







最后一个编程作业了,依旧是用2020的代码。
Generative_Adversarial_Networks_PyTorch.ipynb
预备知识
之前的作业几乎都算是分类模型(生成图像描述也算一个分类问题,每个单词算一个类)。接下来要构建一个生成模型(GAN),它能生成类似于训练集的图片。
什么是GAN?
在2014年,Goodfellow et al.提出了GAN模型。它包含两个不同的神经网络:一个传统的分类网络——辨别器(𝐷),它把训练数据预测为真,非训练数据预测为假;另一个叫生成器(𝐺),输入随机噪声后它能生成新的图片。
优化问题如下所示:
最大最小后面的表达式衡量辨别器分类正确的能力(二分类问题损失函数乘以-1),生成器希望它生成的图片被判别器预测为真(也就是希望辨别器能力减弱,所以希望表达式最小化),而辨别器希望把生成器生成的图片识别出来(也就是希望能力增强,所以最大化表达式),在两者的对抗中,生成器学会了生成以假乱真的图片。
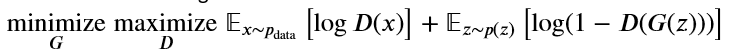
其中𝑥∼𝑝data是训练数据,𝑧∼𝑝(𝑧)是随机噪声,𝐺(𝑧)是生成的图片,𝐷(𝑥)表示𝑥是训练数据的概率。
但是最大化和最小化交替是一个很棘手的问题,下面是一个例子:
考虑𝑓(𝑥,𝑦)=𝑥𝑦,min𝑥max𝑦𝑓(𝑥,𝑦) ,现在从(1,1)点开始,更新𝑥,𝑦:
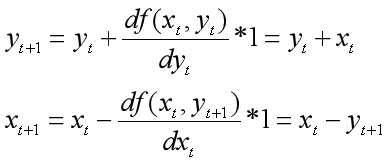
其中1代表学习率。
经过6步最大最小化梯度更新,发现又回到了(1,1)点:
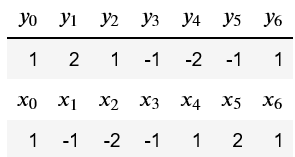
所以要对上面的公式进行稍微的修改,把生成器的最小化改为最大化:
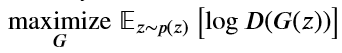
辨别器的优化问题不变:
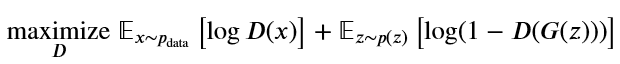
自从2014GAN出现以来,有非常多的新文章出现。相对于其他生成模型,GAN能生成最高质量的图片,但是也是最难训练的模型,这里有17个技巧使GAN运行良好。
这里有关于GAN的教程,最近的 WGAN, WGAN-GP把目标函数换成Wasserstein距离(推土机距离),使GAN能产生更稳定的结果。
下面是本次作业的官方结果,自己运行的结果可能没有这么好:

GAN不是唯一的生成模型,更多的生成模型可以看这里和花书里的介绍。
另一个比较流行的使用神经网络作为生成模型的方法是变分自编码(看这里和这里),变分自编码更稳定和更容易训练,但是现在还不能产生和GAN一样好的结果。
预处理
import torch
import torch.nn as nn
from torch.nn import init
import torchvision
import torchvision.transforms as T
import torch.optim as optim
from torch.utils.data import DataLoader
from torch.utils.data import sampler
import torchvision.datasets as dset
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # 默认画图大小
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# 自动重新加载额外的文件
%load_ext autoreload
%autoreload 2
# 用于展示一个批量的训练数据
def show_images(images):
images = np.reshape(images, [images.shape[0], -1]) # 把图片拉伸为向量
# np.ceil()向上取整,但是输出为浮点数。计算每行展示多少张图片
sqrtn = int(np.ceil(np.sqrt(images.shape[0])))
# 每张图片的长和宽
sqrtimg = int(np.ceil(np.sqrt(images.shape[1])))
fig = plt.figure(figsize=(sqrtn, sqrtn))
gs = gridspec.GridSpec(sqrtn, sqrtn)
# 图像间的间隔大小
gs.update(wspace=0.05, hspace=0.05)
for i, img in enumerate(images):
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
plt.imshow(img.reshape([sqrtimg,sqrtimg]))
return
为GAN选择合适的超参数很难,GAN也需要训练非常多个epochs。为了使这次作业能够在没有GPU的环境下运行,官方选择使用MNIST手写数字数据集,它包含60,000 张训练图片和10,000张测试图片,这是最早用于CNN的数据集之一,使用CNN能够很容易达到99%以上的准确率。
Pytorch里封装有下载和加载MNIST数据集的方法,相关的接口可以查看文档,默认选取5,000张训练图片作为验证集,下载的数据会保存在./cs231n/datasets/MNIST_data文件夹下。
from cs231n.gan_pytorch import preprocess_img, deprocess_img, rel_error, count_params, ChunkSampler
# 保存一些正确的输出,用于检验代码是否正确
answers = dict(np.load('gan-checks-tf.npz'))
NUM_TRAIN = 50000
NUM_VAL = 5000
# 噪声的维度,噪声作为生成器的输入
NOISE_DIM = 96
batch_size = 128
mnist_train = dset.MNIST('./cs231n/datasets/MNIST_data', train=True, download=True,
transform=T.ToTensor())
loader_train = DataLoader(mnist_train, batch_size=batch_size,
sampler=ChunkSampler(NUM_TRAIN, 0))
mnist_val = dset.MNIST('./cs231n/datasets/MNIST_data', train=True, download=True,
transform=T.ToTensor())
loader_val = DataLoader(mnist_val, batch_size=batch_size,
sampler=ChunkSampler(NUM_VAL, NUM_TRAIN))
imgs = loader_train.__iter__().next()[0].view(batch_size, 784).numpy().squeeze()
show_images(imgs)
一个批量的训练图像(128张):

生成[-1,1]的随机均匀噪声,大小为[batch_size, NOISE_DIM]
提示:使用torch.rand()
# 确保噪声的大小和类型正确
from cs231n.gan_pytorch import sample_noise
def test_sample_noise():
batch_size = 3
dim = 4
torch.manual_seed(231)
z = sample_noise(batch_size, dim)
np_z = z.cpu().numpy()
assert np_z.shape == (batch_size, dim)
assert torch.is_tensor(z)
# 确保范围是[-1,1]
assert np.all(np_z >= -1.0) and np.all(np_z <= 1.0)
# torch.rand()生成的数据范围是[0,1),这不符合要求,还需要进一步处理
assert np.any(np_z < 0.0) and np.any(np_z  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7553
7553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









