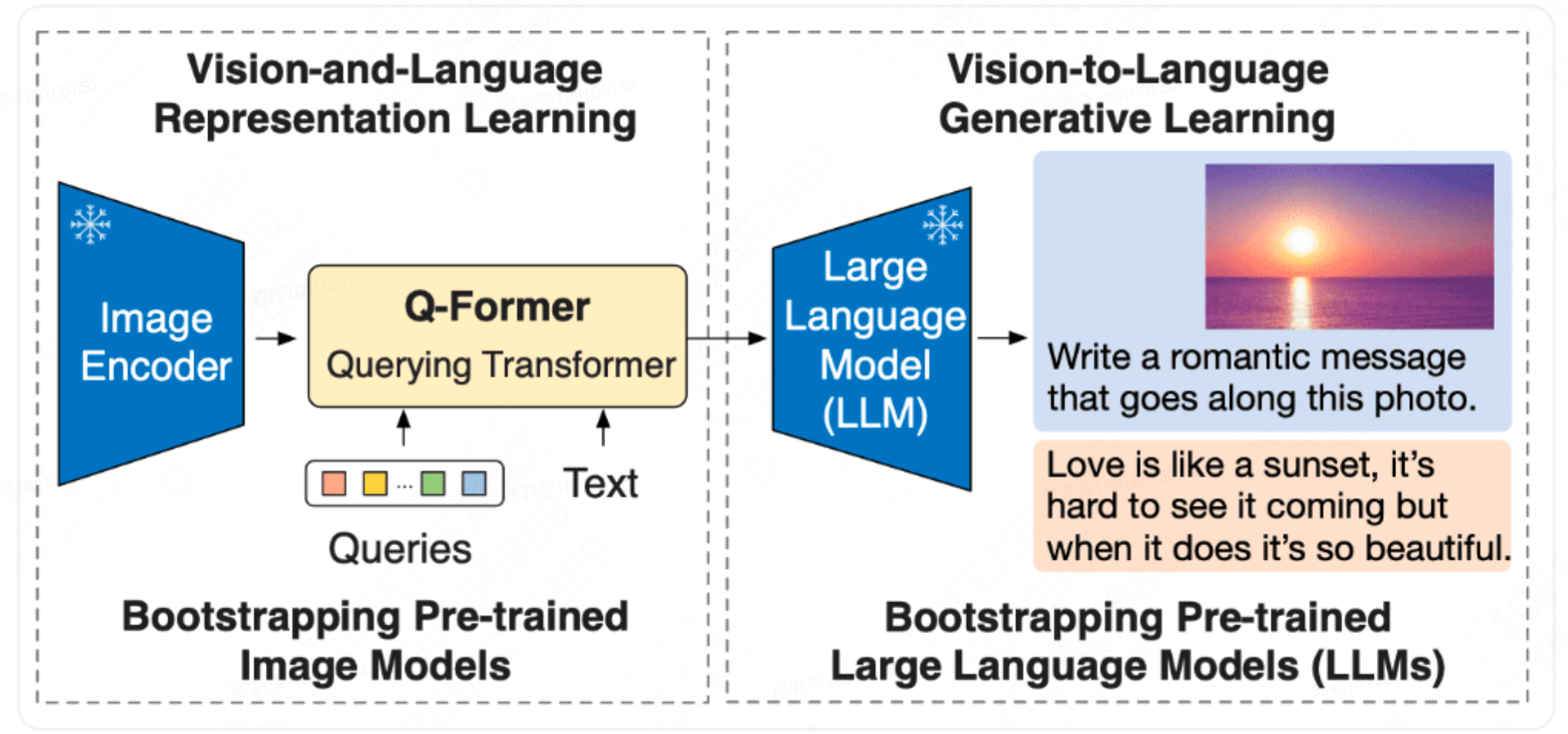
上图的两个虚线框分别代表两个阶段,其中的关键部分在于q-former。
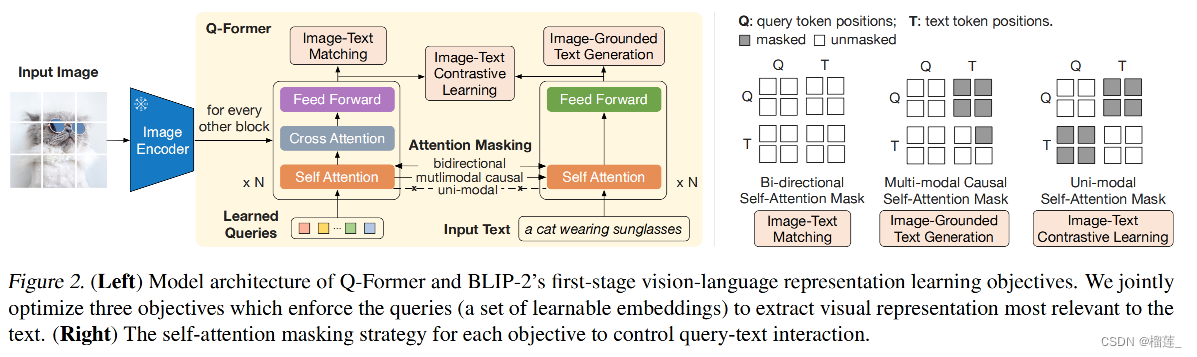
如上图所示,Q-Former 由两个 transformer 子模型组成,且两个子模型共享 self-attention layers:
image transformer:和 frozen image encoder 进行交互,来抽取视觉特征
text transformer:同时有 text encoder 和 text decoder 的作用
Q-Former 如何工作:
- 首先建立一组可学习的 query embedding 作为 image transformer 的输入
- queries 之间会通过 self-attention layer 和 text 进行交互,也能通过 cross-attention 和 frozen image feature 进行交互
- 基于不同的预训练任务, 作者会使用不同的 self-attention mask 来控制 query-text 之间的交互
- Q-Former 使用 BERT_base 进行初始化,cross-attention layers 的参数是随机初始化的
- Q-Former 共包含 188M 参数
- 在实验中,作者使用了 32 queries,每个 query 有 768 维,使用 Z Z Z 来定义输出 query representation, Z Z Z ( 32 × 768 ) 的尺寸远远小于 frozen image feature 的尺寸(ViT-L/14 是 256x1024)
- 该结构能够和目标函数一起促进 query 来提取更和 text 相关的视觉信息
多模态表征对齐预训练 (第一阶段)
主要通过ITC、ITM, ITG三个预训练任务来对齐QFormer产生的文本表征与图片表征。三个预训练任务联合优化。
Image-Text Contrastive Loss (ITC)
与常规ITC任务不同的是:单个图片BLIP2产生的image embedding有32个(等于learned query的数量),而text embedding只有1个。BLIP2的操作是,同时计算32个image embedding与text embedding的距离,仅取最近的计算loss。
下图详细梳理了整体pipeline及对应的shape变化(忽略了batchsize)
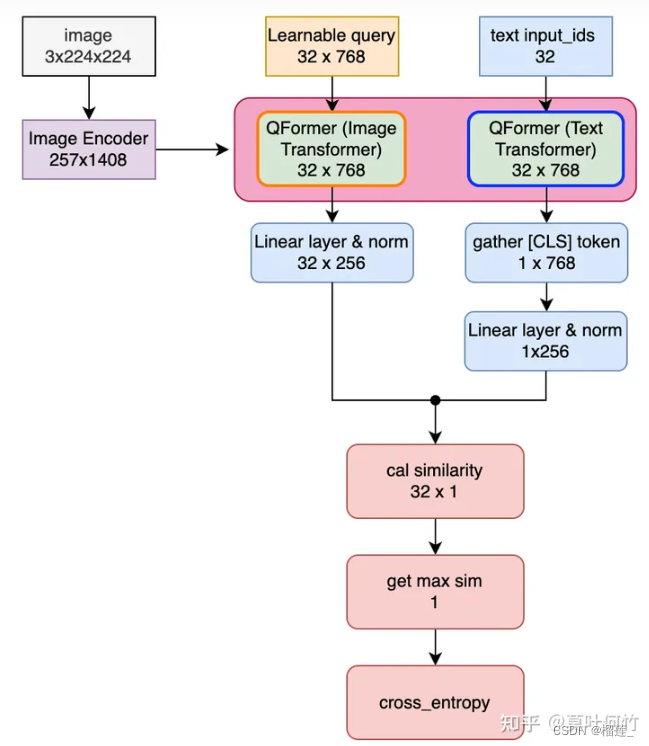
Image-text matching (ITM)
图片匹配的整体架构如下图所示。此时会将query embedding与text embedding拼接起来作为输入,送入到QFormer中的Image Transformer中。最后对Qformer在query embedding位置的输出向量取平均后进行预测。下图中详细展示了整体pipeline与shape变化(包含batch size维度)。
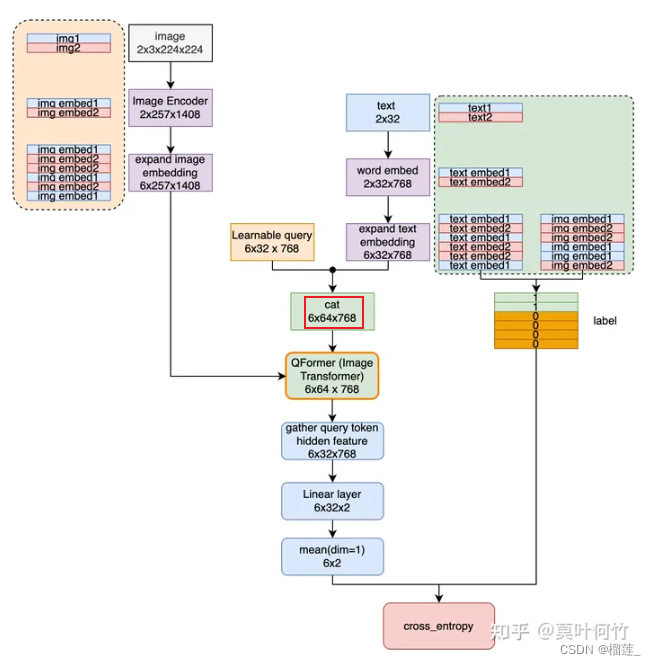
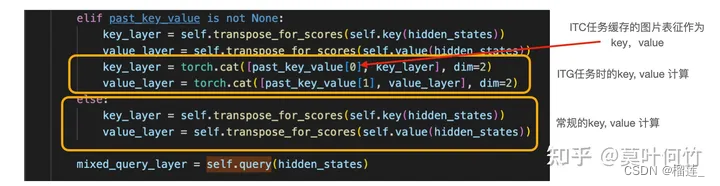
Image-grounded Text Generation (ITG)
此处直接用QFormer的text transformer做image caption任务。有一个细节值得注意:作者将图片与文本表征的交互放到了self-attention中。下图是摘取的部分self-attention层代码。
多模态表征理解预训练(第二阶段)
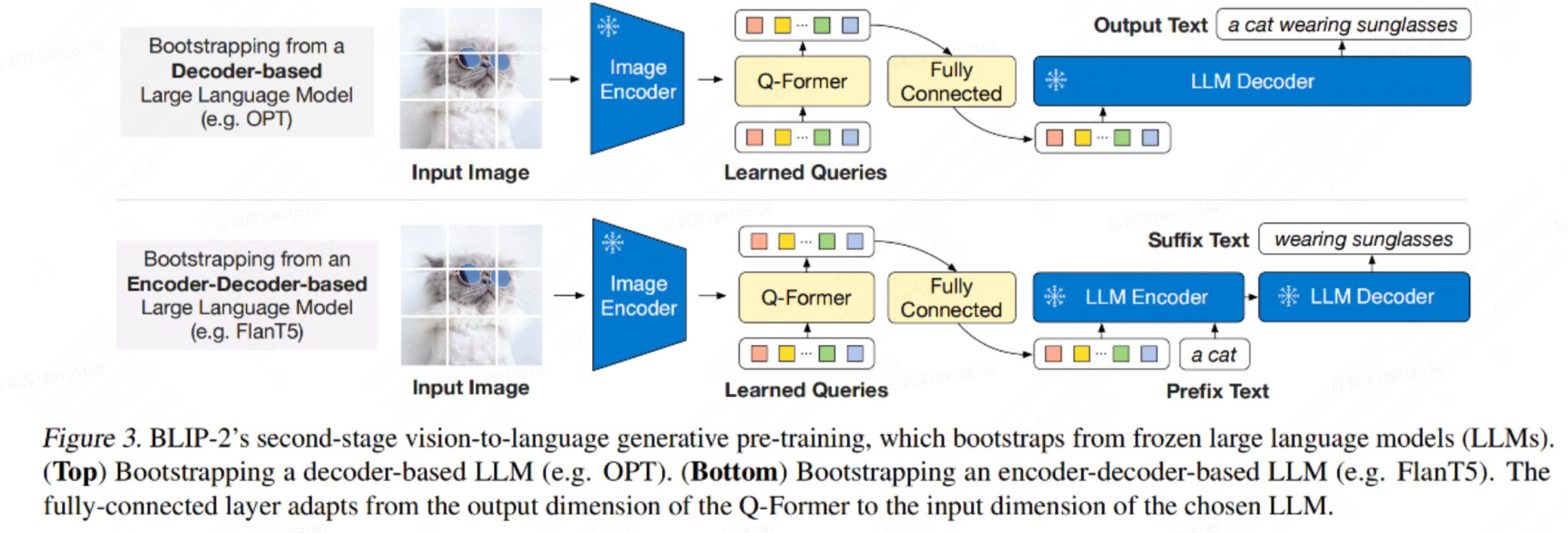
上面我们得到一个训练好的QFormer,这个QFormer能够实现将图片转为一个32x768(用32个token来表征图像)。第二阶段的任务是让预训练的LLM模型能够理解上述的图片表征,从而借助LLM强大的知识库来实现问答、推理等任务。也就是说,这一阶段我们需要通过训练来赋予图片token能被LLM理解的语义。
这里作者针对两类不同LLM设计了不同的任务:
- Decoder类型的LLM(如OPT):以Query做输入,文本做目标;
- Encoder-Decoder类型的LLM(如FlanT5):以Query和一句话的前半段做输入,以后半段做目标;
为了适合各模型不同的Embedding维度,作者引入了一个FC层做维度变换。
这一步的训练比较简单。固定image encoder与预训练的LLM模型,仅训练QFormer和新增的一个投影层。训练任务为language modeling。最终实现QFormer输出的图片表征(论文称之为soft visual prompt)变成LLM能看懂的样子。
Visual Encoder有哪些常见的类型
“Visual Encoder” 是指将视觉输入(如图像)转换为表示向量或特征的模型或模块。不同的任务和架构可能使用不同类型的 Visual Encoder。以下是一些常见的 Visual Encoder 类型:
卷积神经网络(CNN):
CNNs 是处理图像数据的常见选择。它们使用卷积层来提取图像的局部特征,并通过池化层减少维度,最终生成图像的表示。
常见的 CNN 架构包括 AlexNet、VGGNet、GoogLeNet、ResNet 等。
预训练的卷积神经网络(Pre-trained CNNs):
利用在大规模图像数据上预训练的 CNN 模型,例如 ImageNet 上训练的模型。这些模型可以通过迁移学习用于其他视觉任务。
常见的预训练模型包括 ResNet、VGG、Inception、MobileNet 等。
循环神经网络(RNN)和长短时记忆网络(LSTM):
RNNs 和 LSTMs 被用于处理序列数据,例如图像的像素序列。它们可以捕捉序列中的上下文信息。
在图像领域,LSTMs 通常用于处理图像的不同区域或生成图像描述。
自注意力模型(Self-Attention Models):
自注意力模型,例如 Transformer 模型,已在自然语言处理中取得巨大成功,近年来也在视觉领域得到广泛应用。
这些模型使用自注意力机制来捕捉输入序列中不同位置之间的关联。
视觉-语言编码器(Vision-Language Encoders):
用于视觉与语言任务的编码器,例如将图像和文本信息映射到共享的表示空间。这在视觉问答(Visual Question Answering)等任务中很常见。
常见的架构包括图像和文本的双塔结构、BERT-like 模型等。
生成对抗网络(Generative Adversarial Networks,GANs):
GANs 可以通过生成器网络捕捉图像的潜在表示。这在图像生成、风格转换等任务中很有用。
大模型中常见的visual encoder
主要包括3种类型。第一种类型为使用object detection模型(一般为Faster R-CNN)识别图像中的目标区域,并生成每个目标区域的特征表示,输入到后续模型中。例如下图是Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training(AAAI 2020)中的一个例子,对图中的各个目标region识别后生成表示,融入到主模型Bert中。第二种方式是利用CNN模型提取grid feature作为图像侧输入。第三种方式是ViT采用的将图像分解成patch,每个patch生成embedding输入到模型中。随着Vision-Transformer的发展,第三种方式逐渐成为主流方法。本文主要研究的Visual Encoder是第三种,相比前两种方式运行效率更高,不需要依赖object detection模块或前置的CNN特征提取模块。
https://blog.csdn.net/qq_43687860/article/details/132735983
深度学习中常用的优化器有哪些?
BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam
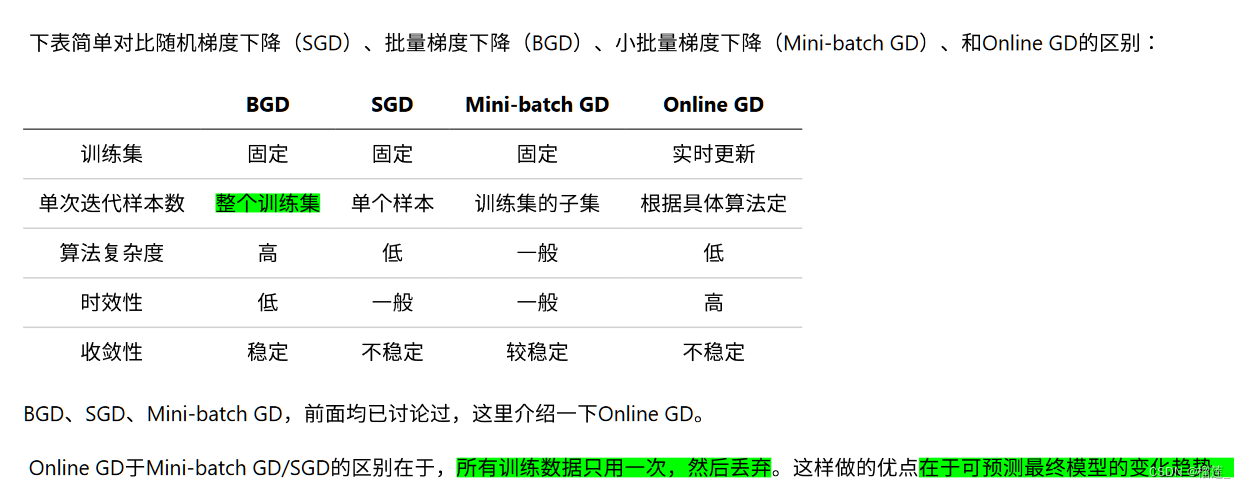

事实上,使用梯度下降进行优化,是几乎所有优化器的核心思想。当我们下山时,有两个方面是我们最关心的:
- 首先是优化方向,决定“前进的方向是否正确”,在优化器中反映为梯度或动量。
- 其次是步长,决定“每一步迈多远”,在优化器中反映为学习率。
SimCSE的了解
句向量表征技术一直都是NLP领域的热门话题,在BERT前时代,一般都采用word2vec训练出的word-embedding结合pooling策略进行句向量表征,或者在有训练数据情况下,采用TextCNN/BiLSTM结合Siamese network策略进行句向量表征。在BERT时代,人们借助预训练语言模型的固有优势,一般采用BERT模型的[CLS]向量(即句子的起始字符向量)作为句向量表征;SimCSE采用对比学习的方法,进行句向量表征,在BERT模型上获取更好的句向量表征,详细介绍如下:
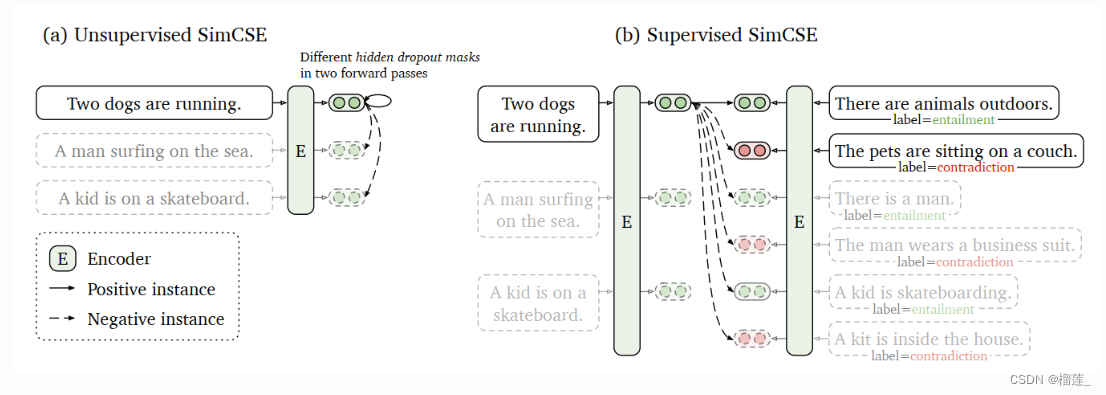
SimCSE(simple contrastive sentence embedding framework),即简单的对比句向量表征框架。SimCSE共包含了无监督和有监督的两种方法。
- 无监督方法,采用dropout技术,对原始文本进行数据增强,从而构造出正样本,用于后续对比学习训练;
- 监督学习方法,借助于文本蕴含(自然语言推理)数据集,将蕴涵-pair作为正例,矛盾-pair作为难负例,用于后续对比学习训练。并且通过对比学习解决了预训练Embedding的各向异性问题,使其空间分布更均匀,当有监督数据可用时,可以使正样本直接更紧密。模型结构如下图所示
Anisotropy
在这里作者还对最近提出的文本表示各向异性的现象做出了说明,总体来说就是由于各向异性的存在导致了文本表示能力大打折扣。前面提到的flow和whitening都是采用后处理的方式将数据分布变成各向同性的。而本文则是使用了对比学习来保证正例间的相似以及负例间的疏远,从而解决了文本表示退化的问题。文中有详细的公式推导以及证明,感兴趣的大家可以自己去看。
prenorm和postnorm
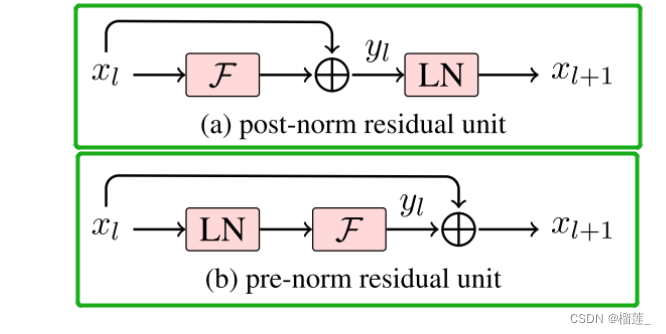
两者的主要区别在于归一化的时机。Prenorm 在权重和激活函数之前进行,而 Postnorm 在权重和激活函数之后进行。这个选择可能会对模型的训练和性能产生一些影响,而具体的效果通常要取决于具体的问题和架构。在实际应用中,研究人员和从业者可能会根据具体的实验结果选择适合其任务的归一化位置。
post-norm和pre-norm其实各有优势,post-norm在残差之后做归一化,对参数正则化的效果更强,进而模型的鲁棒性也会更好;pre-norm相对于post-norm,因为有一部分参数直接加在了后面,不需要对这部分参数进行正则化,正好可以防止模型的梯度爆炸或者梯度消失,因此,这里笔者可以得出的一个结论是如果层数少post-norm的效果其实要好一些,如果要把层数加大,为了保证模型的训练,pre-norm显然更好一些。
在大语言模型(Large Language Models)中,Layer Norm(层归一化)可以应用在不同位置,包括输入层、输出层和中间隐藏层。这些位置的归一化有一些区别:
输入层归一化:在输入层应用 Layer Norm 可以将输入的特征进行归一化,使得输入数据的分布更加稳定。这有助于减少不同样本之间的分布差异,提高模型的泛化能力。
输出层归一化:在输出层应用 Layer Norm 可以将输出结果进行归一化,使得输出结果的分布更加稳定。这有助于减小输出结果的方差,提高模型的稳定性和预测准确性。
中间隐藏层归一化:在中间隐藏层应用 Layer Norm 可以在每个隐藏层之间进行归一化操作,有助于解决深度神经网络中的梯度消失和梯度爆炸问题。通过减小输入数据的分布差异,Layer Norm 可以使得梯度更加稳定,并加速模型的收敛速度。
总的来说,Layer Norm 在大语言模型中的不同位置应用可以解决不同的问题。输入层归一化可以提高模型的泛化能力,输出层归一化可以提高模型的稳定性和预测准确性,而中间隐藏层归一化可以改善梯度传播,加速模型的收敛速度。具体应用 Layer Norm 的位置需要根据具体任务和模型的需求进行选择。
- LLaMA 2的创新/ChatGLM的创新点/Qwen的创新点/Baichuan的创新点
- LLM的评估方式有哪些?特点是什么?(中文的呢?)
- 文本生成模型中生成参数的作用(temperature,top p, top k,num beams)
- LoRA的作用和原理
- CoT的作用
- 神经网络经典的激活函数以及它们的优缺点
- softmax函数求导的推导
- BERT的参数量如何计算?
- AUC和ROC
- batch norm和layer norm
- 大模型训练的超参数设置
- 经典的词向量模型有哪些?
- InstructGPT三个阶段的训练过程,用语言描述出来(过程,损失函数)
- 大模型推理加速的方法
- Transformer中注意力的作用是什么
- RNN、CNN和Transformer的比较(复杂度,特点,适用范围etc)
- AC自动机
- 产生梯度消失问题的原因有哪些?
- 大模型的幻觉问题
- 大模型训练数据处理
- RLHF的计算细节
- 构建CoT样本的时候,怎么保证覆盖不同的场景?
- 召回的三个指标:Recall、NDCG、RMSE
- RoPE和ALiBi
- 交叉熵、NCE和InfoNCE的区别和联系
- 贝叶斯学派和概率学派的区别
- 一个文件的大小超过了主存容量,如何对这个文件进行排序?应该使用什么算法?
- Python中的线程、进程和协程
- python中的生成器和迭代器
表示学习中的7大损失函数梳理
这篇文章总结了表示学习中的7大损失函数的发展历程,以及它们演进过程中的设计思路,主要包括contrastive loss、triplet loss、n-pair loss、infoNce loss、focal loss、GHM loss、circle loss。
从零训练大模型教程
-
Tokenizer Training:tokenizer 有 2 种常用形式:WordPiece 和 BPE。可视化工具:tokenizer viewer。WordPiece 很好理解,就是将所有的「常用字」和「常用词」都存到词表中,需要切词的时候从词表查找即可。缺点:会出现OOV的现象。BPE:BPE 不是按照中文字词为最小单位,而是按照 unicode 编码 作为最小粒度。
-
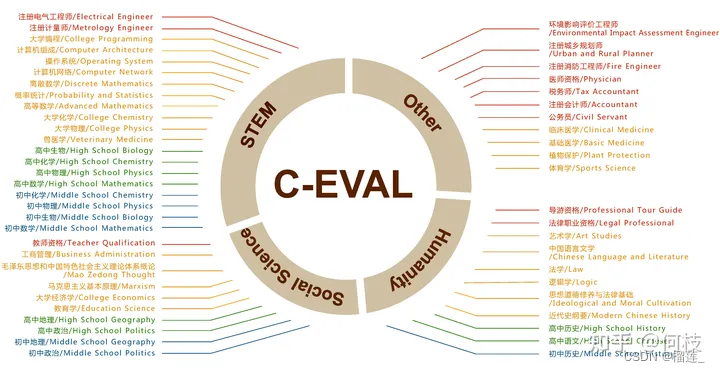
Language Model PreTraining:数据源采样,通过「数据源」采样的方式,能够缓解模型在训练的时候受到「数据集规模大小」的影响。数据预处理:我们通常会直接使用 truncation 将超过阈值(2048)的文本给截断,但是会造成数据浪费,因此最好是将长文章按照 seq_len(2048)作分割,将切割后的向量喂给模型做训练。模型结构:通常会在 decoder 模型中加入一些 tricks 来缩短模型训练周期。目前大部分加速 tricks 都集中在 Attention 计算上(如:MQA 和 Flash Attention [falcon] 等);通常也会在 Position Embedding 上进行些处理,选用 ALiBi([Bloom])或 RoPE([GLM-130B])等。模型效果评测:关于 Language Modeling 的量化指标,较为普遍的有 [PPL],[BPC] 等,即生成结果和目标文本之间的 Cross Entropy Loss 。大部分 LLM 都具备生成流畅和通顺语句能力,很难比较哪个好,哪个更好。为此,我们需要能够评估另外一个大模型的重要能力 —— 知识蕴含能力。C-Eval涵盖1.4w 道选择题,共 52 个学科。
-
指令微调阶段:作用是指令对齐,self-instruction细节:如Alpaca 则是使用「种子指令(seed)」,使得 ChatGPT 既生成「问题」又生成「答案」。Alpaca(英文)生成了5200条指令,Alpaca的任务涵盖如下。BELLE(中文)开放了好几种规模的数据集,[100万]、[200万]、[350万] 等。
-
模型的评测方法:不同于BLEU 和 ROUGH,可以使用GPT4进行打分
评测集:C-Eval,open_llm_leaderboard
一文串起从NLP到CV 预训练技术和范式演进
https://mp.weixin.qq.com/s/o8xxsUcMC6fnHUCcw60K2A
笔记
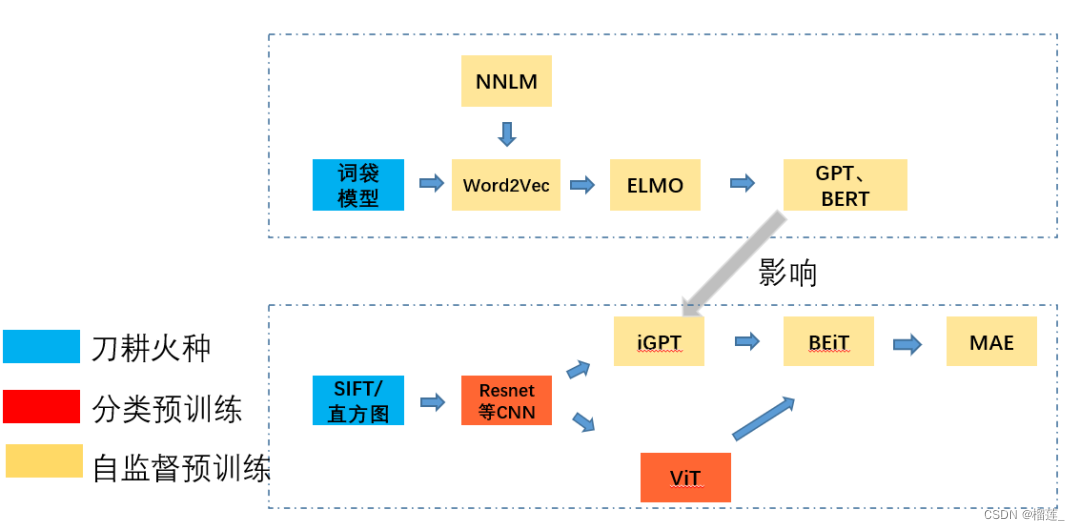
预训练技术的发展,目标都是围绕怎么得到一个好的语义表征。
NLP领域
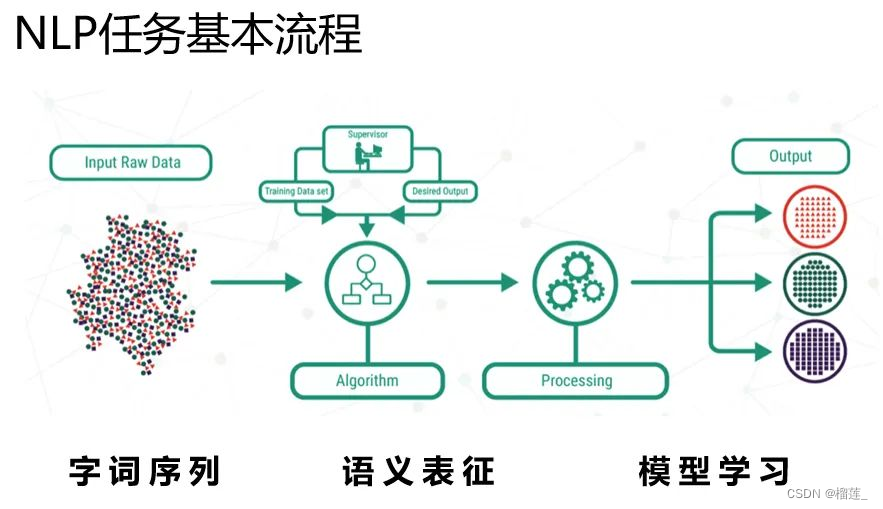
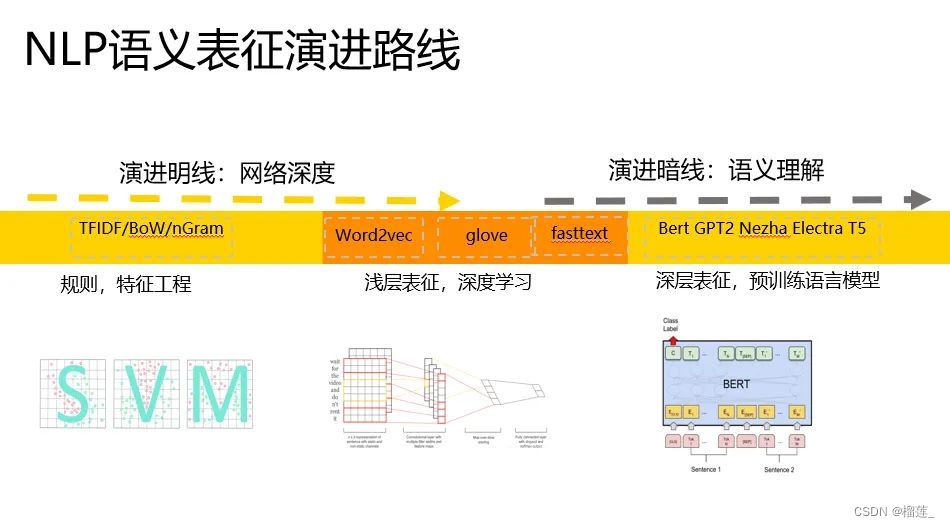
我们粗略的可以把语义表征的计算分为三个阶段,分别是:
一、特征工程阶段,以词袋模型为典型代表。
二、浅层表证阶段,以word2vec为典型代表。
三、深层表征阶段,以基于transformer的Bert为典型代表。
trick
PPO trick:https://zhuanlan.zhihu.com/p/512327050
混合精度:https://www.mindspore.cn/tutorials/experts/zh-CN/r1.7/others/mixed_precision.html
梯度截断:https://blog.csdn.net/csnc007/article/details/97804398
预训练新范式提示学习(Prompt-tuning,Prefix-tuning,P-tuning,PPT,SPoT):https://blog.csdn.net/qq_39388410/article/details/121036309
前沿技术
LaMMA和LLaMA-2的区别
主要是数据层面和模型层面进行了修改:
数据层面
更强大的数据清洗:语料库包括来自公开可用来源的新数据混合,不包括 Meta 的产品或服务的数据。已从某些已知包含大量个人信息的网站中删除数据。
总token数量增加了40%:训练使用了2 万亿个token的数据,这在性能和成本之间提供了良好的平衡,通过对最真实的来源进行过采样,以增加知识并减少幻觉。
加倍上下文长度:更长的上下文窗口使模型能够处理更多信息,这对于支持聊天应用中的更长历史记录、各种摘要任务和理解更长文档特别有用。
模型层面
Grouped-query attention (GQA):这是一种方法,允许在多头注意力(MHA)模型中共享键和值投影,从而减少与缓存相关的内存成本。通过使用 GQA,更大的模型可以在优化内存使用的同时保持性能。
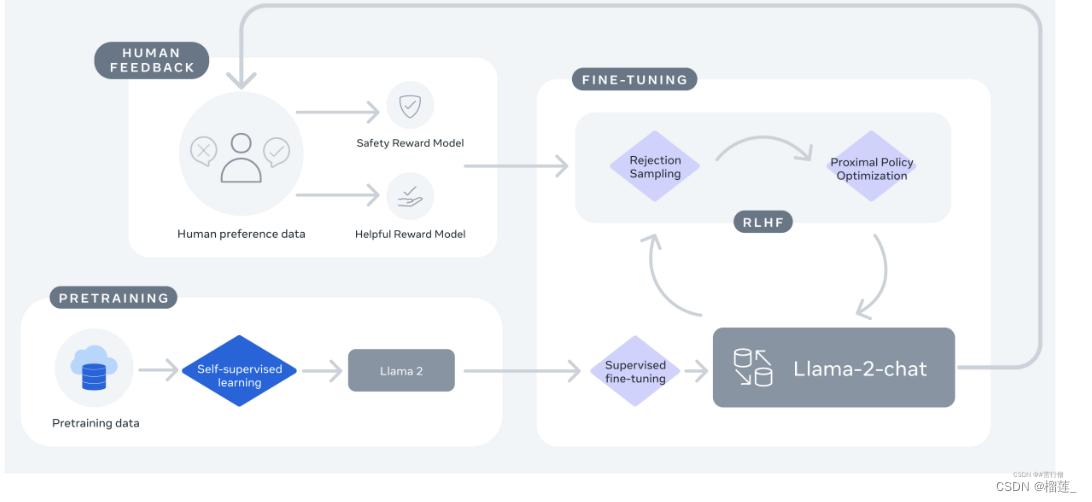
训练出了chat版本:llama-2-chat:SFT, RLHF。
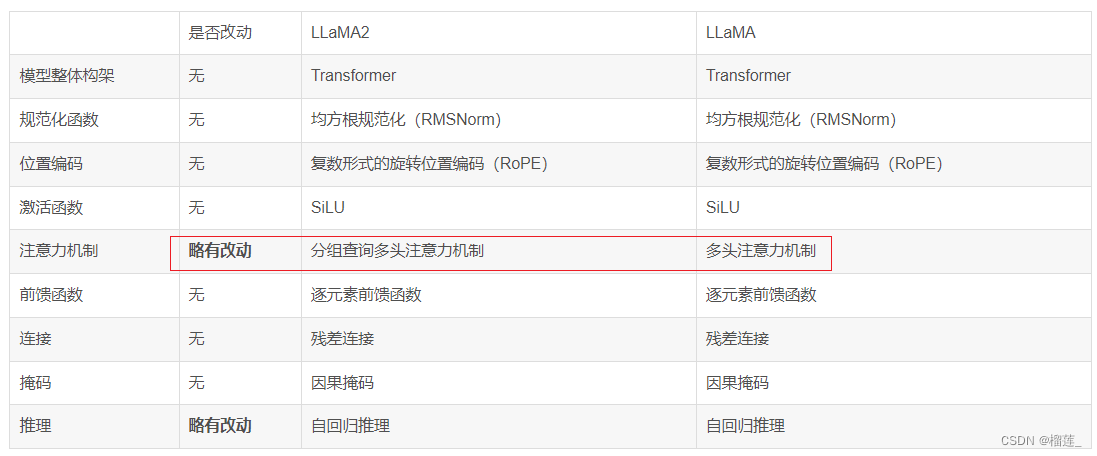
MHA, MQA, GQA区别与联系
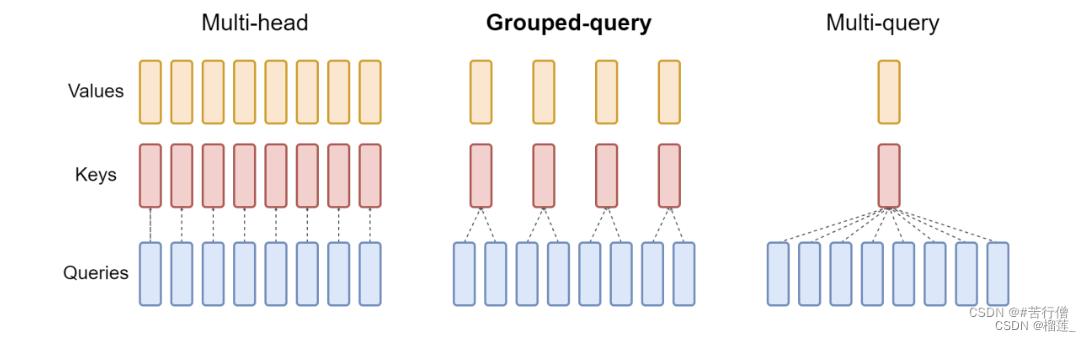
MHA(Multi-head Attention)是标准的多头注意力机制,h个Query、Key 和 Value 矩阵。
MQA(Multi-Query Attention,Fast Transformer Decoding: One Write-Head is All You Need)是多查询注意力的一种变体,也是用于自回归解码的一种注意力机制。与MHA不同的是,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。【论文:https://arxiv.org/pdf/1911.02150.pdf】
GQA(Grouped-Query Attention,GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints)是分组查询注意力,GQA将查询头分成G组,每个组共享一个Key 和 Value 矩阵。GQA-G是指具有G组的grouped-query attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。【论文:https://arxiv.org/pdf/2305.13245v1.pdf】

















 1209
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









