







文章信息

摘要
研究了一致性正则化,一种广泛采用的半监督学习方法,如何帮助提高图神经网络的性能。我们重新讨论了图神经网络的两种一致性正则化方法。一种是简单的一致性正则化(SCR),另一种是平均-教师一致性正则化(MCR)。我们将一致性正则化方法与两种最先进的gnn结合起来,并在ogbn上进行了实验。
introduction
许多研究论文表明,在训练中使用带有少量标记数据的未标记数据可以提高模型的性能。由于图结构的特点,图的半监督学习一直是研究的热点。在训练阶段[20,25,32,34]中使用“伪标记”来利用未标记的节点,这可以看作是一致性正则化的一种特殊情况。其中,多阶段自我训练方法的表现最好。顾名思义,培训过程被分为几个阶段。在每个阶段的开始时,通过根据前一阶段的预测为未标记的节点分配伪标签来扩展训练集。该方法有效地利用了未标记节点的信息,从而获得了更好的性能。然而,多阶段的方法并不那么优雅,需要更多的训练时间。
采用了两种一致性正则化的方法。
其中一种方法被称为简单一致性正则化(SCR),通过最小化扰动预测之间的不一致。扰动预测可以通过数据增强或模型的随机性来获得。
另一种方法被称为利用师生范式的平均-教师一致性正则化(MCR)。对于MCR,我们遵循平均教师[26],我们通过计算学生和教师模型之间的一致性损失来指导模型的训练。教师模型的参数直接从学生模型的指数移动平均(EMA)权值推导出,没有额外的反向传播, 教师模型的参数将由学生模型进行更新
方法
1. 介绍GNN
本文从SAGN GAMLP出发
1.1 SAGN
邻接矩阵多次幂 计算出不同层X,通过mpl 特征转化,attention对角矩阵来 这个比SAGN 原文公式还要清楚


每层的对角阵:通过第一层和 每层的表征学到一个权重attention, 两个矩阵(query和key)的第i行分别乘一个参数向量得到 一个数字attention,相加再 非线性, 学得后归一化, 矩阵形式就是得到一个对角矩阵
1.2 GAMLP
和SAGN差不多,只是计算attention时候 key value不同,SAGN query都是0层,key是各k层单独的。GAMLP 提出了两种,一种是recursive attention 第k层的Zq= 前k-1层 embedding 相应的的attention之和。 第二种是jk-attention, 第k层的embedding是 共K层embedding拼后加mlp得到的。 每层的表征应该还是和第一层计算attention。

2. 损失:
分为监督的和无监督的,监督的是交叉熵,无监督的是 采用伪标签在未标记节点上计算损失。

3. 本文提出的 一致性正则
一致性正则化技术是在假设输入上的一个小的扰动不应该改变模型的输出的情况下发展起来的。这个想法的一个简单定义可以概括如下:(1)给定一个数据样本,基于该样本计算一组扰动预测;(2)最小化这些预测之间的分歧。扰动预测可以通过操纵输入(例如,数据增强)或向模型注入噪声(例如,退出)来获得。这个定义在MixMatch[3]和grand[9]中使用,我们称之为简单一致性正则化(SCR)
3.1
给定一个图𝐺=(V,E,𝑿),通过DropNode[9]和DropNodge[24]等图增强方法构建了一组𝐺的𝑆增强版本,用{˜𝐺𝑠=(V,˜E𝑠,˜𝑿𝑠)}𝑠𝑆=1,表示。请注意,在增强过程中,节点集没有变化。如第3.2节所述,使用神经网络𝑝𝜃将每个节点映射到一个类分布。我们将神经网络独立地应用于这些增广图上,从而得到每个节点𝑖的𝑆类分布。我们使用𝑝𝑌|𝑖,˜𝐺𝑠,𝜽来表示节点𝑖在第𝑠个增广图上的预测。无监督损失的设计是为了最小化这些预测之间的分歧:
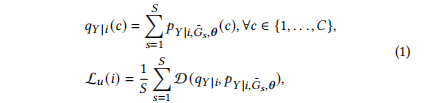
一个是 节点的预测标签,D是衡量两个分布的距离差值

3.2
在师生框架的基础上建立了平均教师一致性正则化(MCR)。在师生框架中有两个神经网络,即教师和学生。两者都可以被描述为一个函数,将V中的每个节点映射到前面描述的类分布。在这项工作中,教师和学生共享相同的架构,我们使用𝑝𝜽𝑡:V→R𝐶和𝑝𝜽𝑠:V→R𝐶来表示老师和学生,其中𝜽𝑡和𝜽𝑠是老师和学生的参数集。对于每个节点𝑖∈V,我们可以得到两个类分布,𝑝𝑌|𝑖,𝜽𝑡和𝑝𝑌|𝑖,𝜽𝑠。前者由老师预测,后者由学生预测。构建无监督损失是为了惩罚他们之间的分歧:
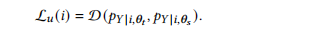
训练
培训阶段。我们遵循[26]中提出的训练策略来估计学生和教师的参数。在每个训练步骤中,我们随机选择一批节点,这是一个已标记节点和未标记节点的混合物。我们使用V𝐵𝐿⊆V𝐿和V𝐵𝑈⊆V𝑈来表示批处理中已标记节点和未标记节点的集合。标记节点由学生处理以构建监督损失,而未标记节点由教师网络和学生处理来构建无监督损失。该批次的损失函数可以表示为: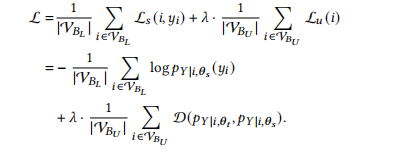
教师的参数通过指数移动平均(EMA)从学生的参数进行更新


实验---- ogb刷榜
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









